Digitale Barrierefreiheit
Die Barrierefreiheit von Webseiten ist tief im HTML-Standard verankert. Dennoch sind viele Webseiten für Menschen nicht nutzbar, wenn sie keine Standardhardware bedienen, nicht gut sehen, hören, komplexe Sachverhalte verstehen oder sich nicht gut konzentrieren können. Das sind viel mehr Nutzer:innen als landläufig angenommen. Bisher wurden Innovationszyklen von Webseiten vor allem visuell von Brandagenturen und Marketing oder durch technische Lösungen vorangetrieben, bei denen nur auf die „normalen“ Interaktionsmöglichkeiten Rücksicht genommen wurde. Da der Markt die Barrierefreiheit in 30 Jahren nicht vorangetrieben, sondern eher verhindert hat, sind in den USA und der EU die Gesetzgeber eingesprungen.
Der Stichtag ist der 28. Juni 2025 – das Datum liegt bei Erscheinen dieses Artikels noch knapp zwei Jahre in der Zukunft [1]. Ab diesem Tag müssen alle neu erstellten Webseiten barrierefrei sein, es sei denn, es handelt sich um ein Dienstleistungsangebot einer KMU mit weniger als 10 Mitarbeitenden und weniger als 2 Millionen Euro Jahresumsatz bzw. Jahresbilanzsumme. Für alle anderen Webseiten gilt eine Frist von 5 Jahren. Wenn in der Zwischenzeit das Angebot auf diesen Seiten verändert wird, gilt die Pflicht ab der Veröffentlichung dieser Veränderung. Alle anderen Seiten müssen ebenfalls bis zum 27. Juni 2030 barrierefrei überarbeitet werden [2]. Das will die EU mit der Richtlinie (EU) 2019/882 [3], auch EAA (European Accessibility Act) genannt, erreichen.
Warum wird digitale Barrierefreiheit zur Pflicht?
„Der Bedarf an barrierefreien Produkten und Dienstleistungen ist groß, und die Zahl der Menschen mit Behinderungen wird voraussichtlich noch deutlich steigen. Ein Umfeld mit besser zugänglichen Produkten und Dienstleistungen ermöglicht eine inklusivere Gesellschaft und erleichtert Menschen mit Behinderungen ein unabhängiges Leben. Dabei sollte berücksichtigt werden, dass in der Union mehr Frauen als Männer eine Behinderung haben.“ So heißt es im zweiten Absatz der aufgeführten Gründe, die der Richtlinie vorangestellt wurden.
Weiterhin geht es darum, dass der Flickenteppich an Richtlinien, die derzeit in den Mitgliedsstaaten gelten, vereinheitlicht werden soll. Dadurch soll es einfacher werden, Produkte innerhalb der EU grenzüberschreitend zu vermarkten. Es geht auf der einen Seite also darum, Menschen mit Behinderung bewusst an der digitalen Welt teilhaben zu lassen. Das ist gut, wichtig und mehr als überfällig. Begründet wird dies aber auch mit dem wirtschaftlichen Aspekt von größeren Zielgruppen und Märkten. Dabei gibt es drei Richtlinien:
- WCAG des W3C
- EN 301 549 der EU enthält viele der WCAG-Kriterien und ergänzt sie
- BITV enthält die Übertragung der EN 301 549 in deutsches Recht
WCAG
WCAG steht für „Web Content Accessibility Guidelines“. Version 2.1 [4] gilt seit dem 05.06.2018. Version 2.2 hat den Status „Candidate Recommendation Draft“ [5]. Die finale Version wird noch 2023 erwartet.
Die WCAG 2.1 [6] enthält 78 Erfolgskriterien, die vier Prinzipien zugeordnet und in drei Konformitätsstufen unterteilt sind. Level A ist das absolute Minimum, das erfüllt werden muss, Level AA ist der Standard und Level AAA betrifft nur bestimmte Inhalte, die nicht auf allen Seiten Anwendung finden.
In Tabelle 1 sehen Sie die Matrix, wie die Prinzipien und die Konformitätsstufen sich anhand der Quick-Referenz der WCAG 2.2 überschneiden [7].
| 4 Prinzipien | 14 Unterkapitel | 78 Erfolgskriterien | 3 Konformitätsstufen | ||
|---|---|---|---|---|---|
| A | AA | AAA | |||
| 1) perceivable/ wahrnehmbar | Textalternativen | 1 | 1 | – | – |
| zeitbasierte Medien | 9 | 4 | 1 | 4 | |
| anpassbar | 6 | 3 | 2 | 1 | |
| unterscheidbar | 13 | 2 | 7 | 4 | |
| wahrnehmbar gesamt | 29 | 10 | 10 | 9 | |
| 2) operable/ bedienbar | mit der Tastatur zugänglich | 4 | 3 | – | 1 |
| genug Zeit | 6 | 2 | – | 4 | |
| Krämpfe und physische Reaktionen | 3 | 1 | – | 2 | |
| navigierbar | 10 | 4 | 3 | 3 | |
| Eingabemodalitäten | 6 | 4 | – | 2 | |
| bedienbar gesamt | 29 | 14 | 3 | 12 | |
| 3) understandable/ verständlich | lesbar | 6 | 1 | 1 | 4 |
| vorhersagbar | 5 | 2 | 2 | 1 | |
| Eingabehilfen | 6 | 2 | 2 | 2 | |
| verständlich gesamt | 17 | 5 | 5 | 7 | |
| 4) robust* | kompatibel | 3 | 2 | 1 | – |
| robust gesamt | 3 | 2 | 1 | 0 | |
| Gesamt | 78 | 31 | 19 | 28 | |
| * robust: alle Inhalte müssen mit einer Vielzahl an Geräten und Browsern auch dann wahrnehmbar und bedienbar sein, wenn assistive Technologien, z. B. Screenreader, Braillezeilen, Bildschirmlupen, unterschiedliche Eingabemethoden (Maus/Touch/Fokus) genutzt werden. Außerdem gibt es unzählige adaptive Technologien/Einstellungsmöglichkeiten in Standardhardware, auf die dieser Grundsatz zutrifft. | |||||
Tabelle 1: Die WCAG-Erfolgskriterien mengenmäßig den Prinzipien und Konformitätsstufen zugeordnet
EN 301 549
EN steht für „Europäische Norm“. Die Nummer 301 549 enthält die „Accessibility requirements for ICT products and services“, die „Barrierefreiheitsanforderungen für IKT-Produkte und -Dienste“. IKT steht für Information- und Kommunikationstechnik. Version 3.2.1 gilt seit dem 21.05.2021.
BITV 2.0
BITV steht für „Barrierefreie-Informationstechnik-Verordnung“. Version 2.0 gilt seit dem 21.05.2019.
Die Prüfschritte der BITV 2.0 [8] orientieren sich an der EN 301 540 Version 3.1.1. und 3.2.1. Die Nummern von BITV-Prüfschritten, die auf der EN 301 549 basieren, sind weitgehend mit der Nummerierung dort identisch. Manche der EN-301-549-Prüfschritte werden in der BITV jedoch in mehrere Einzelschritte unterteilt.
Auf der Seite barrierefreiheit-dienstekonsolidierung.bund.de wird klargestellt: Die WCAG-Erfolgskriterien der Konformitätsstufen A und AA sind damit mit dem Standard EN 301 549 verbindlich einzuhalten. Die WCAG-Erfolgskriterien der Konformitätsstufe AAA werden im Standard EN 301 549 informatorisch beziehungsweise als erweiterte Kriterien aufgelistet, die nicht für alle Inhalte einer Webseite relevant sind (Tabelle 2) [9].
| Kapitel | Kriterien | EN 3.1.1 | EN 3.21 | WCAG 2.1 Level | ||
|---|---|---|---|---|---|---|
| A | AA | AAA | ||||
| 1. allgemeine Anforderungen | 3 | 3 | – | – | – | – |
| 2. Zwei-Wege-Sprachkommunikation | 16 | 14 | 2 | – | – | – |
| 3. Videofähigkeiten | 9 | 7 | 2 | – | – | – |
| 4. Textalternativen | 4 (1 nur BITV) | = | = | 3 | – | – |
| 5. zeitbasierte Medien | 5 (1 nur BITV) | = | = | 2 | 2 | – |
| 6. anpassbar | 12 | = | = | 10 | 2 | – |
| 7. unterscheidbar | 9 (1 A + AA) | = | = | 2 | 8 | – |
| 8. per Tastatur zugänglich | 3 | = | = | 3 | – | – |
| 9. ausreichend Zeit | 2 | = | = | 2 | – | – |
| 10. Anfälle | 1 (2*AAA extra) | = | = | 1 | – | (2) |
| 11. navigierbar | 7 | = | = | 5 | 2 | – |
| 12. Eingabemodalitäten | 4 | = | = | 4 | – | – |
| 13. lesbar | 2 | = | = | 1 | 1 | – |
| 14. vorhersehbar | 4 | = | = | 2 | 2 | – |
| 15. Hilfestellung bei der Eingabe | 4 | = | = | 2 | 2 | – |
| 16. kompatibel | 3 | = | = | 2 | 1 | – |
| 17. benutzerdefinierte Einstellungen | 1 | 1 | = | – | – | – |
| 18. Autorenwerkzeuge | 4 | 4 | = | – | – | – |
| 19. Dokumentation und Support | 5 | 5 | = | – | – | – |
| Gesamt | 98 | 34 | 4 | 37 | 20 | (2) |
Tabelle 2: Die BITV-Prüfkriterien mengenmäßig den Kapiteln und den EN-301-549- und WCAG-Konformitätsstufen zugeordnet
Die EN 301 549 und die BITV enthalten einige Punkte, die in der WCAG nicht enthalten sind und umgekehrt. Zum Beispiel fehlen in der BITV einige Punkte der WCAG zur Verständlichkeit. Diese wiederum sind in Leichter Sprache sehr wichtig (Kasten: „Beispiel Leichte Sprache“).
Beispiel Leichte Sprache
In Bezug auf die Leichte Sprache und wie diese generell gut für die Zielgruppe, aber auch grundsätzlich barrierefrei eingebunden werden kann, sind die Regeln nicht ausgereift. Die gesetzlichen Vorgaben dazu sind derart detailliert festgeschrieben, dass sie die allgemeine Barrierefreiheit im Web komplett torpedieren: „Texte werden linksbündig ausgerichtet. Jeder Satz beginnt mit einer neuen Zeile. Der Hintergrund ist hell und einfarbig.“
Das berücksichtigt weder den Bedarf nach Dark Mode, noch die Tatsache, dass von der Zielgruppe eher Smartphones als Computer für den Webzugang genutzt werden, auf denen die oft genutzten PDF-Dateien zu klein dargestellt und visuelle Einstellungen der Browser ignoriert werden.
Leider sind die BITV- und EN-301-549-Kriterien, die nicht in der WCAG auftauchen, keinen Konformitätsstufen zugeordnet. Dennoch gilt es, sie ebenfalls zu erfüllen, um den BITV-Test zu bestehen, sofern sie auf die jeweils geprüfte Seite anwendbar sind.
Sind Angebote, die nach der Prüfung barrierefrei sind, auch garantiert inklusiv?
Nein.
Zum einen entwickelt sich die Technik schneller weiter als es in Regulierungen fixiert werden kann. So sind z. B. automatische Anpassungen an Einstellungen der Nutzenden möglich, die von der WCAG auch in Version 2.2 noch nicht erfasst wurden, jedoch in der BITV als Prüfschritt 11.7 „Benutzerdefinierte Einstellungen“ [10] enthalten sind, leider ohne Konformitätsstufe. Zum anderen kommen auch immer wieder neue Erkenntnisse hinzu.
Ein paar Dinge sind aktuell weder gesetzlich gefordert noch automatisch anpassbar: Es gibt keine Vorgabe, dass alle aktiven Elemente mit nur einer ggf. in der Beweglichkeit stark eingeschränkten Hand vom Bildschirmrand aus gut erreichbar sein müssen.
Die Prüfschritte basieren oft auf einzelnen Einschränkungen. Die Anforderungen, die Mehrfachbehinderungen mit sich bringen, werden nicht durchgängig abgedeckt. So wird zwar berücksichtigt, dass Menschen, die weder sehen noch hören können, mit der Braillezeile auf Inhalte zugreifen können müssen. Aber dass das auch für Texte in Leichter Sprache gelten sollte, wird bisher nicht beachtet. Menschen, die gebärden und auf eine weniger komplexe oder stärker kontrastierte Gebärdensprache angewiesen sind, fallen gänzlich durchs Raster.
Auch was die Verständlichkeit von interaktiven Systemen allgemein betrifft, muss die Lücke zwischen Usability und Barrierefreiheit noch stärker erforscht werden.
Wie groß ist die Zielgruppe?
Die Schätzungen, wie viele Menschen mit einer permanenten Behinderung leben, gehen weit auseinander. Die meisten Zahlen liegen zwischen 10 und 15 Prozent der Weltbevölkerung, in Industrieländern mehr als in Entwicklungsländern. In den USA ging das CDC, das Centers for Disease Control and Prevention, kürzlich gar von 27 Prozent aus [11].
Nur 3-4 Prozent der Behinderungen sind angeboren. Alle anderen Behinderungen werden erst im Laufe des Lebens erworben bzw. treten erst später in Erscheinung. Dabei kann es sich um Unfälle, Krankheitsfolgen, Umwelteinflüsse und nicht zuletzt zunehmendes Alter handeln.
Das Statistische Bundesamt hat im Juni 2022 eine Quote von 9,4 Prozent veröffentlicht – als schwerbehindert gelten dabei „Personen, denen die Versorgungsämter einen Behinderungsgrad von mindestens 50 zuerkannt sowie einen gültigen Ausweis ausgehändigt haben.“ [12]. Genaue Zahlen sind das nicht. Das Beispiel Blindheit zeigt das Problem ganz gut: „Blinde und sehbehinderte Menschen werden in Deutschland nicht gezählt.“ [13].
Manchmal sind es auch nicht die primär anerkannten Behinderungen, die zu einer Einschränkung führen, die für die digitale Barrierefreiheit relevant ist. Auch Menschen mit kurzzeitigen Einschränkungen, zum Beispiel Verletzungen, die wieder komplett ausheilen, und Menschen die sich situativ in ihren Bewegungen, in ihrer Sicht, ihrer Hörfähigkeit oder anderweitig eingeschränkt sind, profitieren von Maßnahmen, die im Rahmen der digitalen Barrierefreiheit umgesetzt wurden.
Von einer (einheitlichen) Zielgruppe kann in diesem Zusammenhang also nicht gesprochen werden. Aber das ist sekundär. Die Vergangenheit zeigt immer wieder Beispiele, dass Erfindungen, die ursprünglich für Menschen mit bestimmten Behinderungen erfunden wurden, allen Menschen nutzen bzw. von vielen Menschen angenommen werden. Dieses Phänomen wird „Curb Cut Effect“ [14] genannt, weil abgesenkte Bordsteinkanten und großzügigere Bewegungsflächen im öffentlichen Raum allen Menschen zugutekommen, die sich dort bewegen. Barrierefreiheit, wenn sie gut umgesetzt wurde, ist für uns alle gut.
Was sind die häufigsten Barrieren im Web?
WebAIM („Web Accessibility In Mind“) ermittelt seit 2019 in der Studie „The WebAIM Million“ [15] jährlich, wie viele der Top-1 000 000-Webseiten Barrieren aufweisen und welche am häufigsten sind. 96,3 Prozent der untersuchten Seiten haben 2023 Probleme in der Barrierefreiheit aufgewiesen. Seit 2019 ist der Wert nur um 1,5 Prozent (von 97,8 Prozent) gesunken.
Hier die Top-6-Fehlerquellen, die auf den Seiten zu finden waren:
- 83,6 Prozent der Seiten hatten Schrift mit zu geringem Farbkontrast zum Hintergrund.
- 58,2 Prozent der Seiten enthielten Bilder ohne Alternativtexte, die den Inhalt beschreiben.
- 50,1 Prozent der Seiten enthielten „leere“ Links, die Icons darstellen, aber keinen Text.
- 45,9 Prozent der Seiten enthielten Eingabefelder, die nicht korrekt beschriftet waren.
- 27,5 Prozent der Seiten enthielten Buttons, die leer bzw. nicht korrekt beschriftet waren.
- 18,6 Prozent der Seiten haben keine korrekte Sprachauszeichnung enthalten.
Die genannten Fehlerquellen beziehen sich in erster Linie auf Fehler, die sich vor allem für Menschen negativ auswirken, die nicht über 100 Prozent Sehkraft verfügen. Barrieren für Nutzer:innen mit Behinderungen, die das Hören, kognitive oder psychische Fähigkeiten oder die Feinmotorik (diese Liste ließe sich fortsetzen) betreffen, tauchen in dieser Liste noch nicht mal auf.
Der Curb Cut Effect im Internet – angenehmere Nutzung für alle!
Die wirklich gute Nachricht ist, dass digitale Barrierefreiheit auch auf andere Aspekte des Internets einen guten Effekt hat. Da wäre zum Beispiel: Stress. Die Internetagentur Cyber Duck hat 2020 eine Studie mit 1 100 „gesunden“ User:innen durchgeführt, die alle nichts mit dem Erstellen von Webseiten zu tun und sich als souveräne Anwender:innen beschrieben haben [16]. Im Test wurde der Anstieg des systolischen Blutdrucks als Stressindikator gemessen, wenn die Testwebseiten bestimmte Probleme aufgewiesen haben. Diese lassen sich fast alle auch Barrierefreiheitskriterien zuordnen (Tabelle 3).
Ungewollte Wechselwirkungen mit anderen Themenbereichen
Generell ist bei der Barrierefreiheit oft des einen Freud des anderen Leid, wie Sie an den folgenden drei Beispielen sehen:
- Beispiel Schriftgröße: Es ist nicht einfach damit getan, die Schrift auf einer Webseite doppelt so groß wie üblich zu machen. Das würde vor allem für Menschen, die nur mühsam scrollen können, das Nutzungserlebnis verschlechtern, wenn sie gut sehen können oder gar kleine Schrift bevorzugen. Hier soll es aber auch vor allem um Wechselwirkungen mit Themenbereichen aus Sicht der Betreibenden gehen, denn manchmal geraten die einzelnen Themen miteinander in Konflikt.
- Beispiel SEO: Wenn man SEO-Alternativtexte von Bildern für das Ranking nutzen möchte, der SEO-Text aber für blinde Nutzer:innen keinen Informationswert [17] enthält, da sie eine objektive Beschreibung bevorzugen, gilt es abzuwägen, was wichtiger ist. Hier kann ggf. das HTML-Element <figure> weiterhelfen und die <figcaption> hinzugezogen werden, um Informationen für SEO einem Bild hinzuzufügen.
- Beispiel DSGVO/Cookie-Banner-Pflicht: Cookie-Banner nerven uns alle. Vor allem, wenn sie als Pop-up daherkommen, führen sie zu vermehrtem Stress. Für viele sind sie einfach lästig. Wer sich um die eigenen Daten sorgt, möchte oft nicht zustimmen und hat so manches verwirrende Interaktionsmuster gesehen, mit dem Nutzer:innen doch noch ein Einverständnis abgerungen werden soll. Abgesehen davon, dass hier oft schon sogenannte Dark Patterns, speziell das „Privacy Zuckering“ [18] zum Einsatz kommen, gibt es noch ganz konkrete Probleme mit der Barrierefreiheit, speziell mit der Tastaturnavigation. Da der Code für das Overlay oft am Ende der Seite eingebunden wird, müssen erst alle Links, die visuell hinter dem Overlay liegen, übersprungen werden, bis das Overlay erreicht wurde und durch Auswahl einer Option entfernt werden kann. Blinde Nutzer:innen können die Inhalte dabei normal vom Screenreader vorlesen lassen. Sehende Menschen, die nur die Tastaturnavigation nutzen können, können hingegen die Inhalte derweil nicht sehen. Egal wie sorgfältig vorher auf die Barrierefreiheit geachtet wurde: Einmal ein falsches Plug-in gewählt und schon ist die Seite wieder eine einzige Barriere.
Kann eine Webseite nachträglich barrierefrei gemacht werden?
Bedingt.
Es hängt vor allem davon ab, mit welcher Technik die Seite erstellt wurde. Am einfachsten ist es bei handgeschriebenen Seiten, die nicht von der Barrierefreiheit der verwendeten Frameworks abhängig sind. Webseiten, die auf Content-Management-Systemen wie WordPress aufgesetzt sind, werden immer nur so barrierefrei sein wie die verwendeten Themes und Plug-ins. Hier sind die Anbieter gefragt. Leider ist es möglich, ein gutes Level an Barrierefreiheit mit der Wahl eines einzigen falsch gewählten Plug-ins zurück auf komplett nicht barrierefrei zu setzen. Das gilt auch für nicht geprüfte Updates und insbesondere auch für Overlay-Tools.
Zum Beispiel mit einem Overlay-Tool?
Nein.
Overlay-Tools sind kein Garant für Barrierefreiheit! Oftmals können Overlay-Tools Seiten, die bereits recht barrierearm waren, sogar komplett unzugänglich machen, wie die Seite Overlay Factsheet zusammengestellt hat [19].
Außerdem kann es zusätzlich zu Verstößen gegen die DSGVO kommen, wenn das eingesetzte Tool Userdaten zum Beispiel außerhalb der EU sammelt.
Beispiel für einen misslungenen Einsatz eines Overlay-Tools
Eine Seite mit hektischen Videos erfüllt die Level-A-Kriterien BITV 9.2.2.2 „Bewegte Inhalte abschaltbar“ [20] und ggf. auch 9.2.3.1 „Verzicht auf Flackern“ [21] nicht, wenn es nicht pausierbar ist und darin Elemente häufiger als dreimal die Sekunde aufblitzen. Das kann für Menschen unangenehm werden, die durch Flackern ein Anfallrisiko haben. Aber auch Menschen mit Seheinschränkungen, Neurodivergenz und andere, die von Bewegungen stark abgelenkt werden, können damit Probleme haben. Es fällt ihnen schwer, den Link zum Öffnen des Overlays überhaupt zu identifizieren, um dort die Einstellung zu finden, die das Video pausiert.
Was genau ist ein Overlay-Tool und wie funktioniert es?
Ein Overlay-Tool verspricht, Webseiten dadurch barrierefrei zu machen, dass sie um Funktionen wie Schrift- und Farbeinstellungen ergänzt werden. Diese Einstellungen können teilweise in Profilen gespeichert werden. Problematisch ist vor allem, dass
- es sich um einen proprietären Ansatz handelt – welche Lösung eingebunden wird, ist vom Anbietenden abhängig, nicht von der Wahl der Nutzenden.
- weiterer Code übertragen und ausgeführt werden muss.
- ein zusätzlicher Log-in nötig ist.
- bestehende adaptive Einstellungen der Nutzer:innen ignoriert werden.
- die Overlays die Barrierefreiheit letztlich nicht garantieren können, sondern den Zugang eher erschweren.
Die Message hinter Overlay-Tools ist daher oft: „Wir wissen, dass unsere Website barrierefrei sein sollte, darum haben wir das Overlay eingebunden – aber eigentlich ist uns egal, ob sie wirklich für alle nutzbar ist.“ Besser:
- auf das Video verzichten
- das Video nicht automatisch starten lassen, vor allem nicht, wenn im Code nicht abgefragt wird, ob „Bewegungen reduzieren“ im Betriebssystem aktiviert wurde.
- ein Overlay-Tool nur dann ergänzend einsetzen, wenn alle automatischen Adaptionsmöglichkeiten ausgeschöpft wurden
Warum wurde meine Webseite nicht längst barrierefrei umgesetzt?
Im Idealfall werden Webseiten zum Zeitpunkt ihrer Erstellung zum dann gültigen Stand der Technik umgesetzt. Leider sehe ich auch noch über 13 Jahre nach der Veröffentlichung des Artikels „Responsive Web Design [22]“, dass neue Webseiten nicht responsiv umgesetzt werden und damit auf verschiedenen Geräten unbrauchbar sind.
Laut BITV verstoßen sie damit nicht nur gegen gängige Marktstandards, sondern auch gegen 9.1.4.10 „Inhalte brechen um“ [23] (AA) und 9.1.3.4 „Keine Beschränkung der Bildschirmausrichtung“ [24] (AA).
Dass das responsive Internet letztlich seinen Durchbruch hatte, lag nicht zuletzt daran, dass Google mobile Webseiten ab dem 21. April 2015 bei der mobilen Suche bevorzugt hat [15] und ab März 2021 auf Mobile-First-Index [26] umgestellt hat.
Aber das ist nur die Spitze des Eisbergs: Auf der einen Seite wurde das Studium von Medieninformatiker:innen durch die Einführung des Bachelors um ein Jahr verkürzt. Auf der anderen Seite kamen zusätzlich zu den Veränderungen der Standards von HTML und CSS auch jährlich neue Frameworks für CSS (z. B. Bootstrap, Tailwind) und JavaScript (z. B. jQuery) auf den Markt. Teilweise wurden sie sofort an den Hochschulen gelehrt, die Standards darüber vernachlässigt. Kompatibilität zwischen verschiedenen Browsern (Stichwort Vendor-Prefix, Modernizr) und immer neue gestalterische Ideen zu ermöglichen waren lange Zeit einfach schicker als die Berücksichtigung von Barrierefreiheitsprinzipien.
Was genau muss geändert werden?
Das kommt ganz auf Ihre Seite an. Manchmal sind es nur Kleinigkeiten, manchmal Kleinigkeiten, die sich läppern, teilweise lautet die Antwort „am besten neu kodieren“, manchmal aber auch „es muss alles ab dem Konzept neu“. Wie Sie das anfangen und auf welche Details geachtet werden muss, wird an dieser Stelle nach und nach Thema sein.
Wer soll das alles umsetzen?
Wir sind alle gefragt! Wir müssen die Menschen, mit denen wir zusammenarbeiten bzw. die wir beauftragen, zunächst für das Thema sensibilisieren. Dann müssen sich alle passend zu ihrer Rolle weiterbilden:
- Alle Rollen müssen sich mit den Prüfkriterien und den realen Anforderungen der digitalen Barrierefreiheit vertraut machen, um entsprechend darauf reagieren zu können. Es ist wichtig, dass dieses Thema nicht nur an einer Person im Team liegt, die dann immer nur sagen kann, was falsch ist.
- Product-Owner:innen müssen Barrierefreiheit mit in die Akzeptanzkriterien der User Stories aufnehmen, damit alle Teammitglieder das Thema immer berücksichtigen lernen.
- UX-Designer:innen müssen sich bewusst machen, welche Interaktionspatterns barrierefrei sind.
- UI-Designer:innen müssen nicht nur für unterschiedliche Bildschirmgrößen gestalten, sondern auch für unterschiedliche Größen der Schriften und Klickflächen, sowie für unterschiedliche Farbvarianten etc.
- Frontend-Entwickler:innen müssen sich präziser mit UX/UI-Designer:innen abstimmen, um sicherzustellen, ob die Übergabewerte korrekt sind und was bereits berücksichtigt wurde. Außerdem muss das bestehende Wissen um HTML-Elemente, Attribute, CSS-Properties und JavaScript-Methoden mit den Anforderungen der Barrierefreiheit abgeglichen werden. Nicht alle Methoden, die zwischendurch (inoffizieller) Industriestandard waren, können für barrierefreie Webseiten eingesetzt werden.
- Backend-Entwickler:innen müssen wissen, wie sie bestimmte Elemente verfügbar machen können. Zum Beispiel, damit Redakteur:innen nur eine H1 anlegen können oder Text, der fett dargestellt wird, nicht als <b>, sondern als <strong> ausgezeichnet wird. Schließlich heißt es in den BITV-Prüfkriterien: „Wenn es sich bei der zu testenden Webanwendung um ein Autorenwerkzeug handelt, soll die Anwendung die Erstellung von barrierefreien Dokumenten erlauben und den Nutzer dabei unterstützen.“ [27]
- SEO-Expert:innen müssen den Spagat zwischen barrierefreien und SEO-optimierten Titeln und Bildbeschreibungen im Alt-Text hinbekommen. An vielen Stellen können sie nun aber auch darauf verweisen, dass ihre Arbeit für SEO und Barrierefreiheit gut und wichtig ist.
- Redakteur:innen müssen lernen, Dokumente in Word und anderen Programmen so anzulegen, dass daraus barrierefreie PDFs erzeugt werden können. Sie müssen wissen, welche semantischen Auszeichnungsmöglichkeiten es gibt und sie konsequent anwenden. Außerdem benötigen Sie Kontakte zu Übersetzer:innen für Leichte Sprache und/oder einen Zugang zu entsprechender KI [28]. Gleiches gilt für Videos, die den Text in Deutsche Gebärdensprache (DGS) übersetzen, bzw. in die Gebärdensprachen der Zielländer. Auch hier sind KI-gestützte Avatare in der Vorbereitung, es gilt jedoch neben dem wirtschaftlichen Aspekt auch die Akzeptanz der Gebärdenden zu berücksichtigen, die dieser Technik 2023 noch ablehnend gegenüberstehen [29].
- Bildredakteur:innen müssen nicht nur lernen, Bilder nach deren inhaltlicher Verständlichkeit zu bewerten, sondern auch, wie Personen deutlicher hervorgehoben werden können und wie optimale Alt-Texte geschrieben werden. Diese konsequent auch für Social-Media-Bilder einzusetzen, muss zur Gewohnheit werden.
- Qualitätstester:innen müssen wissen, wie sie die unterschiedlichen Barrieren ausfindig machen können, um sie melden und die Korrektur prüfen zu können.
Nicht zu vernachlässigen ist eine Dokumentation der Maßnahmen, die getroffen wurden. Zum einen wird es ab 2025 im Rahmen der EAA für manche Seitentypen Pflicht sein, sie zu führen, zum anderen ermöglicht es Ihnen auch eine einfachere Übergabe von Projekten an andere oder neue Teammitglieder.
Shopify ist dies bereits einmal misslungen. Die Plattform wird in einem Artikel über aria-current als gutes Beispiel genannt, weil dort die aktuelle Seite in der Navigation korrekt als aria-current=“page“ [30] ausgezeichnet wurde. Dem ist inzwischen nicht mehr so. Nur noch die aktuell ausgewählte Sprache und Region wird im Footer mit aria-current=“true“ ausgezeichnet. Welche Seite im Menü die derzeit angezeigte ist, geht für Screenreader-Nutzer:innen nur aus dem <title> hervor.
Fazit
Sie werden nicht um das Thema herumkommen. Sie können jetzt langsam mit digitaler Barrierefreiheit anfangen, oder es in zwei Jahren unter Zeitdruck tun, wenn die Konkurrenz an Ihnen vorbeizieht. Dabei ist es egal, ob Ihr Produkt eine Komponente, ein Tool oder eine Plattform ist. Je eher Sie anfangen, umso größer wird Ihr Vorsprung sein. Nicht zu vernachlässigen ist auch der soziale Aspekt: Im Idealfall hilft es uns als Gesellschaft, mehr Verständnis füreinander und unsere unterschiedlichen Voraussetzungen zu erhalten, die bisher einfach als Unzulänglichkeit Einzelner abgetan wurden.
| Problem | % | Widerspricht BITV … (Level nach WCAG) |
|---|---|---|
| langsam ladende Seiten | 21 | – |
| mehrere Pop-ups | 9.1.4.13 Eingeblendete Inhalte bedienbar (AA) | |
| automatisch abspielende Musik | 20 | 9.1.4.2 Ton abschaltbar (A) |
| kaputte Seiten (404 Error) | 17 | WCAG-Prinzip Robust (A und AA) |
| automatisch abspielende Videos | mArKeD mArKeD mArKeD 1 mArKeD6 | 9.2.2.2 Bewegte Inhalte abschaltbar (A) 9.2.3.1 Verzicht auf Flackern (A/AA) |
| mArKeD mArKeD mArKeD nicht klickbare Button mArKeDs | 14 | 9.1.1.1a Alternativtexte für Bedienelemente (A) 9.4.1.1 Korrekte Syntax (A) |
| schwer lesbare Schrift | 13 | 9.1.4.3 Kontraste von Texten ausreichend (AA) |
| Bilder, die nicht laden (und keine Alt-Tags haben) | 12 | WCAG-Prinzip Robust (A und AA) 9.1.1.1b Alternativtexte für Grafiken und Objekte (A) |
| Bilderkarussells | 10 | 9.1.1.1a Alternativtexte für Bedienelemente (A) 9.4.1.2 Name, Rolle, Wert verfügbar (A) |
| ablenkende Animationen | 5 | 9.2.3.1 Verzicht auf Flackern (A) 9.2.2.2 Bewegte Inhalte abschaltbar (A) |
Tabelle 3: Die Stressfaktoren im Internet den Anforderungen der Barrierefreiheit zugeordne
 Annika Brinkmann, Web-Designerin seit 2003, sensibilisiert und schult Teams, die an Konzeption, Gestaltung, Programmierung und Redaktion barrierefreier Webseiten beteiligt sind. Auf Barrieren-fasten.de bietet sie Entwickler:innen einen niedrigschwelligen Einstieg.
Annika Brinkmann, Web-Designerin seit 2003, sensibilisiert und schult Teams, die an Konzeption, Gestaltung, Programmierung und Redaktion barrierefreier Webseiten beteiligt sind. Auf Barrieren-fasten.de bietet sie Entwickler:innen einen niedrigschwelligen Einstieg.
Links & Literatur
[1] https://online-accessibility-countdown.eu/
[2] https://gehirngerecht.digital/digitale-barrierefreiheit-pflicht-wissen/
[3] https://eur-lex.europa.eu/legal-content/DE/TXT/HTML/?uri=CELEX:32019L0882
[4] https://www.w3.org/TR/WCAG21/
[5] https://www.w3.org/TR/WCAG22/
[6] https://www.w3.org/WAI/WCAG21/quickref/ wurde bereits 2018 finalisiert
[7] https://www.w3.org/WAI/WCAG22/quickref/ wird noch um neue Anforderungen ergänzt
[8] https://ergebnis.bitvtest.de/pruefverfahren/bitv-20-web
[10] https://ergebnis.bitvtest.de/pruefschritt/bitv-20-web/11-7-benutzerdefinierte-einstellungen
[11] https://www.cdc.gov/ncbddd/disabilityandhealth/infographic-disability-impacts-all.html
[12] https://www.destatis.de/DE/Themen/Gesellschaft-Umwelt/Gesundheit/Behinderte-Menschen/_inhalt.html
[13] https://www.dbsv.org/zahlen-fakten.html
[14] https://accessibleweb.com/civil-rights/the-curb-cut-effect-7-ways-the-ada-is-for-everyone/
[15] https://webaim.org/projects/million/
[16] https://www.netimperative.com/2020/12/09/blood-pressure-study-which-website-issue-cause-users-the-most-stress/ leider ist nur noch Sekundärliteratur online, bei Cyber-duck selbst taucht die Studie nicht mehr auf: https://www.cyber-duck.co.uk/
[17] https://www.dbsv.org/bildbeschreibung-4-regeln.html
[18] https://de.wikipedia.org/wiki/Dark_Pattern#Beispiele_f%C3%BCr_Dark_Patterns
[19] https://overlayfactsheet.com/
[20] https://ergebnis.bitvtest.de/pruefschritt/bitv-20-web/9-2-2-2-bewegte-inhalte-abschaltbar
[21] https://ergebnis.bitvtest.de/pruefschritt/bitv-20-web/9-2-3-1-verzicht-auf-flackern
[22] https://alistapart.com/article/responsive-web-design/ von Ethan Marcotte erschien am 25. Mai 2010
[23] https://ergebnis.bitvtest.de/pruefschritt/bitv-20-web/9-1-4-10-inhalte-brechen-um
[25] https://www.googlewatchblog.de/2015/02/mobile-websuche-apps-ranking/
[26] https://ebakery.de/google-mobile-first-index/
[27] https://ergebnis.bitvtest.de/pruefschritt/bitv-20-web/11-8-2-barrierefreie-erstellung-von-inhalten
[28] https://summ-ai.com/
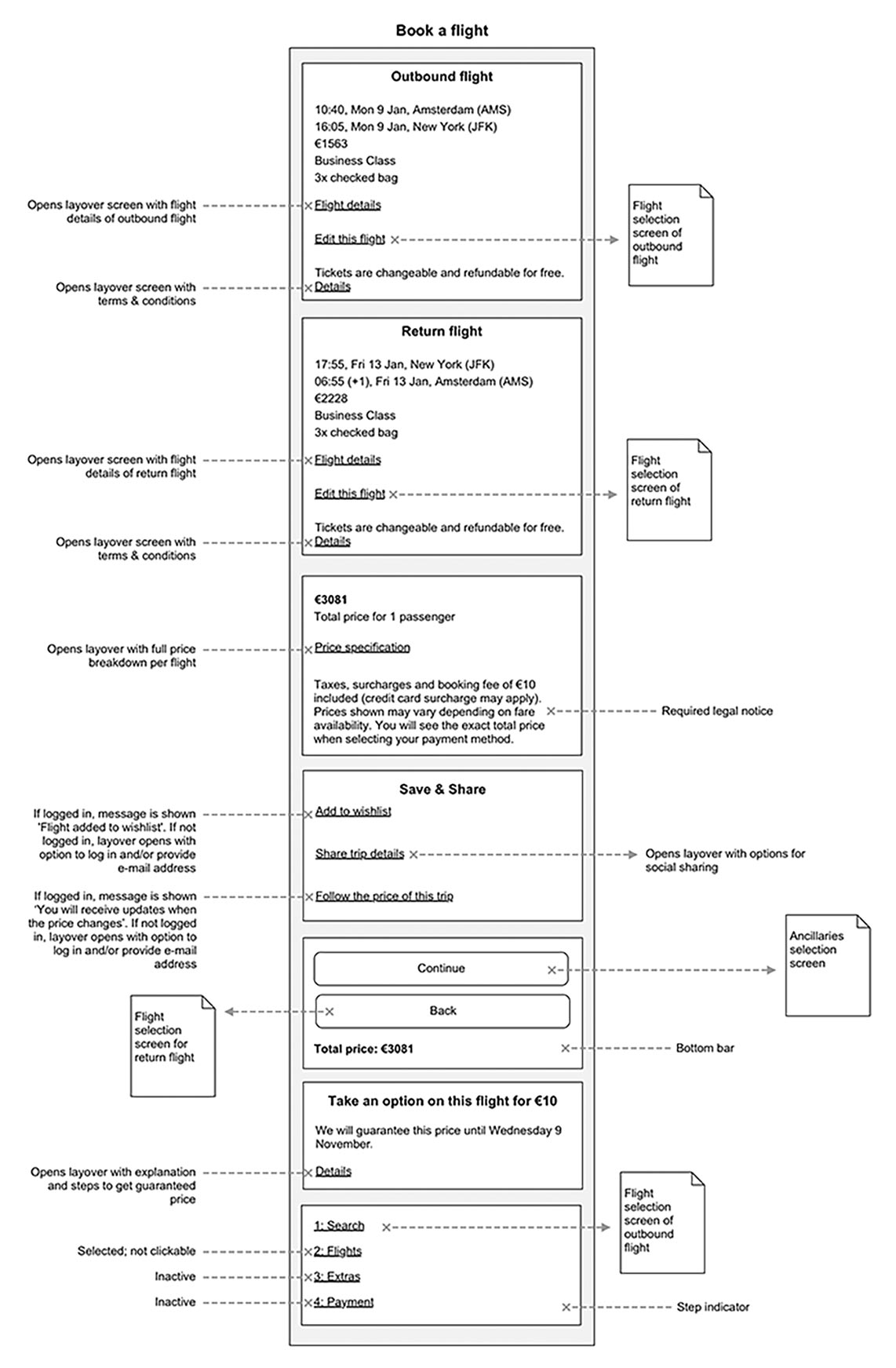 Abb. 1: Ein detaillierter digitaler Priority Guide für eine Flugbuchungsseite
Abb. 1: Ein detaillierter digitaler Priority Guide für eine Flugbuchungsseite Abb. 2: Der Designalgorithmus eignet sich für jede Art von Projekt
Abb. 2: Der Designalgorithmus eignet sich für jede Art von Projekt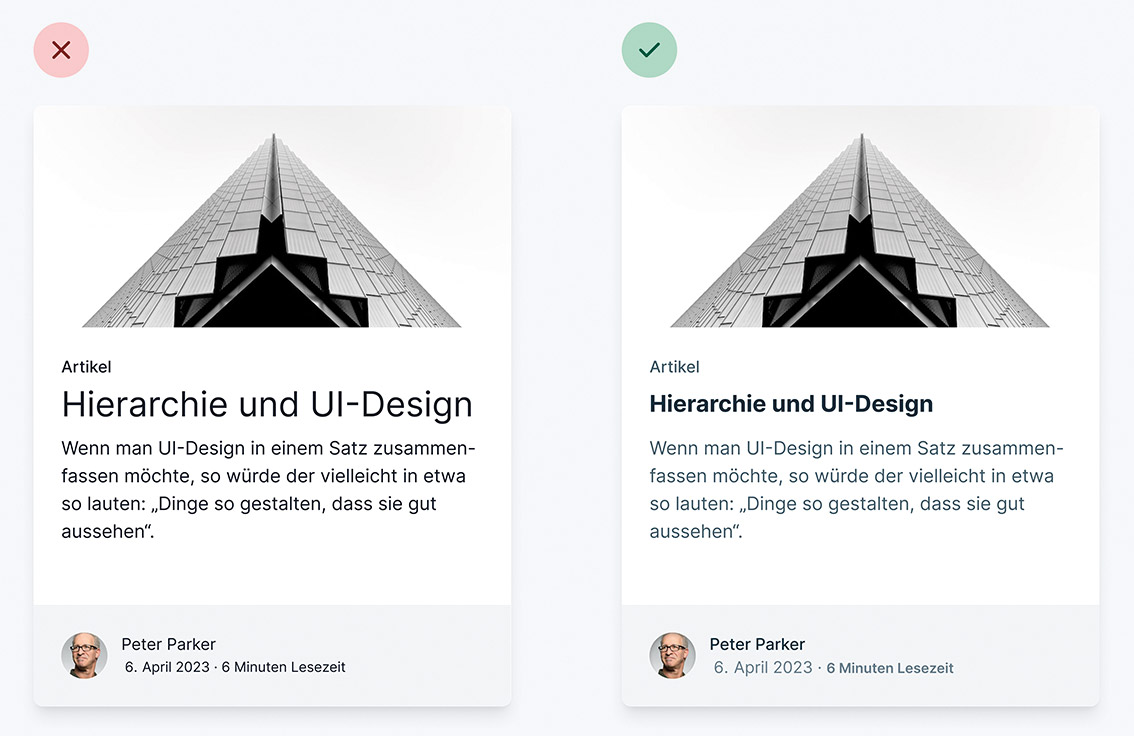 Abb. 3: Gestaltung mit Hilfe der Schriftgröße oder der Farbe
Abb. 3: Gestaltung mit Hilfe der Schriftgröße oder der Farbe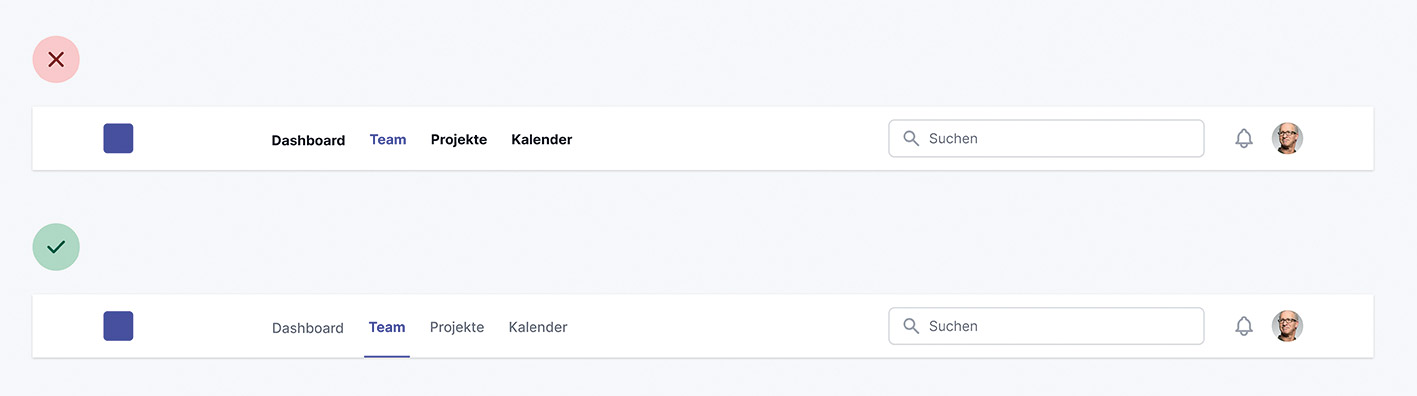 Abb. 4: Wir geben den inaktiven Elementen eine weichere Farbe und senken den Kontrast
Abb. 4: Wir geben den inaktiven Elementen eine weichere Farbe und senken den Kontrast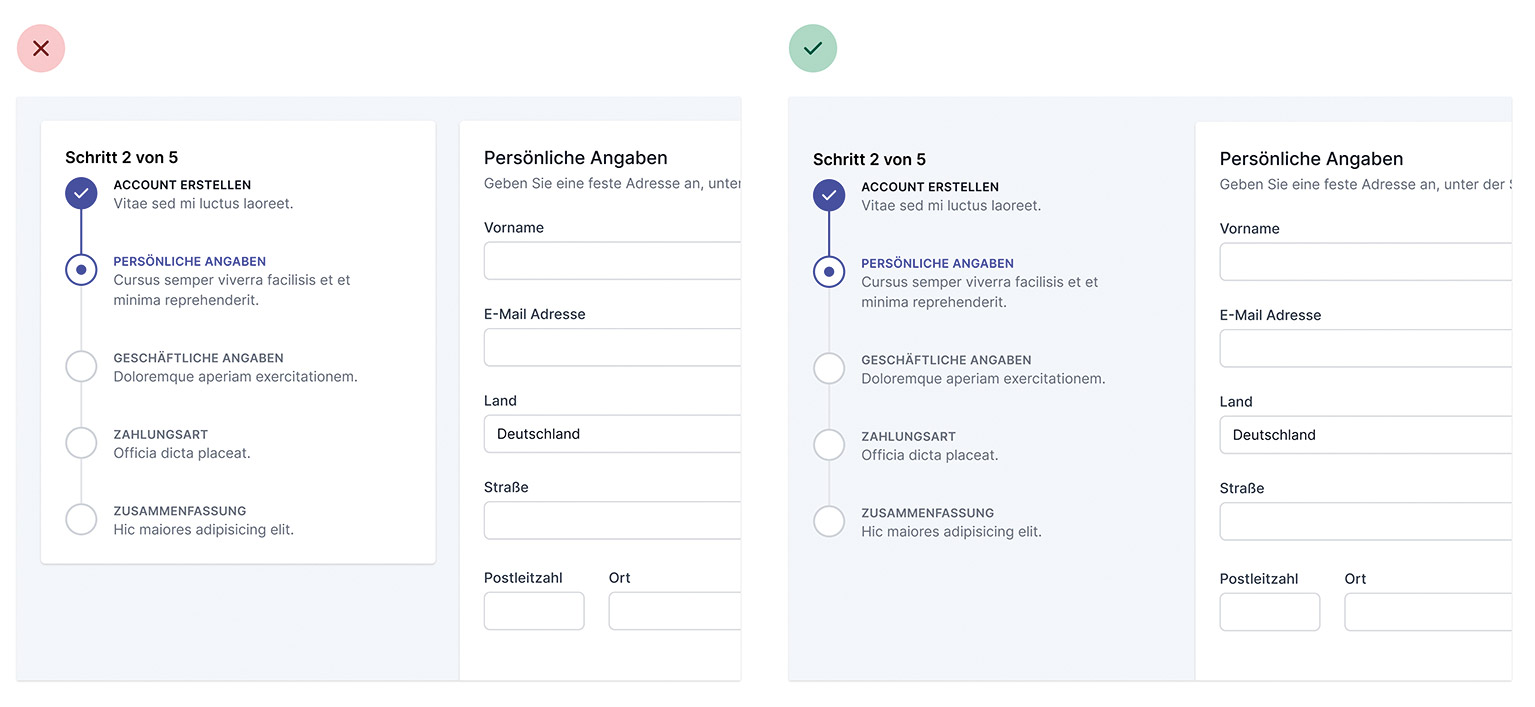 Abb. 5: Das Prinzip der Abschwächung lässt sich auch bei größeren UI-Organismen einsetzen
Abb. 5: Das Prinzip der Abschwächung lässt sich auch bei größeren UI-Organismen einsetzen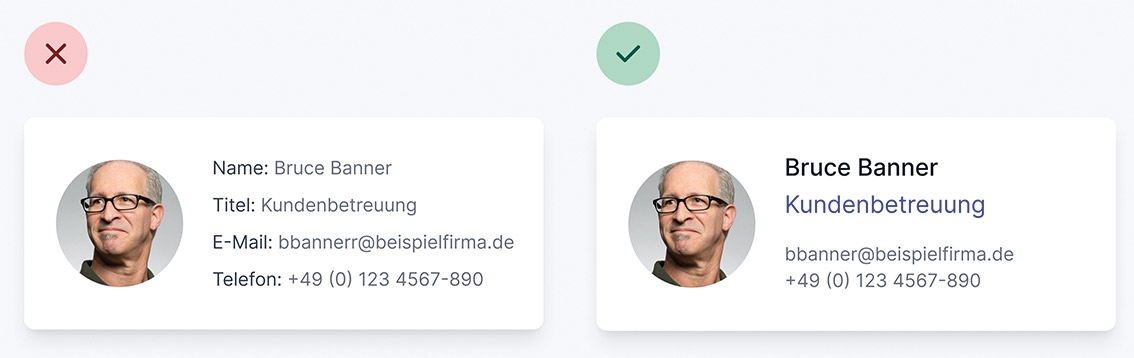 Abb. 6: Labels können oft die schnelle Erfassung von Inhalten beeinträchtigen
Abb. 6: Labels können oft die schnelle Erfassung von Inhalten beeinträchtigen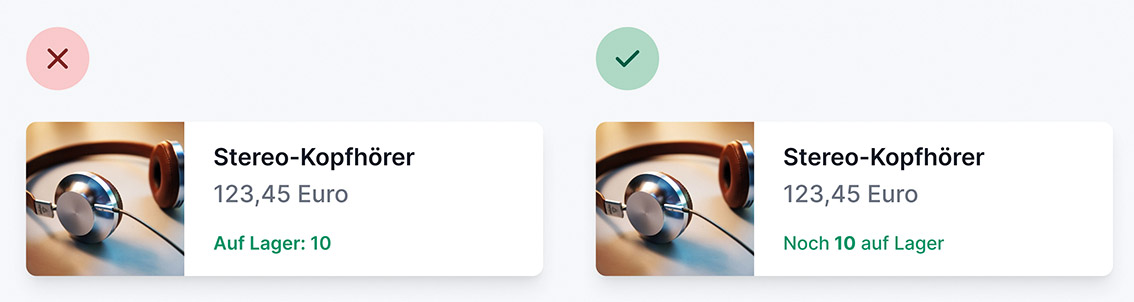 Abb. 7: Besser, so liest es sich nicht wie Kaugummi
Abb. 7: Besser, so liest es sich nicht wie Kaugummi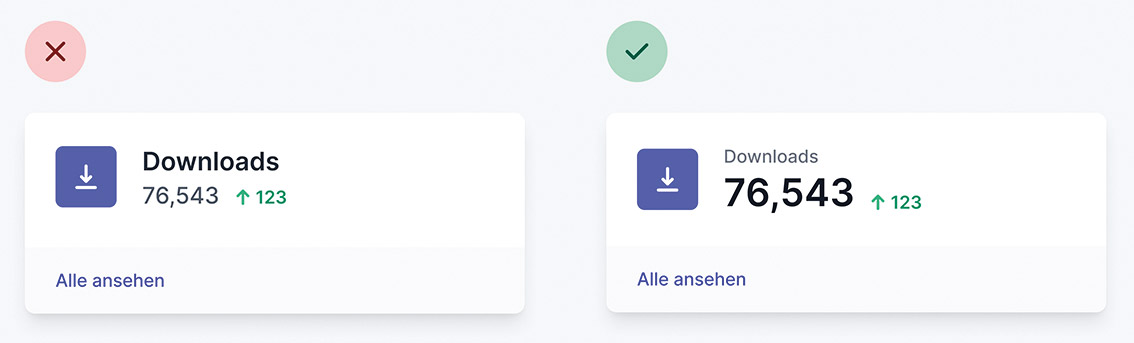 Abb. 8: Labels sind sekundär, gerade in Dashboards
Abb. 8: Labels sind sekundär, gerade in Dashboards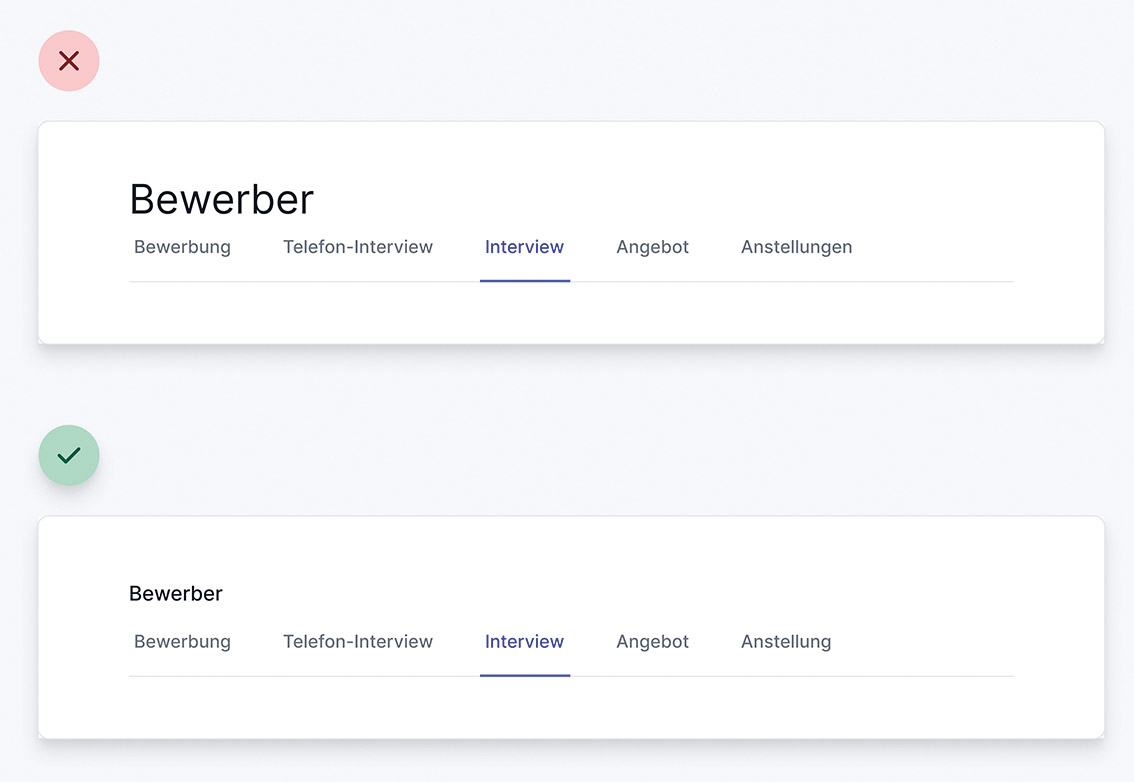 Abb. 9: Abschnittstitel sollten nicht die ganze Aufmerksamkeit auf sich ziehen
Abb. 9: Abschnittstitel sollten nicht die ganze Aufmerksamkeit auf sich ziehen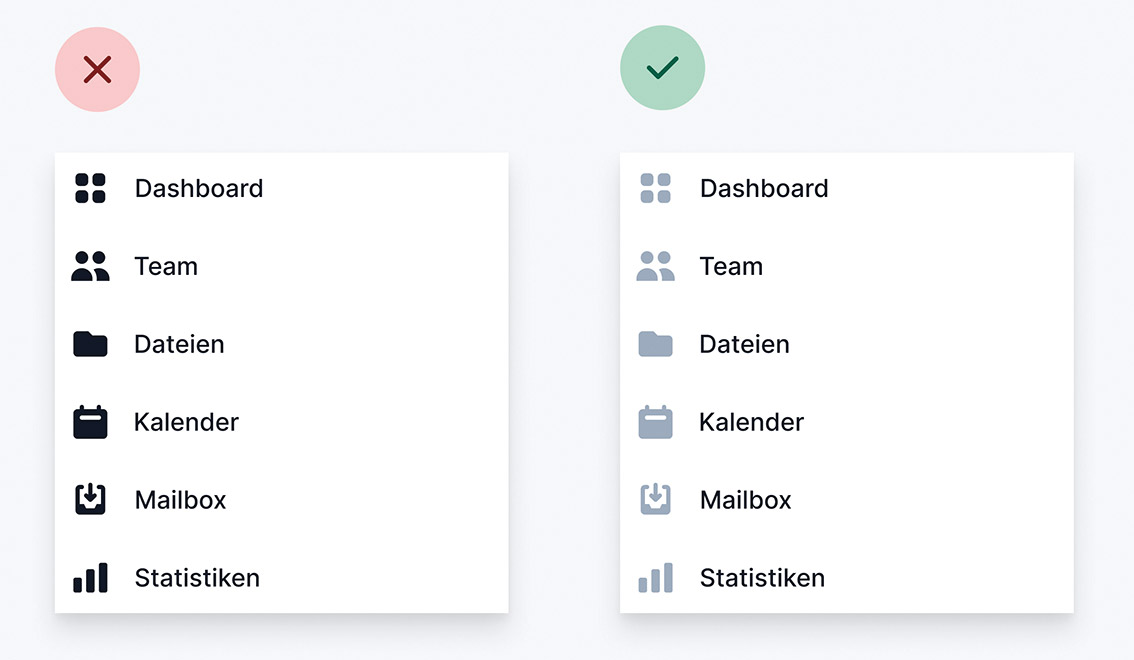 Abb. 10: Verringerung des Kontrasts durch eine weichere Farbe
Abb. 10: Verringerung des Kontrasts durch eine weichere Farbe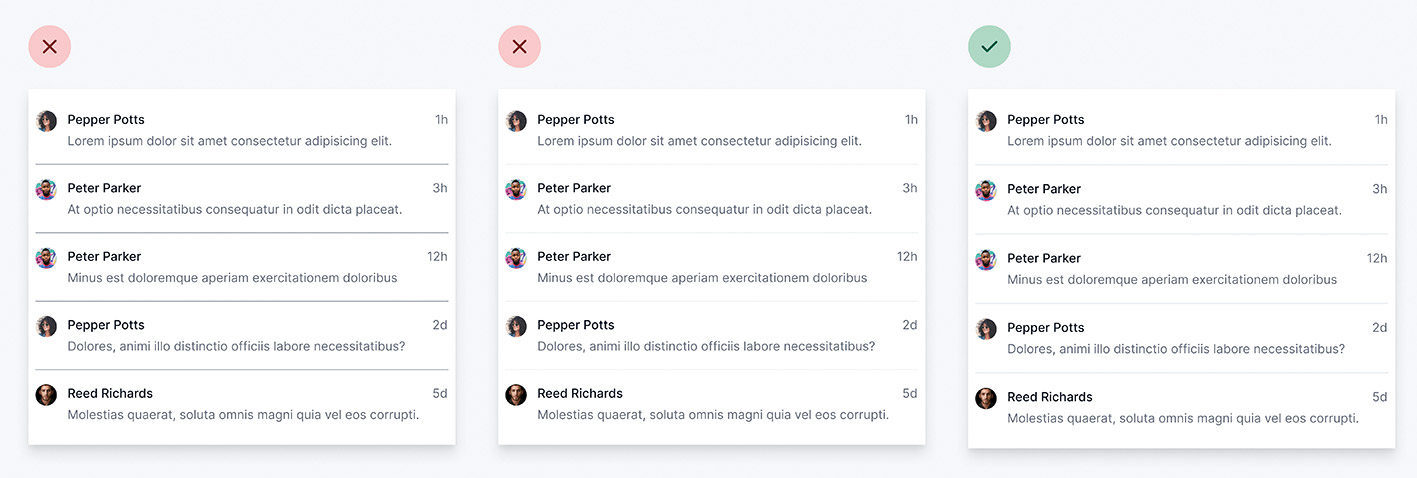 Abb. 11: Etwas dickere Linien helfen, sie zu betonen, ohne dass der subtile Eindruck verloren geht
Abb. 11: Etwas dickere Linien helfen, sie zu betonen, ohne dass der subtile Eindruck verloren geht Abb. 12: Wir geben den Benutzenden eine klare Richtung vor
Abb. 12: Wir geben den Benutzenden eine klare Richtung vor Abb. 13: Aufteilung von Interaktionsmöglichkeiten mit abnehmender visueller Prominenz
Abb. 13: Aufteilung von Interaktionsmöglichkeiten mit abnehmender visueller Prominenz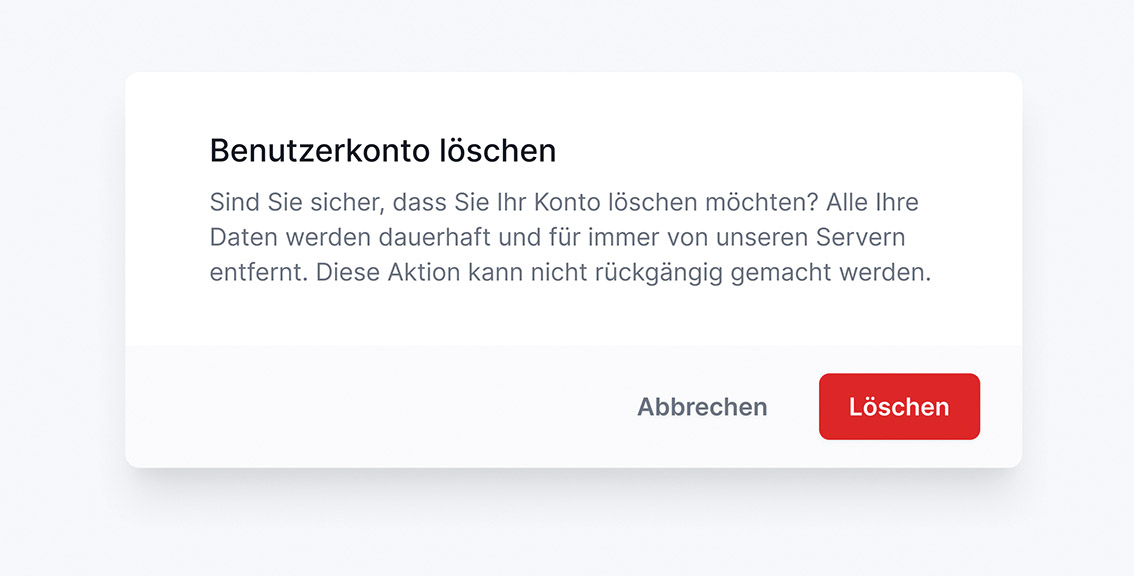 Abb. 14: Bei der Bestätigung darf’s auch ordentlich rot sein
Abb. 14: Bei der Bestätigung darf’s auch ordentlich rot sein Henning Fries ist Senior User Interface Architect und beschäftigt sich mit Themen wie Ideation, Accessibility, UX und UI. Mit mehr als fünfzehn Jahren Berufserfahrung arbeitet er als Berater, Trainer, Entwickler, Project Manager und (Web-)Designer in Deutschland und Luxemburg.
Henning Fries ist Senior User Interface Architect und beschäftigt sich mit Themen wie Ideation, Accessibility, UX und UI. Mit mehr als fünfzehn Jahren Berufserfahrung arbeitet er als Berater, Trainer, Entwickler, Project Manager und (Web-)Designer in Deutschland und Luxemburg. Abb.1: Das magische Dreieck: Mehr Geld wirkt sich positiv auf Qualität/Zeit aus
Abb.1: Das magische Dreieck: Mehr Geld wirkt sich positiv auf Qualität/Zeit aus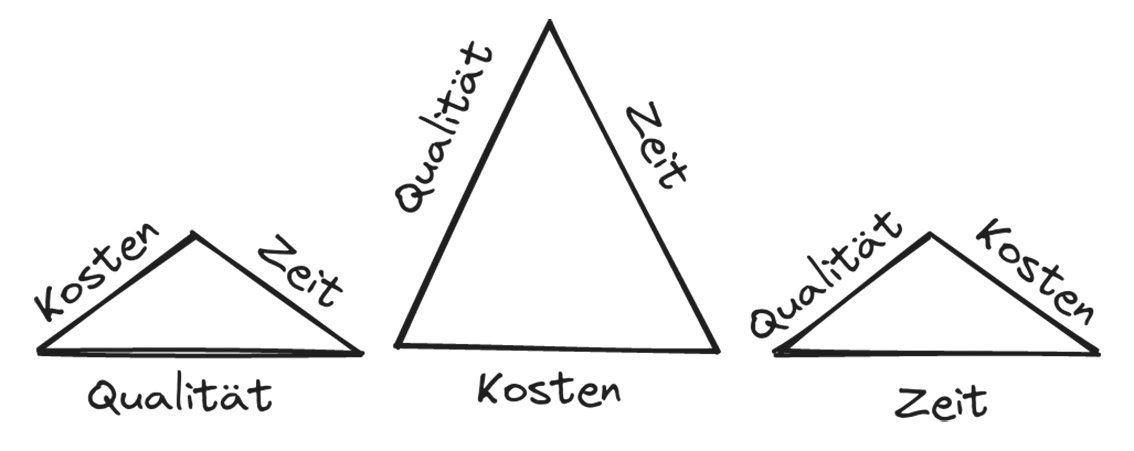 Abb. 2: Das magische Dreieck: Geringere Investitionen wirken sich negativ auf Qualität/Zeit aus
Abb. 2: Das magische Dreieck: Geringere Investitionen wirken sich negativ auf Qualität/Zeit aus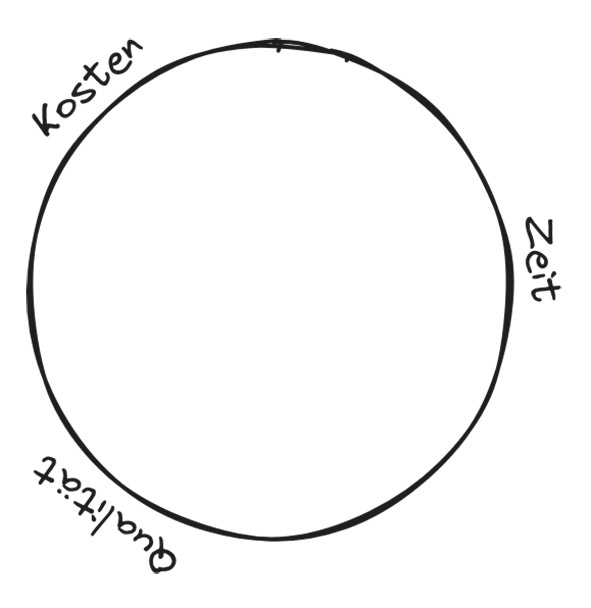 Abb. 3: Auf lange Sicht kann der Zusammenhang zwischen Kosten, Zeit und Qualität überwunden werden
Abb. 3: Auf lange Sicht kann der Zusammenhang zwischen Kosten, Zeit und Qualität überwunden werden Abb. 4: Technische Schuld
Abb. 4: Technische Schuld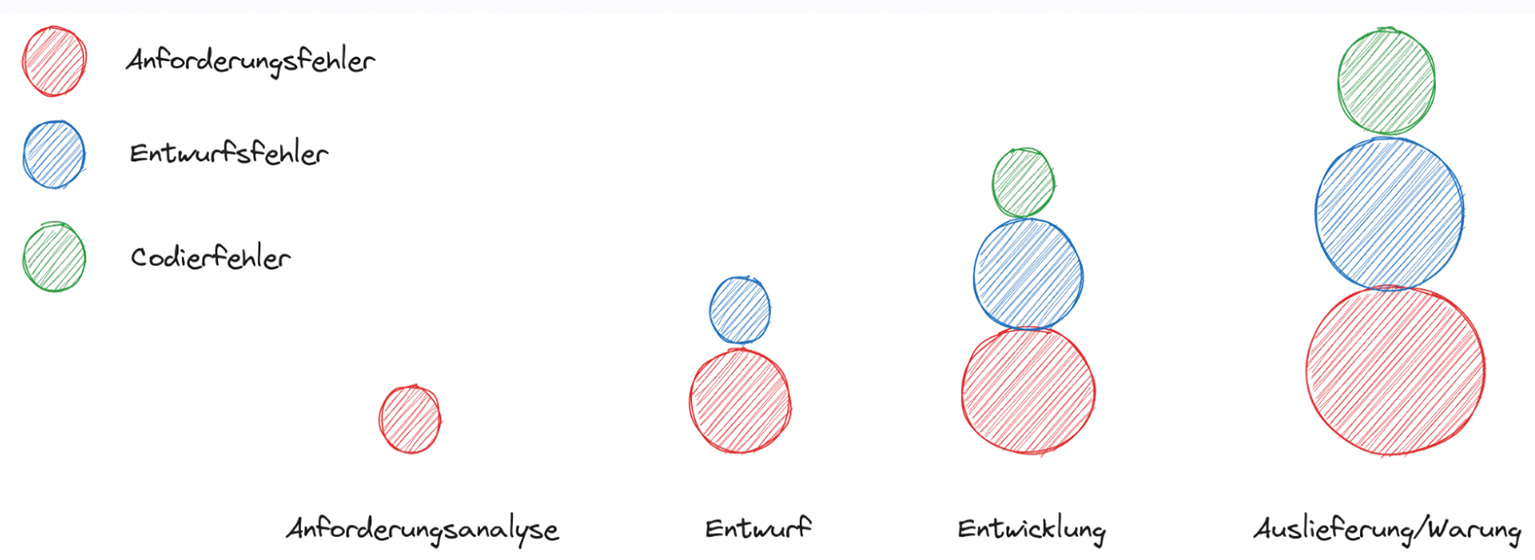 Abb. 5: Relative Kosten für die Fehlerbehebung in den unterschiedlichen Projektphasen
Abb. 5: Relative Kosten für die Fehlerbehebung in den unterschiedlichen Projektphasen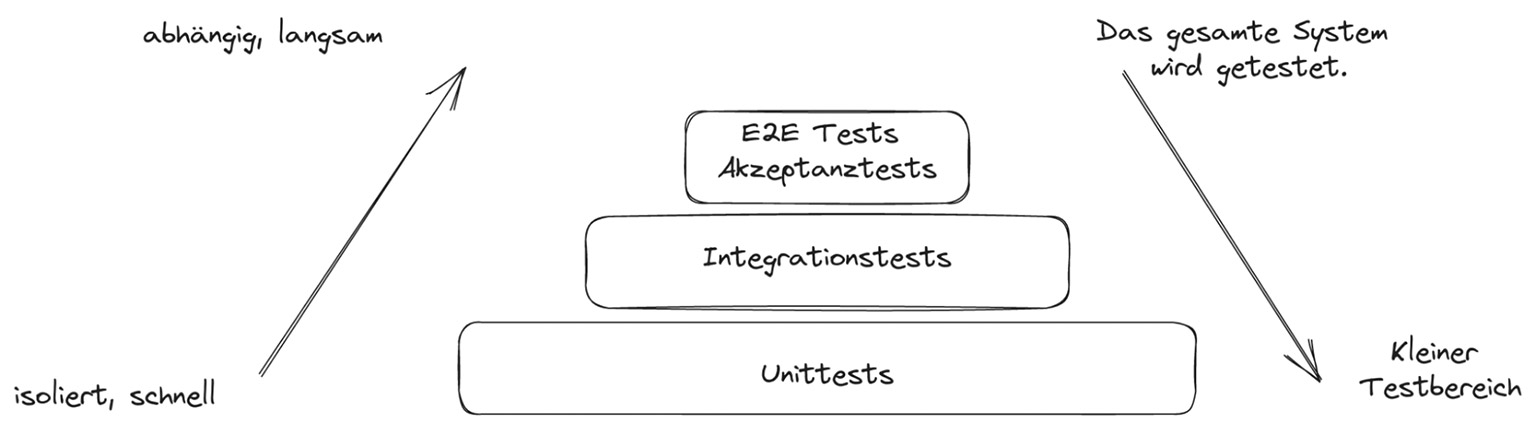 Abb. 6: Teststrategien – Top-down und Bottom-up
Abb. 6: Teststrategien – Top-down und Bottom-up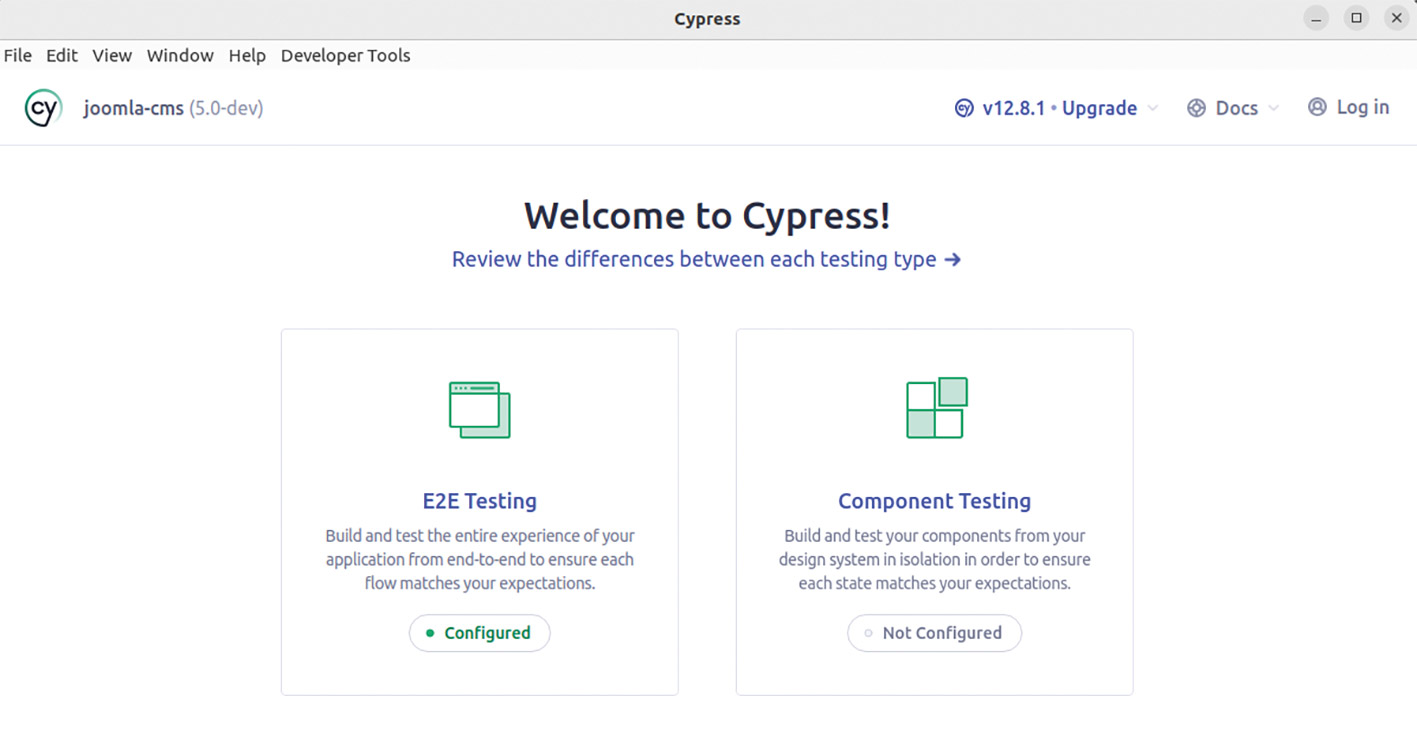 Abb. 7: Cypress-App öffnet sich nach dem Aufruf von npm run cypress:open
Abb. 7: Cypress-App öffnet sich nach dem Aufruf von npm run cypress:open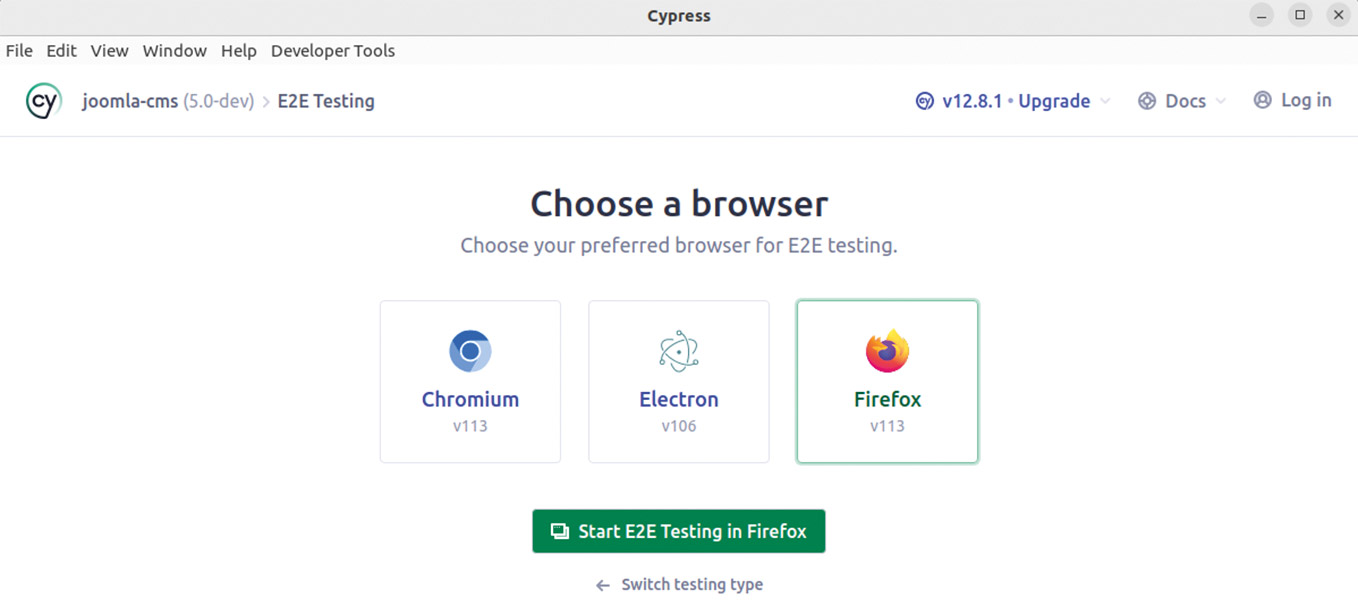 Abb. 8: E2E-Tests in der Cypress-App: Wähle den zu verwendenden Browser
Abb. 8: E2E-Tests in der Cypress-App: Wähle den zu verwendenden Browser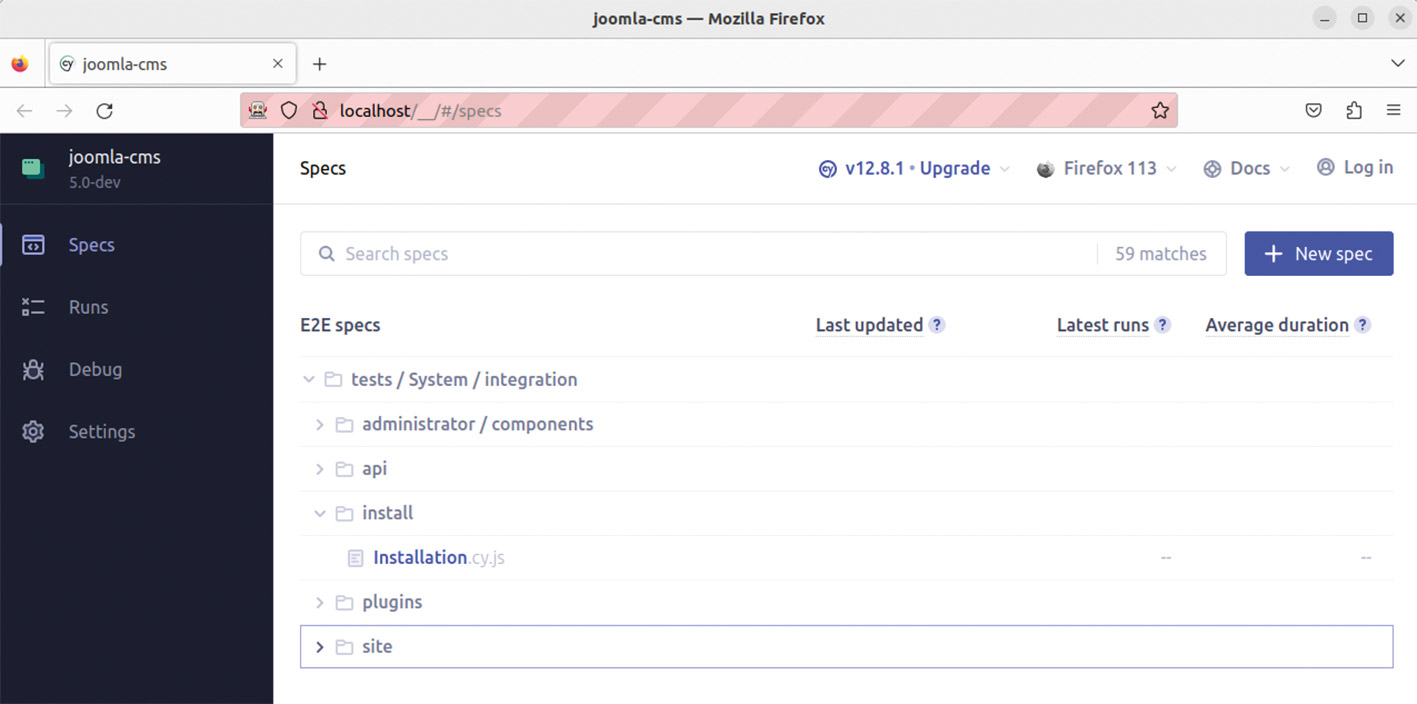 Abb. 9: Joomla!-Testreihe in Firefox über Cypress-App
Abb. 9: Joomla!-Testreihe in Firefox über Cypress-App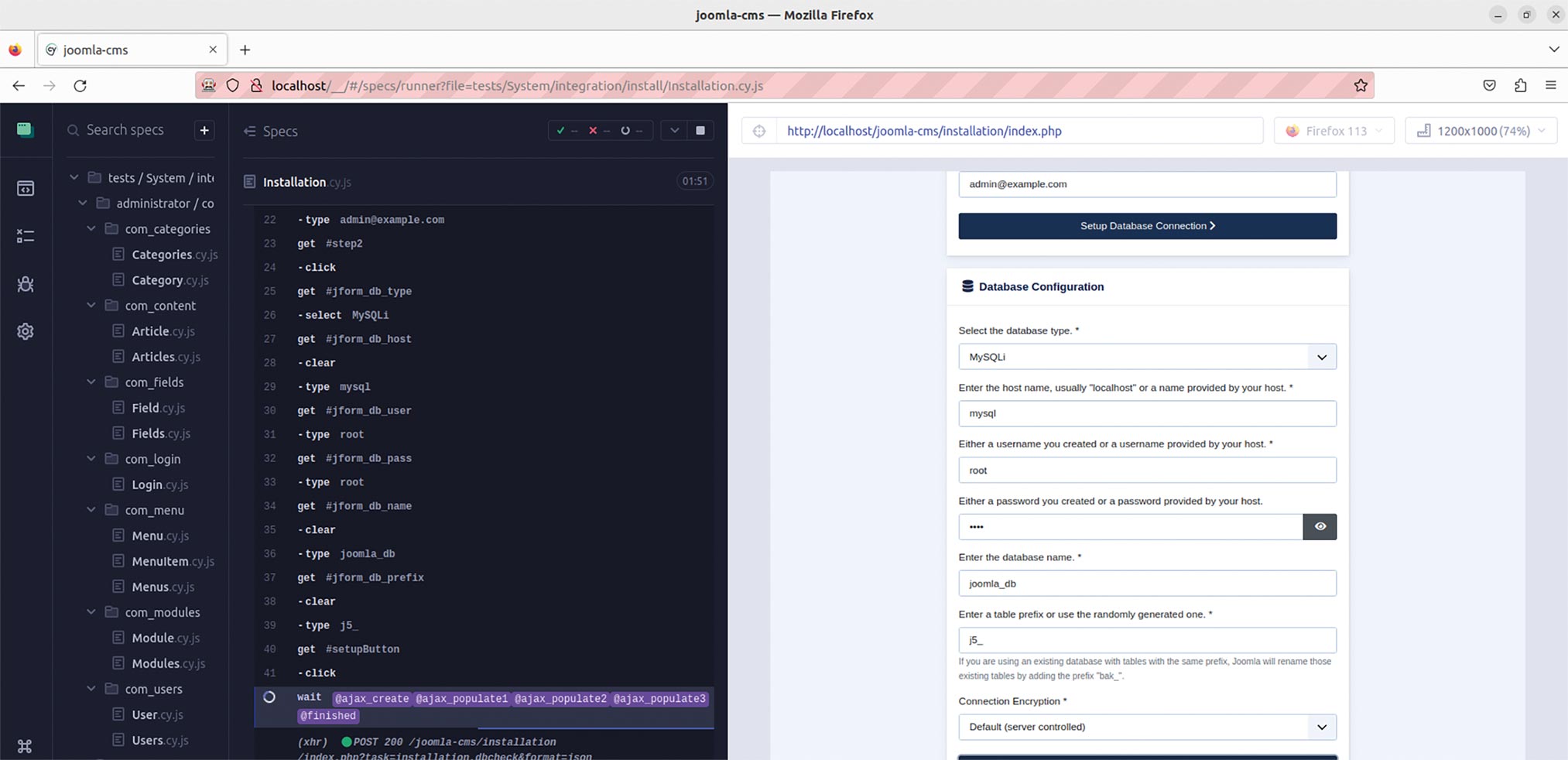 Abb. 10: Der Test, der die korrekte Installation von Joomla! sicherstellt, während der Ausführung
Abb. 10: Der Test, der die korrekte Installation von Joomla! sicherstellt, während der Ausführung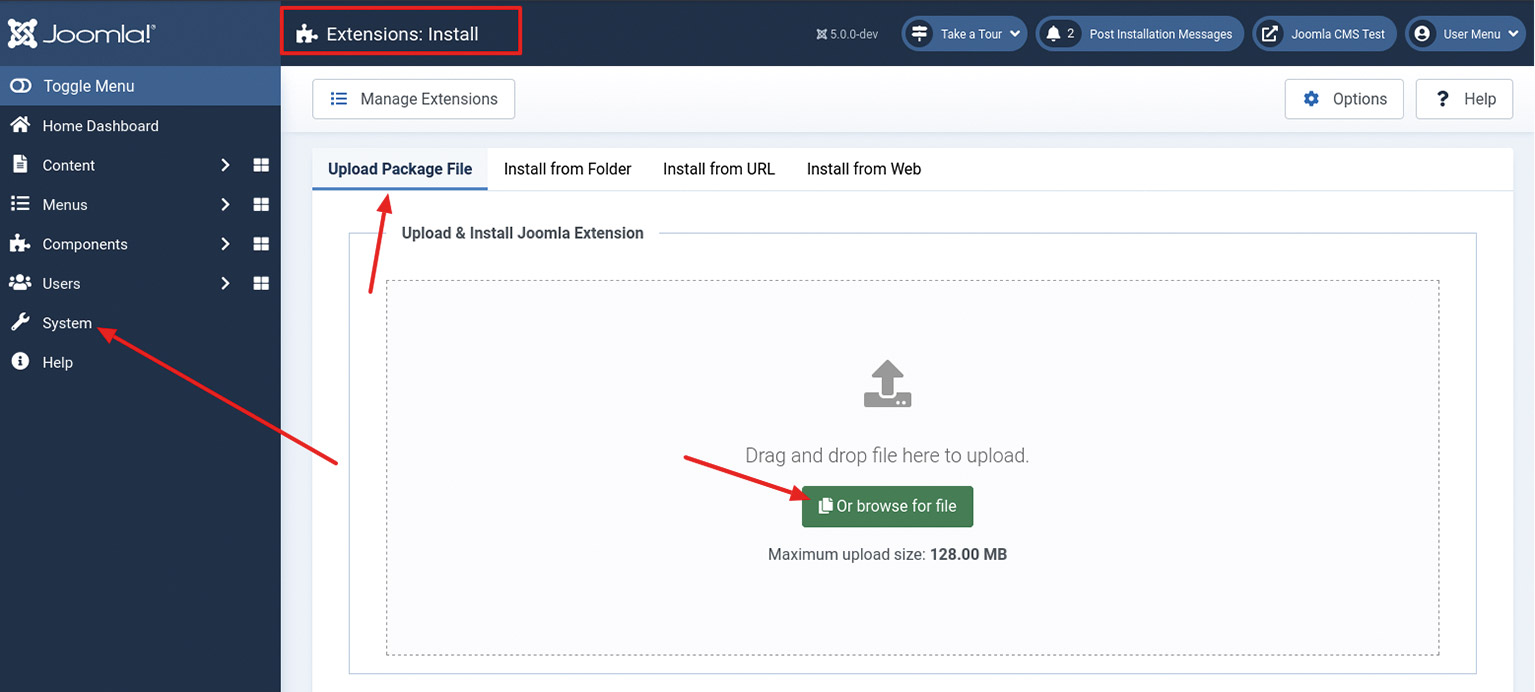 Abb. 11: Installation einer eigenen Joomla!-Erweiterung
Abb. 11: Installation einer eigenen Joomla!-Erweiterung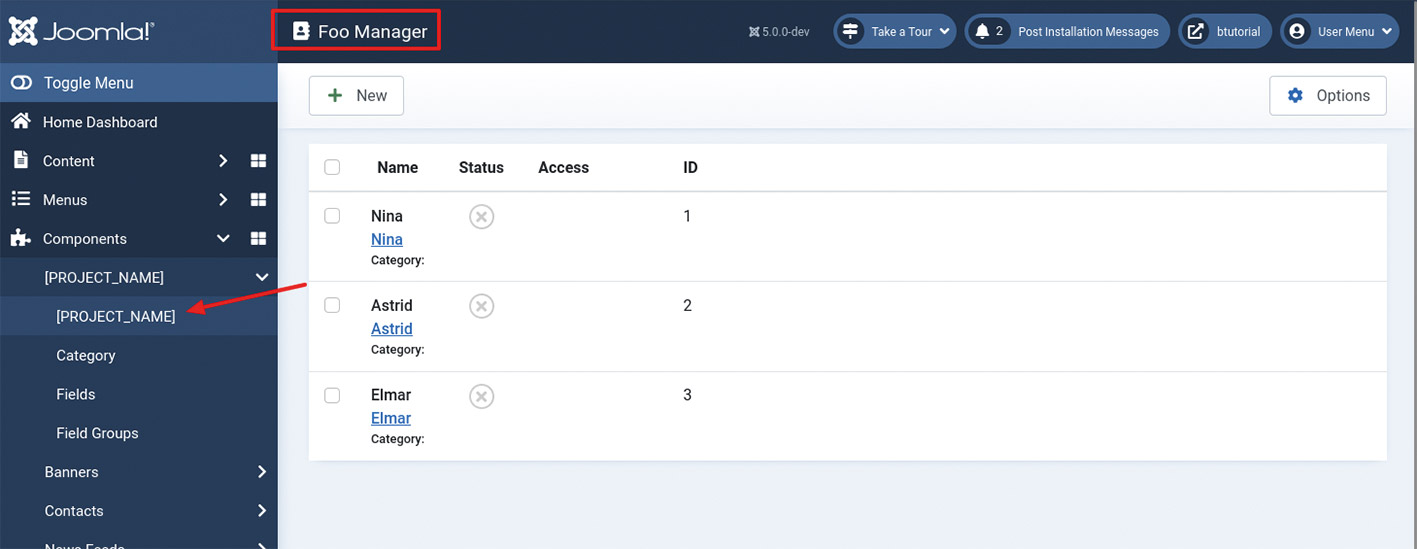 Abb 12: Ansicht der Beispielkomponente im Joomla!-Backend
Abb 12: Ansicht der Beispielkomponente im Joomla!-Backend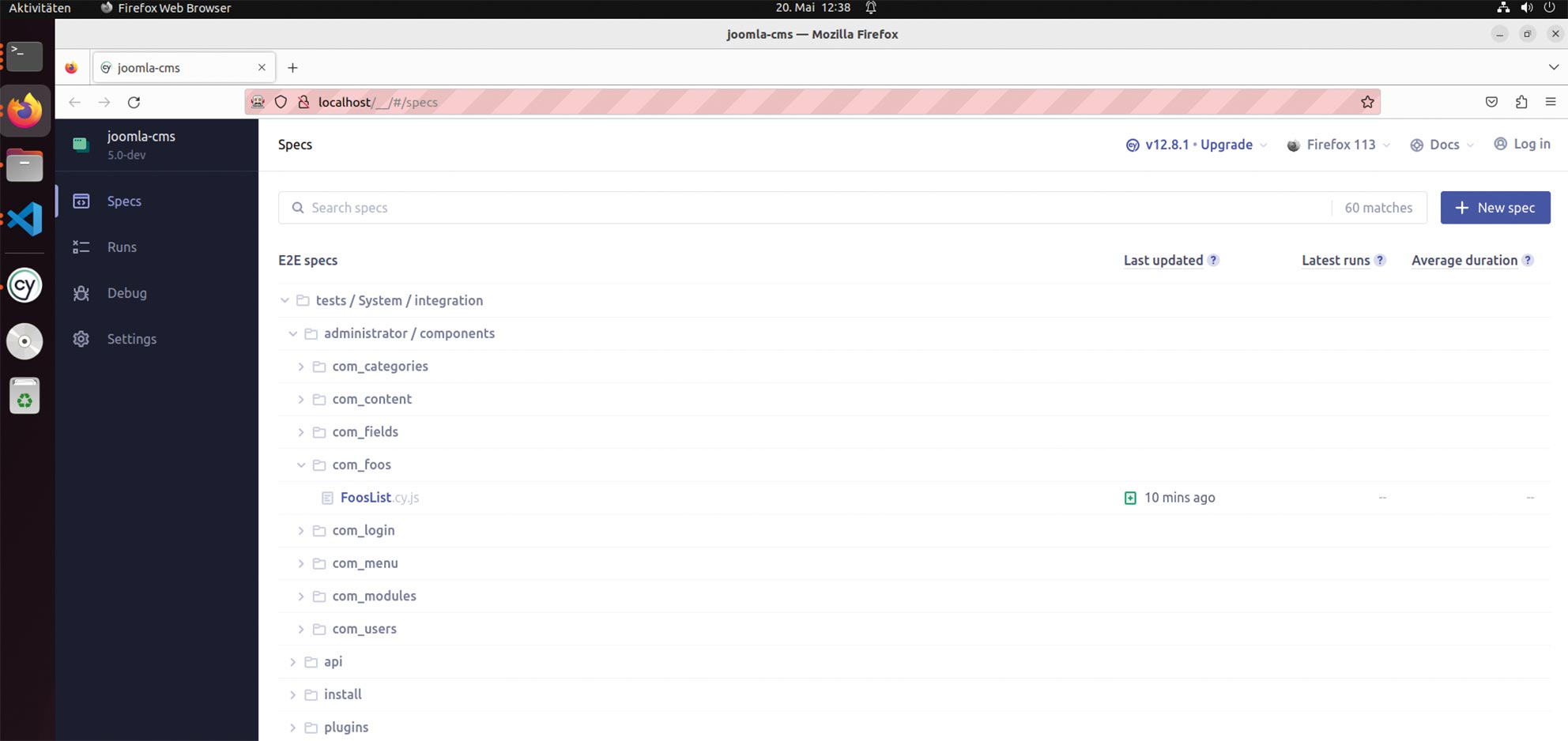 Abb. 13: Joomla!-Test für die eigene Erweiterung ausführen
Abb. 13: Joomla!-Test für die eigene Erweiterung ausführen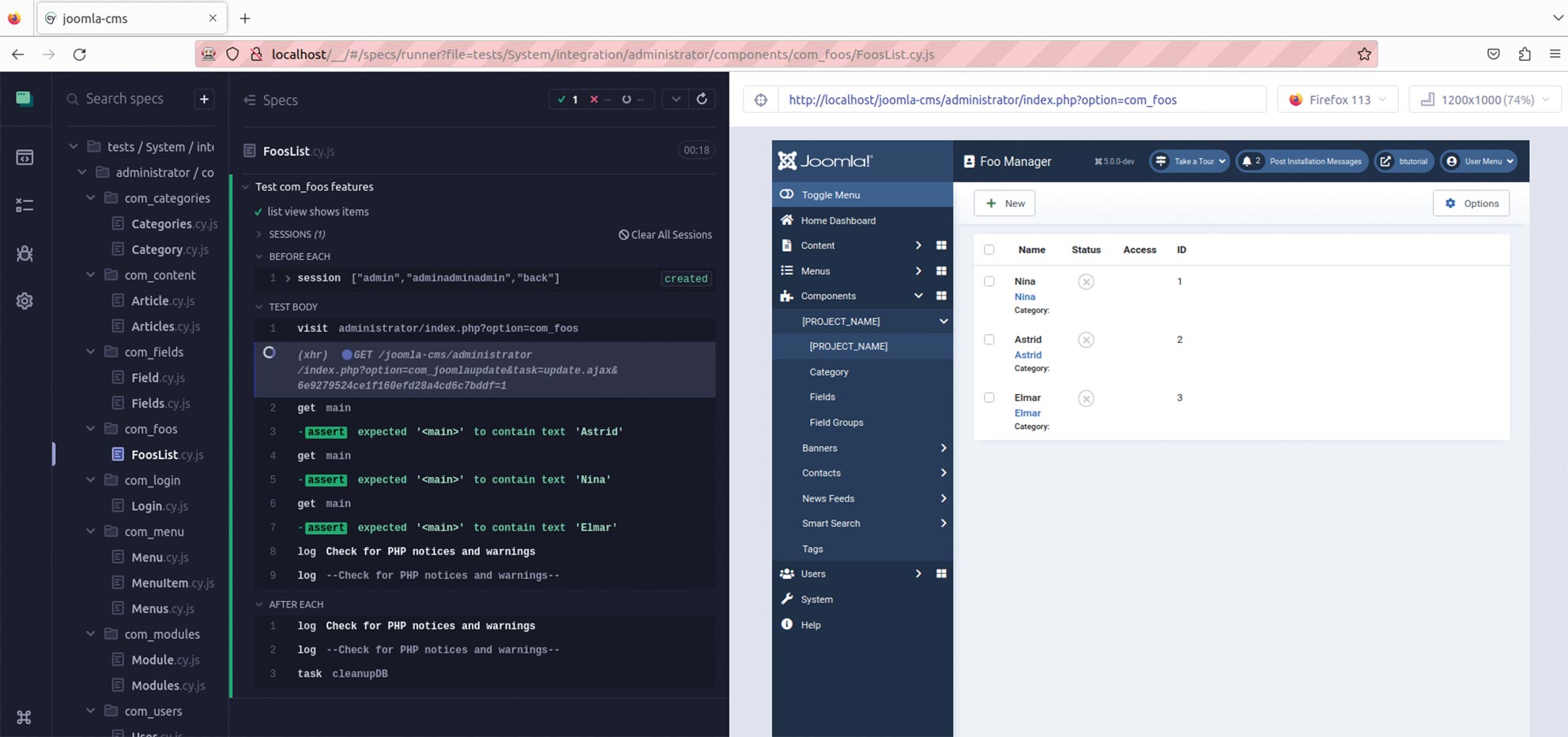 Abb. 14: Ansicht, nachdem der Test erfolgreich durchgelaufen ist
Abb. 14: Ansicht, nachdem der Test erfolgreich durchgelaufen ist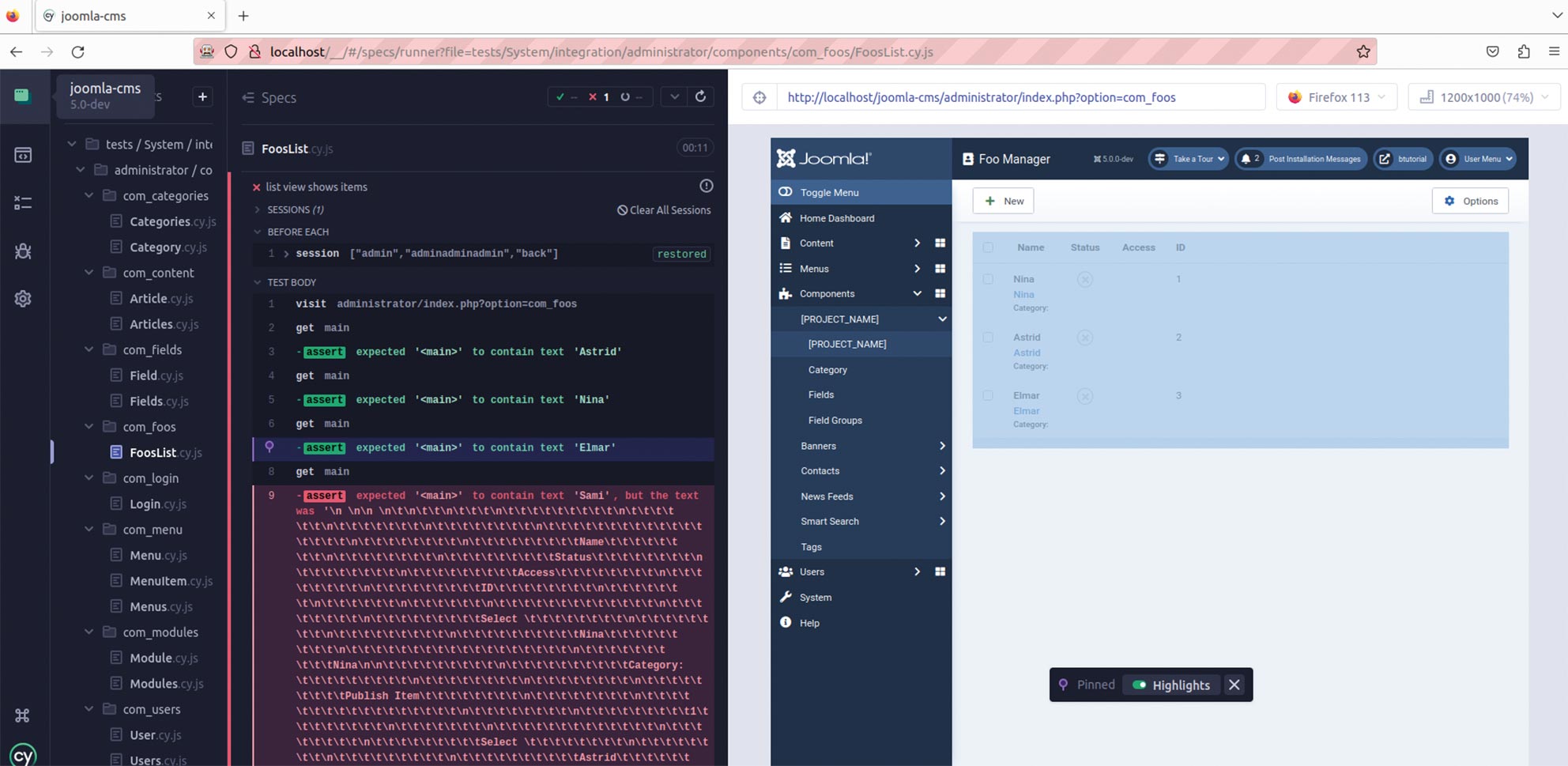 Abb. 15: Ansicht, nachdem der Test fehlgeschlagen ist
Abb. 15: Ansicht, nachdem der Test fehlgeschlagen ist Seit 2017 programmiert Astrid Günther individuelle Websites und schreibt Bücher für Menschen, denen ihr Auftritt im Web wichtig ist. Am liebsten mit Joomla! und sehr gerne in Kombination mit geografischen Daten. Dabei schaut sie immer gerne über den Tellerrand hin zu anderen Open-Source-Projekten.
Seit 2017 programmiert Astrid Günther individuelle Websites und schreibt Bücher für Menschen, denen ihr Auftritt im Web wichtig ist. Am liebsten mit Joomla! und sehr gerne in Kombination mit geografischen Daten. Dabei schaut sie immer gerne über den Tellerrand hin zu anderen Open-Source-Projekten. Abb. 1: Requests-Bibliothek
Abb. 1: Requests-Bibliothek Abb. 2: Extrahierte Links einer Webseite
Abb. 2: Extrahierte Links einer Webseite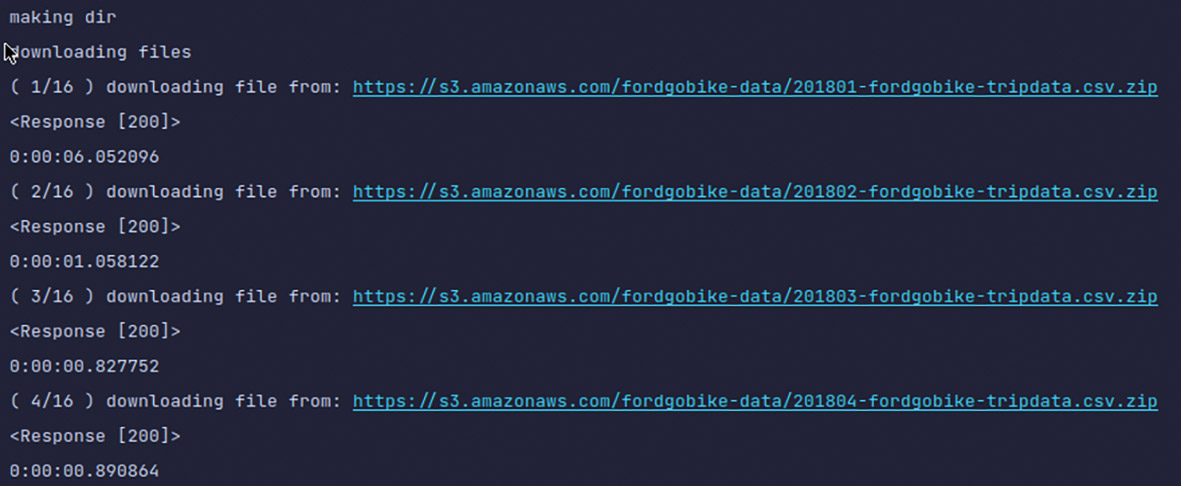 Abb. 3: Fortschrittsanzeige der Downloads
Abb. 3: Fortschrittsanzeige der Downloads Abb. 4: Metadaten eines Vimeo-Videos
Abb. 4: Metadaten eines Vimeo-Videos Abb. 5: Download von Vimeo-Videos
Abb. 5: Download von Vimeo-Videos Abb. 6: Download von YouTube-Videos ohne Fortschrittsanzeige
Abb. 6: Download von YouTube-Videos ohne Fortschrittsanzeige Abb. 7: Konfigurationsdatei unter Python
Abb. 7: Konfigurationsdatei unter Python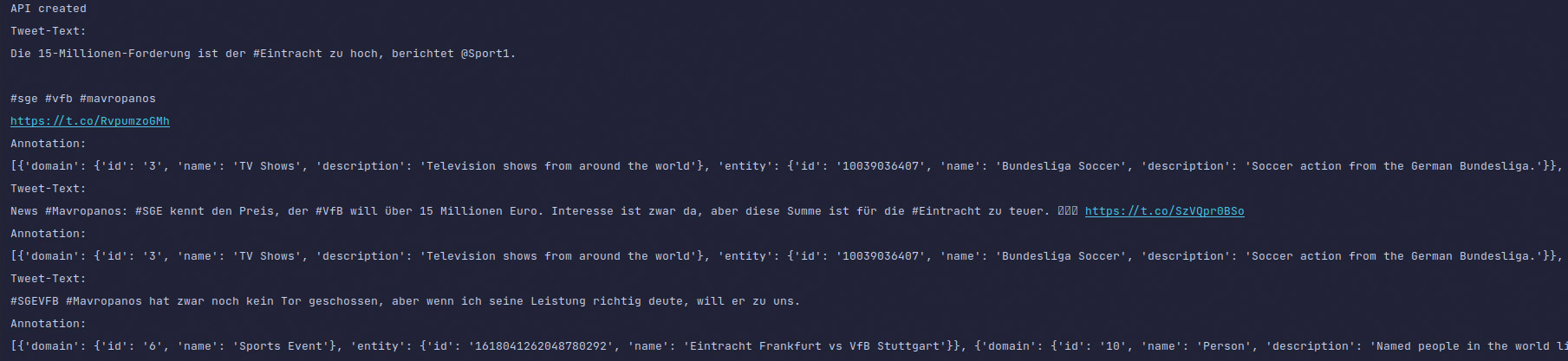 Abb. 8: Tweets zum Hashtag #Mavropanos zusammen mit Annotationen
Abb. 8: Tweets zum Hashtag #Mavropanos zusammen mit Annotationen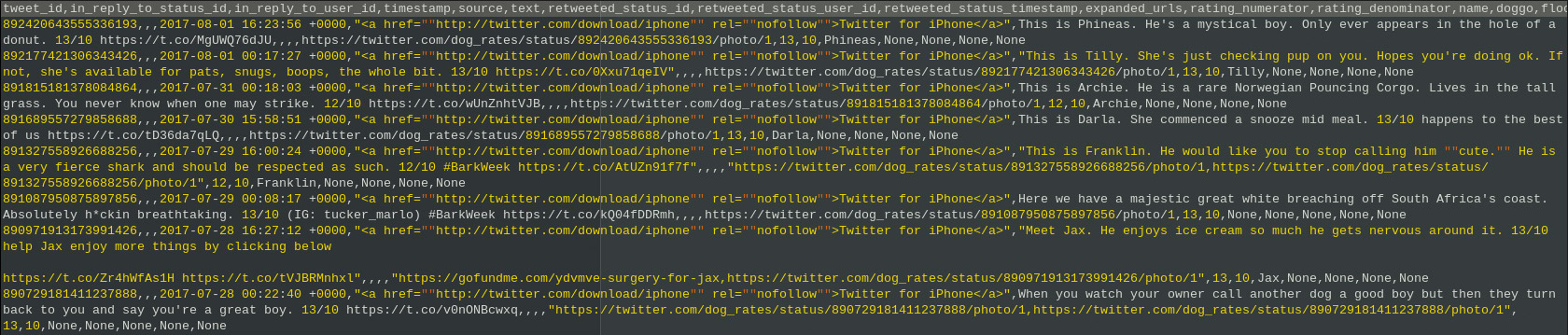 Abb. 9: CSV-Datei zusammen mit den Tweet-IDs eines Twitter-Accounts
Abb. 9: CSV-Datei zusammen mit den Tweet-IDs eines Twitter-Accounts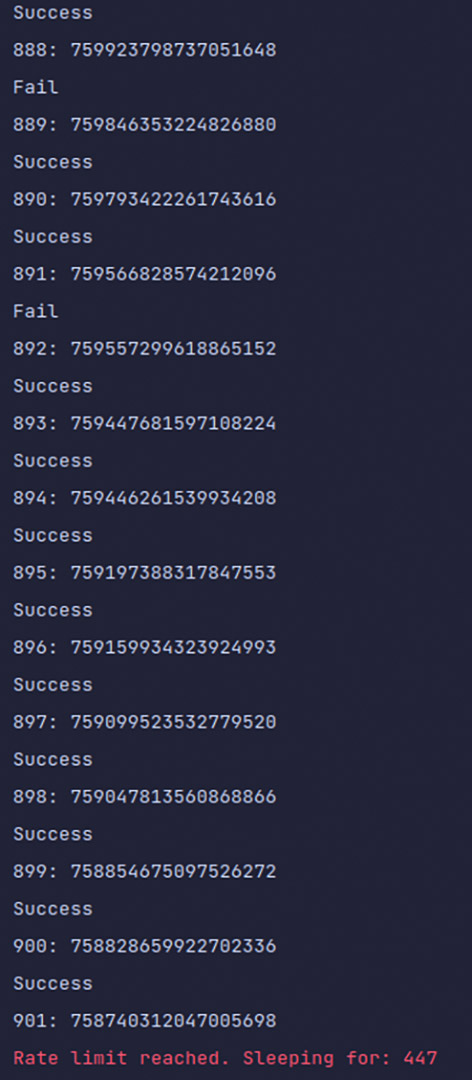 Abb. 10: Download von Tweets
Abb. 10: Download von Tweets Abgesehen vom Schreiben bietet Anzela Minosi Dienstleistungen auf Legiit.com an. Dort erstellt Anzela Datenanalysen, Datenbanksoftware, Python-Skripte sowie Kommandozeilentools für den Raspberry Pi. Bevor Anzela sich selbständig gemacht hat, war sie zehn Jahre lang in den Automobil-, Bildungs- und Telekommunikationsbranchen tätig, wo sie diverse IT-Tätigkeiten ausübte: Support, Softwaretests sowie Webentwicklung. Anzela verbringt ihre Freizeit gerne an der ligurischen Küste, fährt Fahrrad und spielt Retrospiele auf dem Raspberry Pi. Sie steht für Redaktionsprojekte sowie für persönliche Beratungsgespräche zur Verfügung.
Abgesehen vom Schreiben bietet Anzela Minosi Dienstleistungen auf Legiit.com an. Dort erstellt Anzela Datenanalysen, Datenbanksoftware, Python-Skripte sowie Kommandozeilentools für den Raspberry Pi. Bevor Anzela sich selbständig gemacht hat, war sie zehn Jahre lang in den Automobil-, Bildungs- und Telekommunikationsbranchen tätig, wo sie diverse IT-Tätigkeiten ausübte: Support, Softwaretests sowie Webentwicklung. Anzela verbringt ihre Freizeit gerne an der ligurischen Küste, fährt Fahrrad und spielt Retrospiele auf dem Raspberry Pi. Sie steht für Redaktionsprojekte sowie für persönliche Beratungsgespräche zur Verfügung. Abb. 1: Projektassistent von Android Studio für die Entwicklung von nativen Android-Apps
Abb. 1: Projektassistent von Android Studio für die Entwicklung von nativen Android-Apps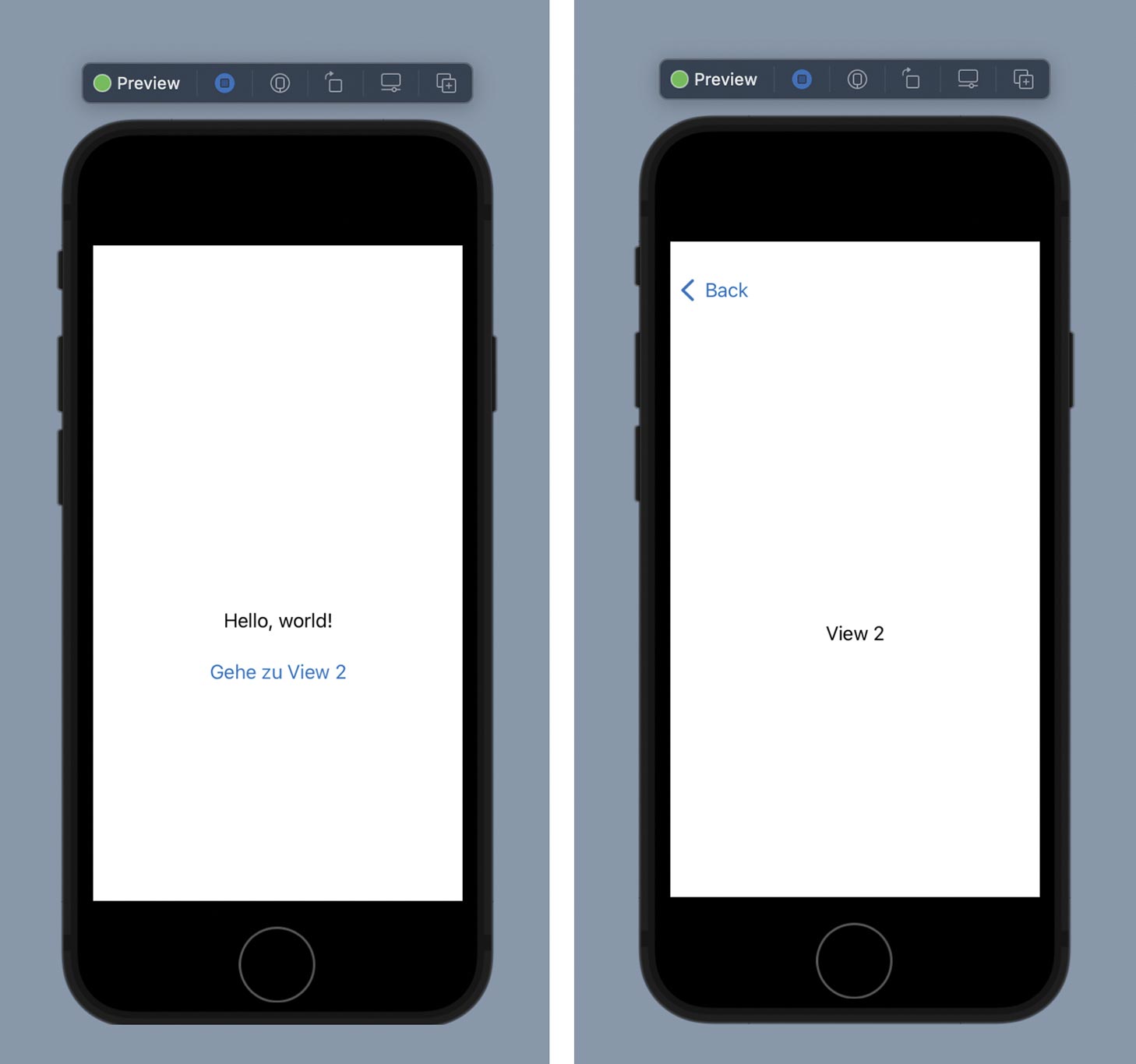 Abb. 2: Live-Preview von Xcode zur Entwicklung von nativen iOS-Apps
Abb. 2: Live-Preview von Xcode zur Entwicklung von nativen iOS-Apps Abb. 3: Hot Reload beschleunigt die Entwicklung von MAUI-Apps (Visual Studio for macOS)
Abb. 3: Hot Reload beschleunigt die Entwicklung von MAUI-Apps (Visual Studio for macOS) Abb. 4: Grafischer Designer in RAD Studio zur UI-Erstellung mit FireMonkey
Abb. 4: Grafischer Designer in RAD Studio zur UI-Erstellung mit FireMonkey Abb. 5: Wetter-App mit Onsen UI
Abb. 5: Wetter-App mit Onsen UI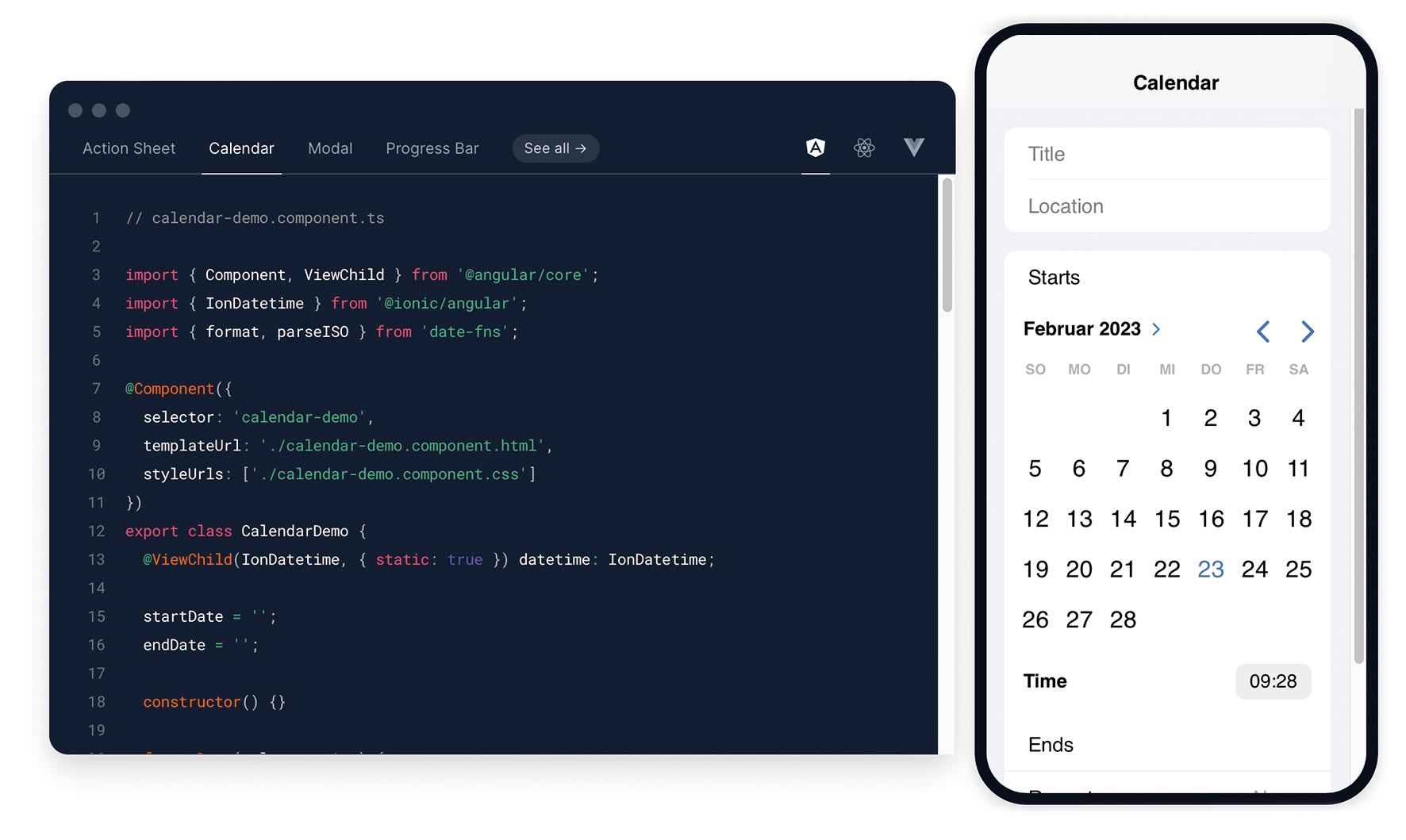 Abb. 6: App mit Kalender-Control mit dem Ionic-Framework
Abb. 6: App mit Kalender-Control mit dem Ionic-Framework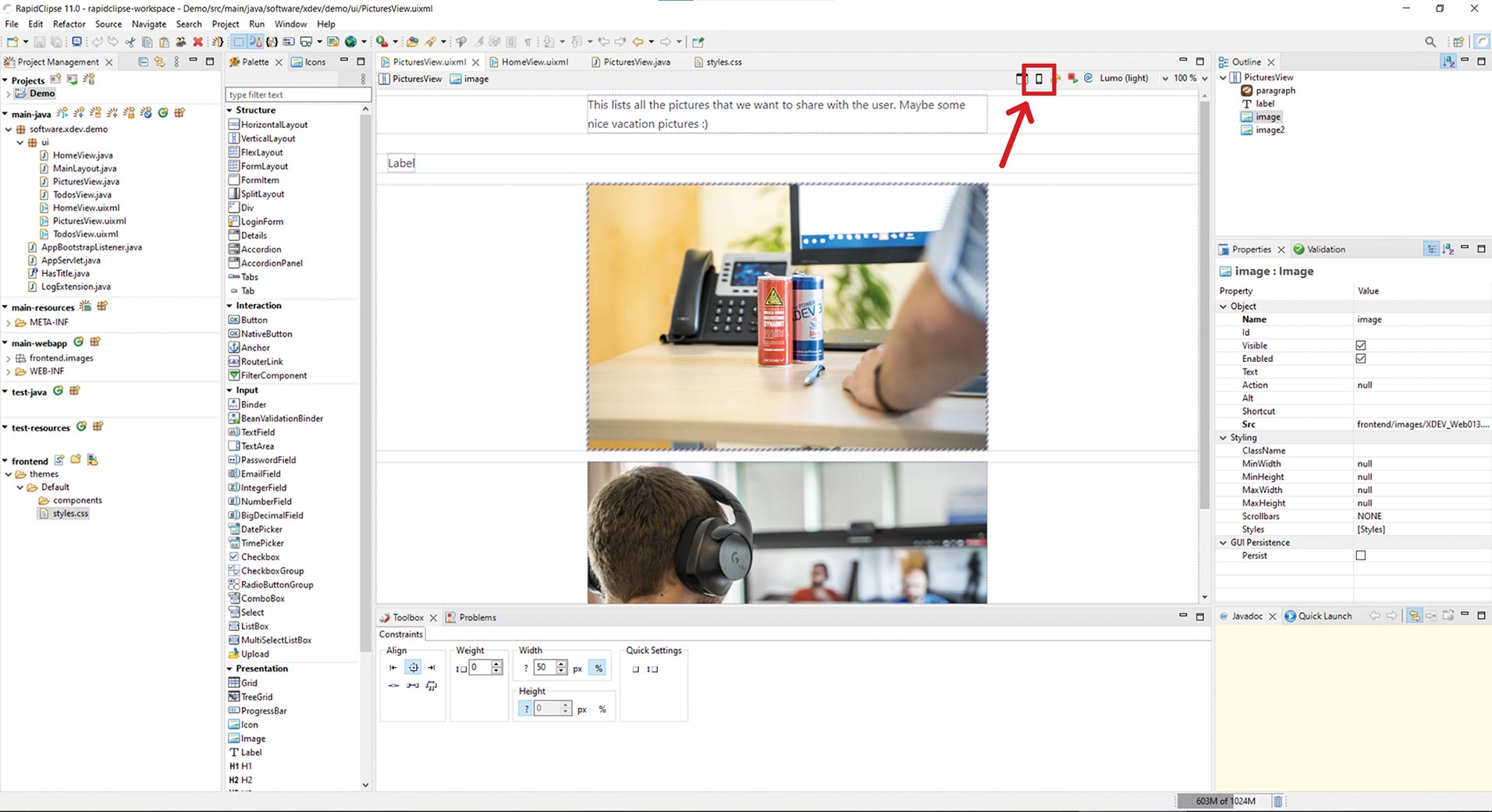 Abb. 7: Web-App mit RapidClipse und Vaadin erstellen und für mobile Geräte testen
Abb. 7: Web-App mit RapidClipse und Vaadin erstellen und für mobile Geräte testen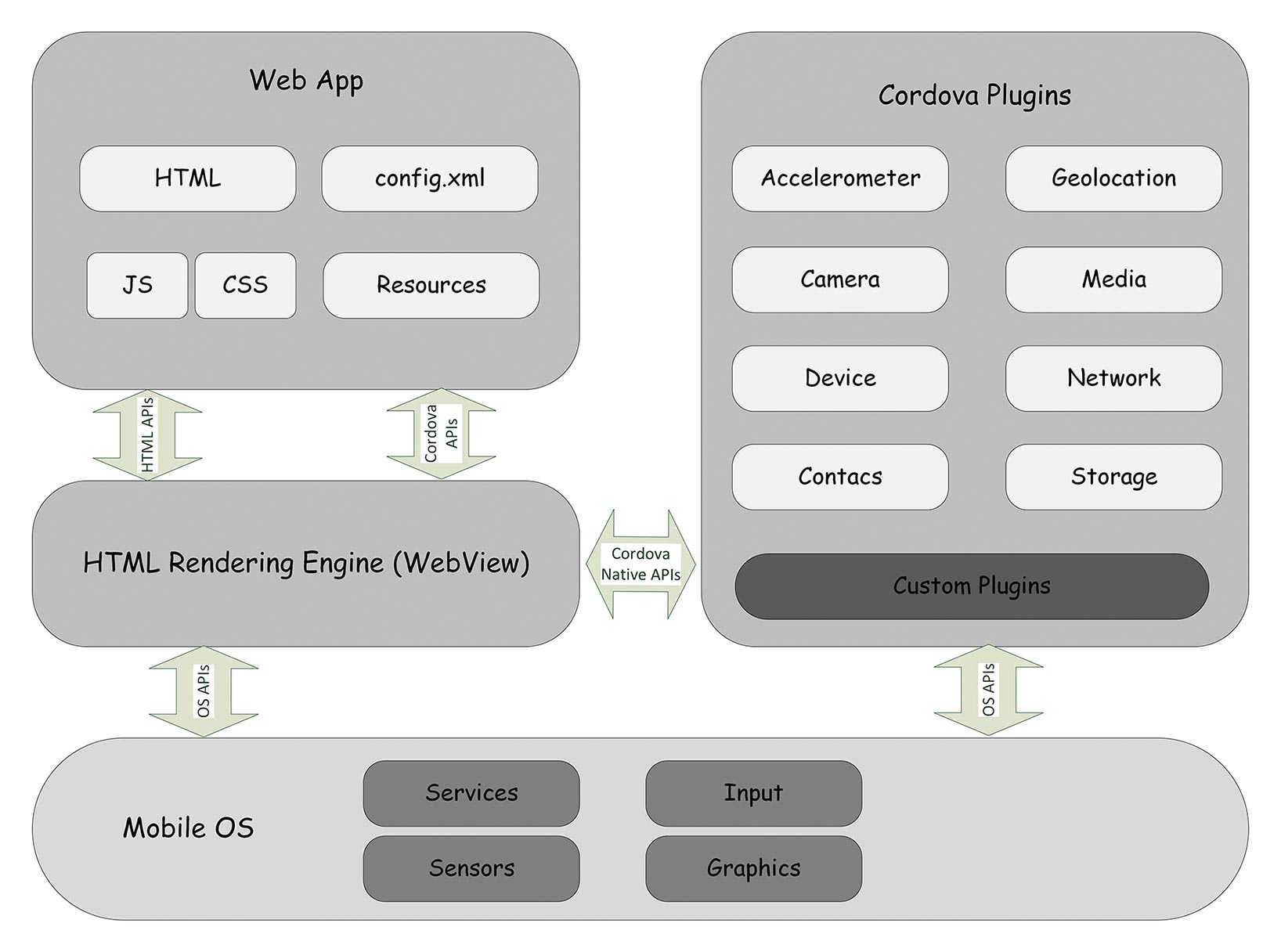 Abb. 8: Die Architektur von Cordova für hybride Apps
Abb. 8: Die Architektur von Cordova für hybride Apps Dr. Veikko Krypczyk ist Softwareentwickler, Trainer und Fachautor und u.a. auf die Themen WinUI 3 und .NET MAUI spezialisiert. Sein Wissen gibt er über Fachartikel, Seminare und Workshops gern an Interessierte weiter und steht mit seiner Expertise auch für eine individuelle Unterstützung in Projekten zur Verfügung.
Dr. Veikko Krypczyk ist Softwareentwickler, Trainer und Fachautor und u.a. auf die Themen WinUI 3 und .NET MAUI spezialisiert. Sein Wissen gibt er über Fachartikel, Seminare und Workshops gern an Interessierte weiter und steht mit seiner Expertise auch für eine individuelle Unterstützung in Projekten zur Verfügung. Elena Bochkor arbeitet am Entwurf und Design mobiler Anwendungen und Webseiten. Beginnend bei einer systematischen Nutzerforschung, über visuelle Prototypen bis hin zu einem barrierefreien Design gestaltet sie die User Experience moderner digitaler Produkte.
Elena Bochkor arbeitet am Entwurf und Design mobiler Anwendungen und Webseiten. Beginnend bei einer systematischen Nutzerforschung, über visuelle Prototypen bis hin zu einem barrierefreien Design gestaltet sie die User Experience moderner digitaler Produkte.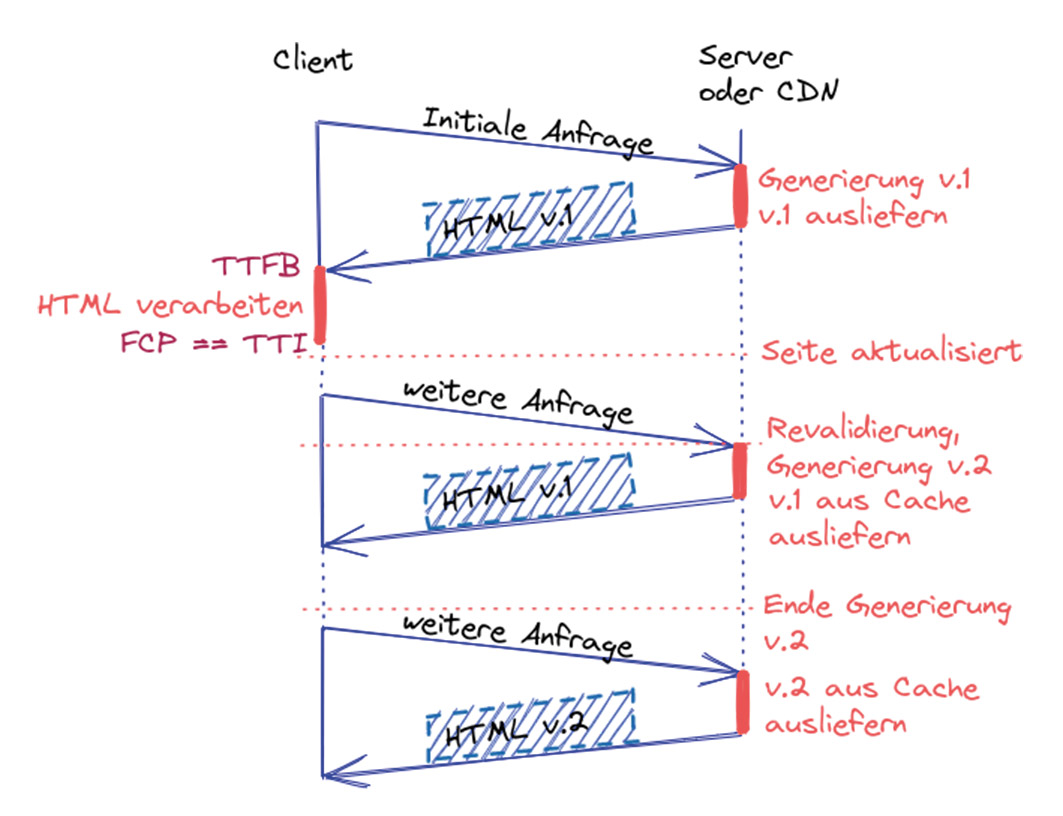 Abb. 1: Client-Server-Kommunikation von ISR mit Stale-while-revalidate-Mechanismus
Abb. 1: Client-Server-Kommunikation von ISR mit Stale-while-revalidate-Mechanismus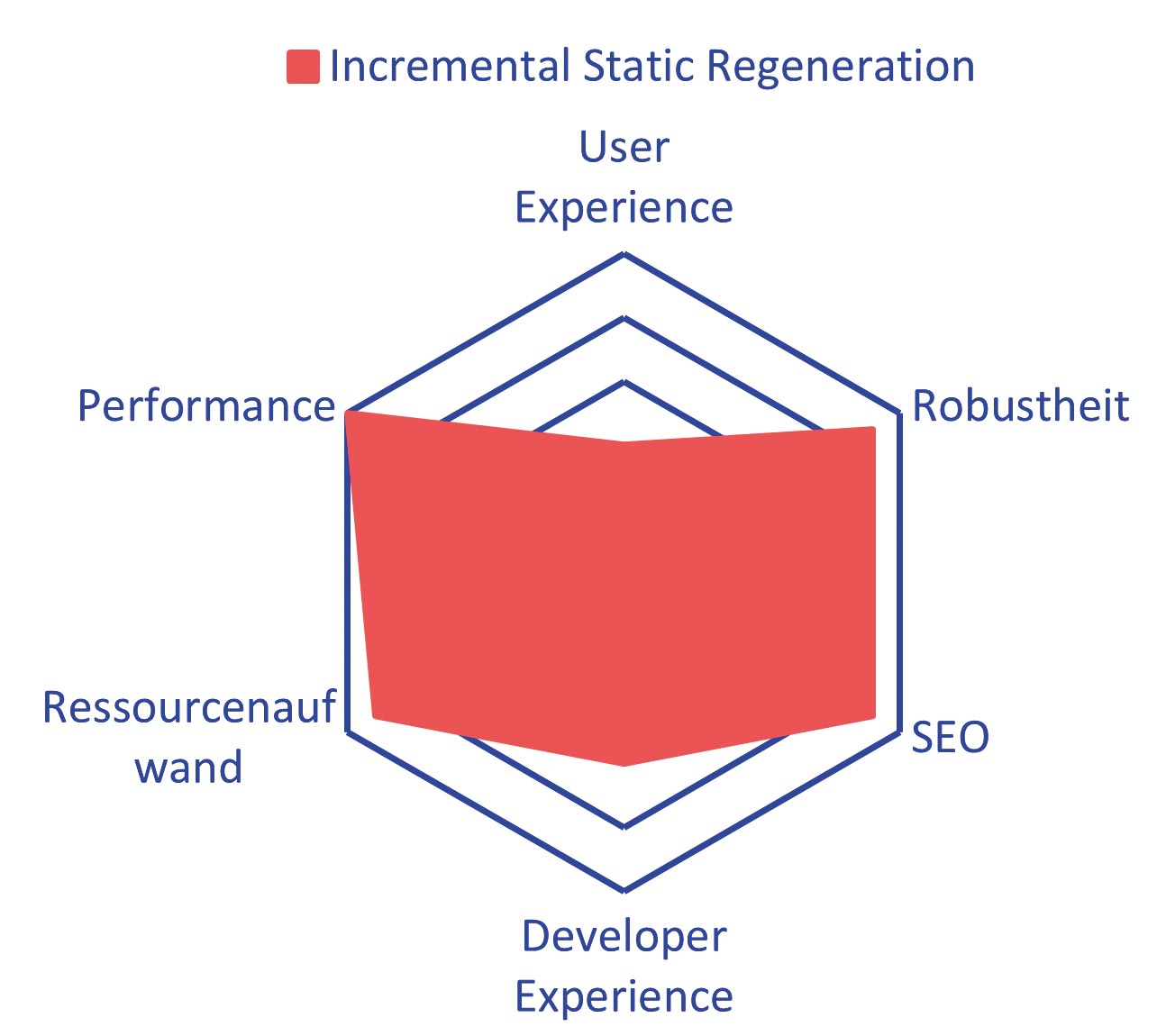 Abb. 2: Bewertung ISR: Developer und User Experience steigen im Vergleich zu SSG
Abb. 2: Bewertung ISR: Developer und User Experience steigen im Vergleich zu SSG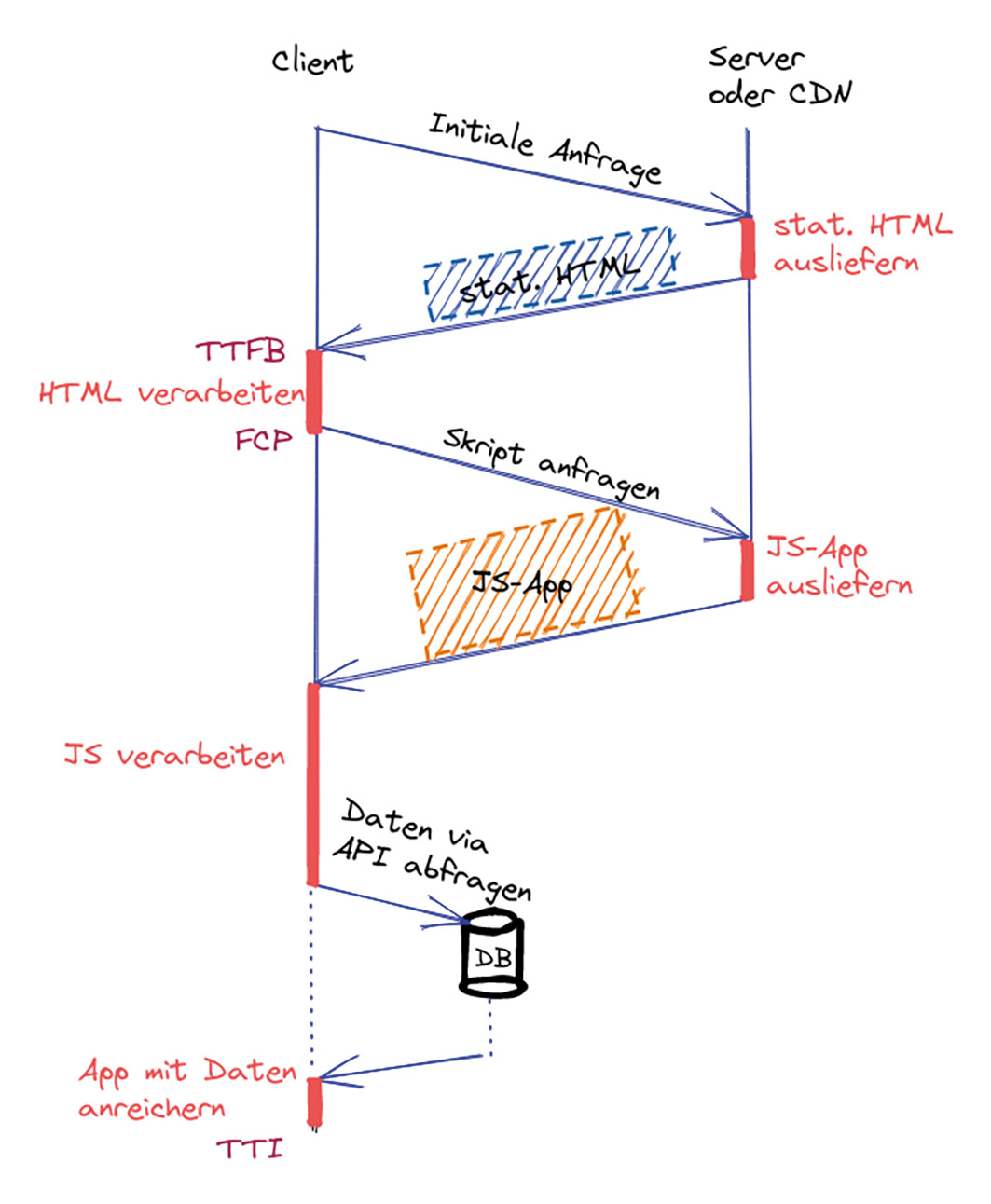 Abb. 3: Zuerst wird das statische HTML ausgeliefert, anschließend die SPA geladen
Abb. 3: Zuerst wird das statische HTML ausgeliefert, anschließend die SPA geladen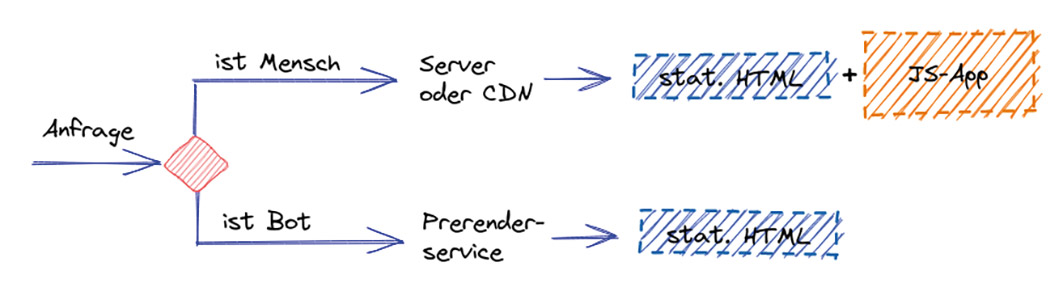 Abb. 4: Dynamic Rendering mit Prerender Service
Abb. 4: Dynamic Rendering mit Prerender Service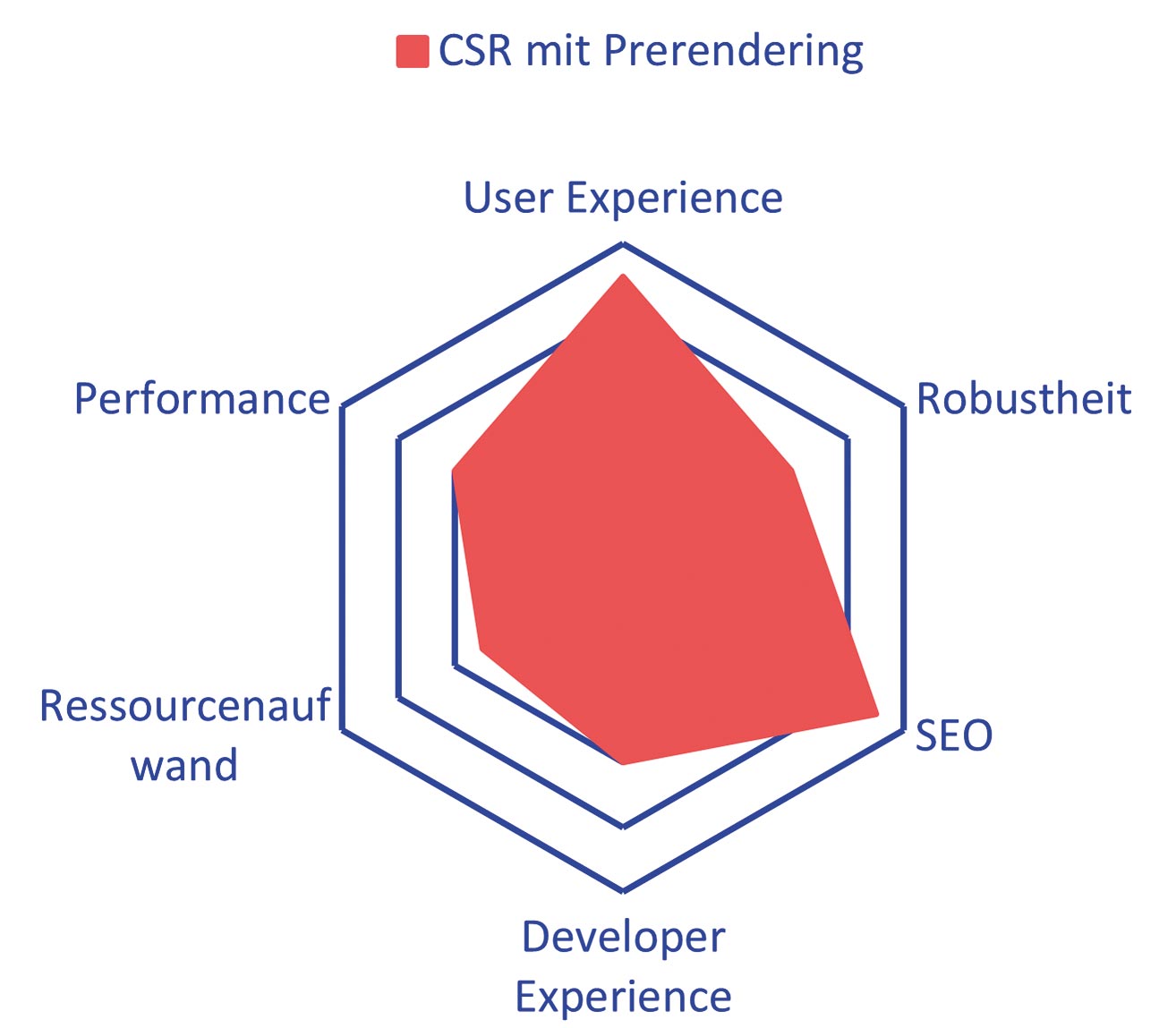 Abb. 5: Prerendering verbessert den SEO-Score erheblich
Abb. 5: Prerendering verbessert den SEO-Score erheblich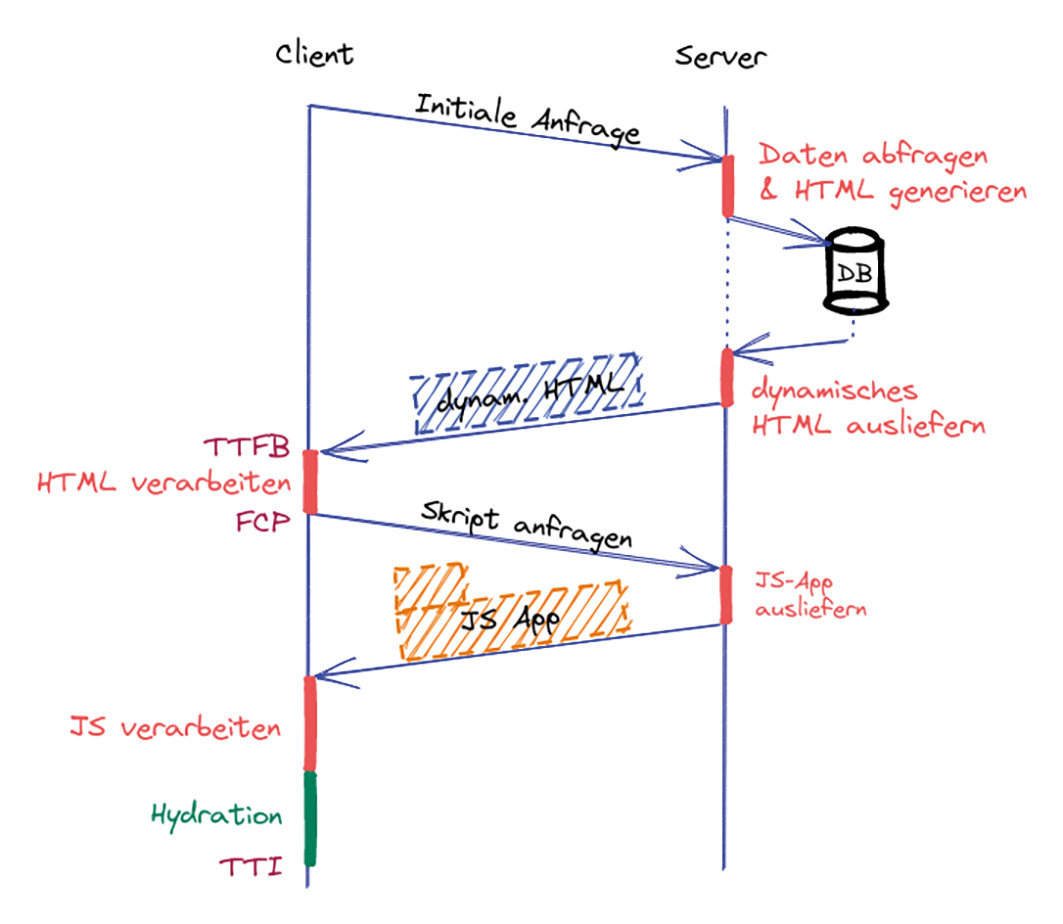 Abb. 6: Client-Server-Kommunikation – neu ist der Hydration-Schritt am Ende
Abb. 6: Client-Server-Kommunikation – neu ist der Hydration-Schritt am Ende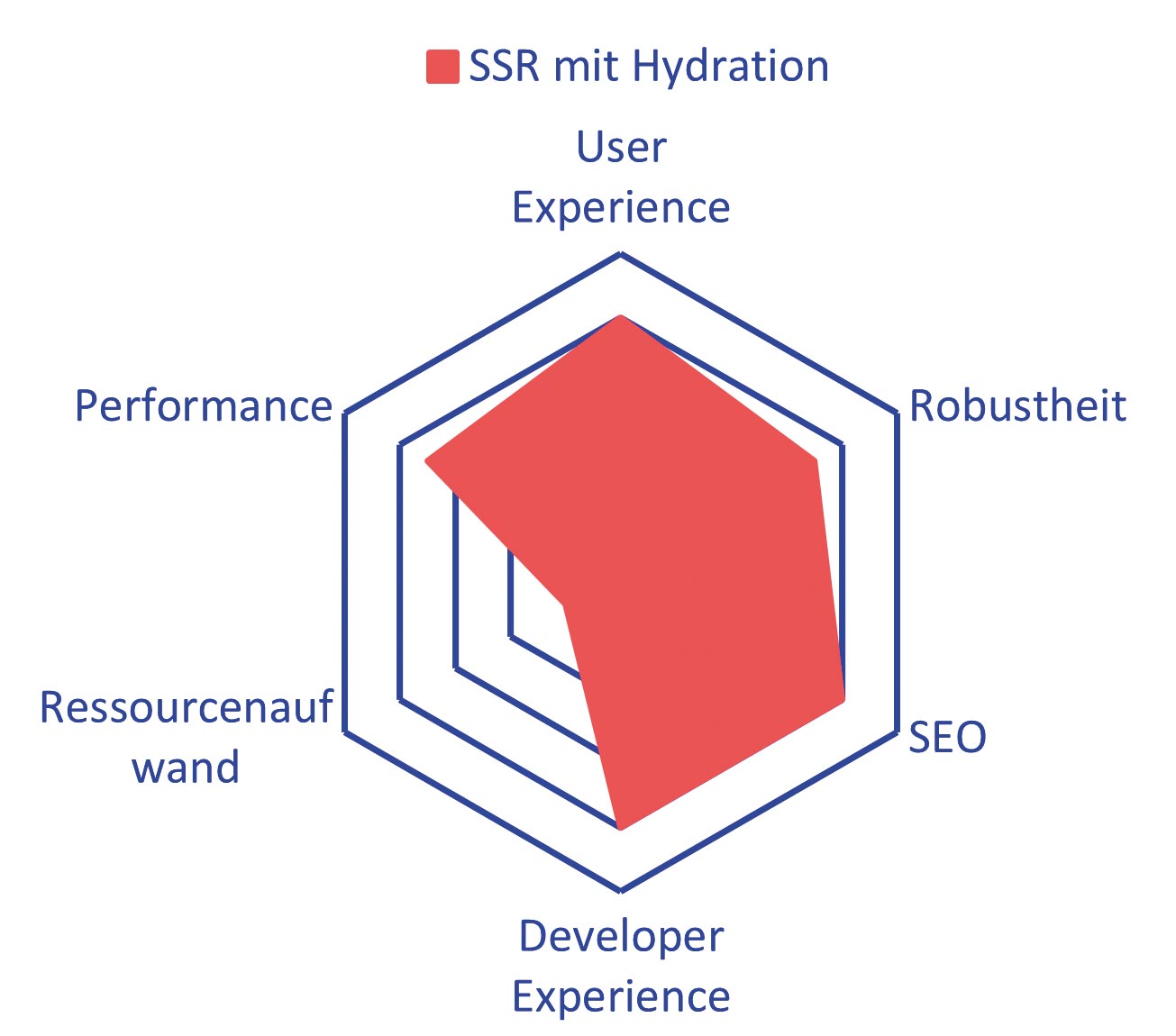 Abb. 7: Hydration ist ein guter Allrounder, wäre da nicht die verschwenderische Ressourcennutzung
Abb. 7: Hydration ist ein guter Allrounder, wäre da nicht die verschwenderische Ressourcennutzung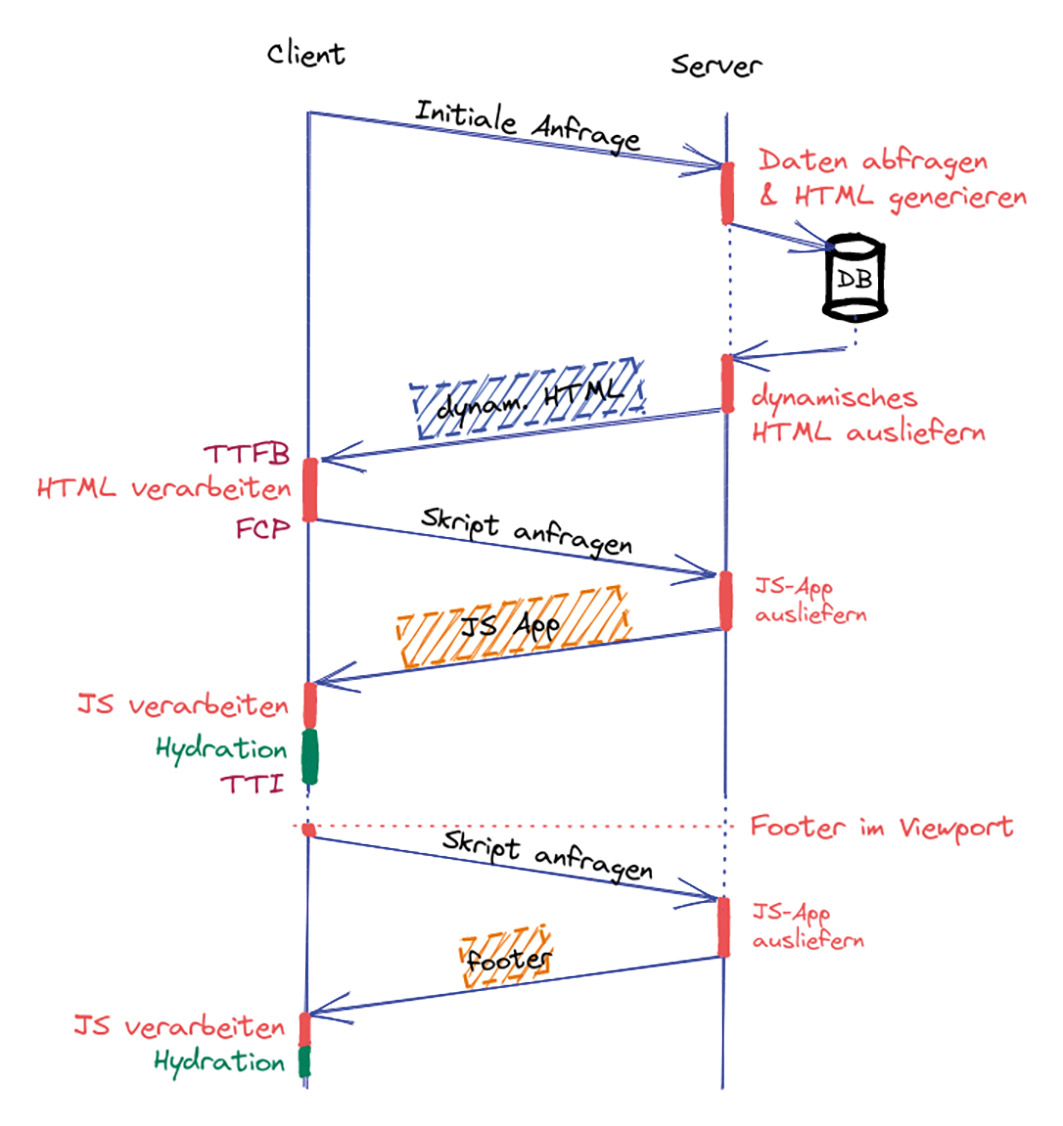 Abb. 8: Die Hydration für den Footer findet erst zu einem späteren Zeitpunkt statt
Abb. 8: Die Hydration für den Footer findet erst zu einem späteren Zeitpunkt statt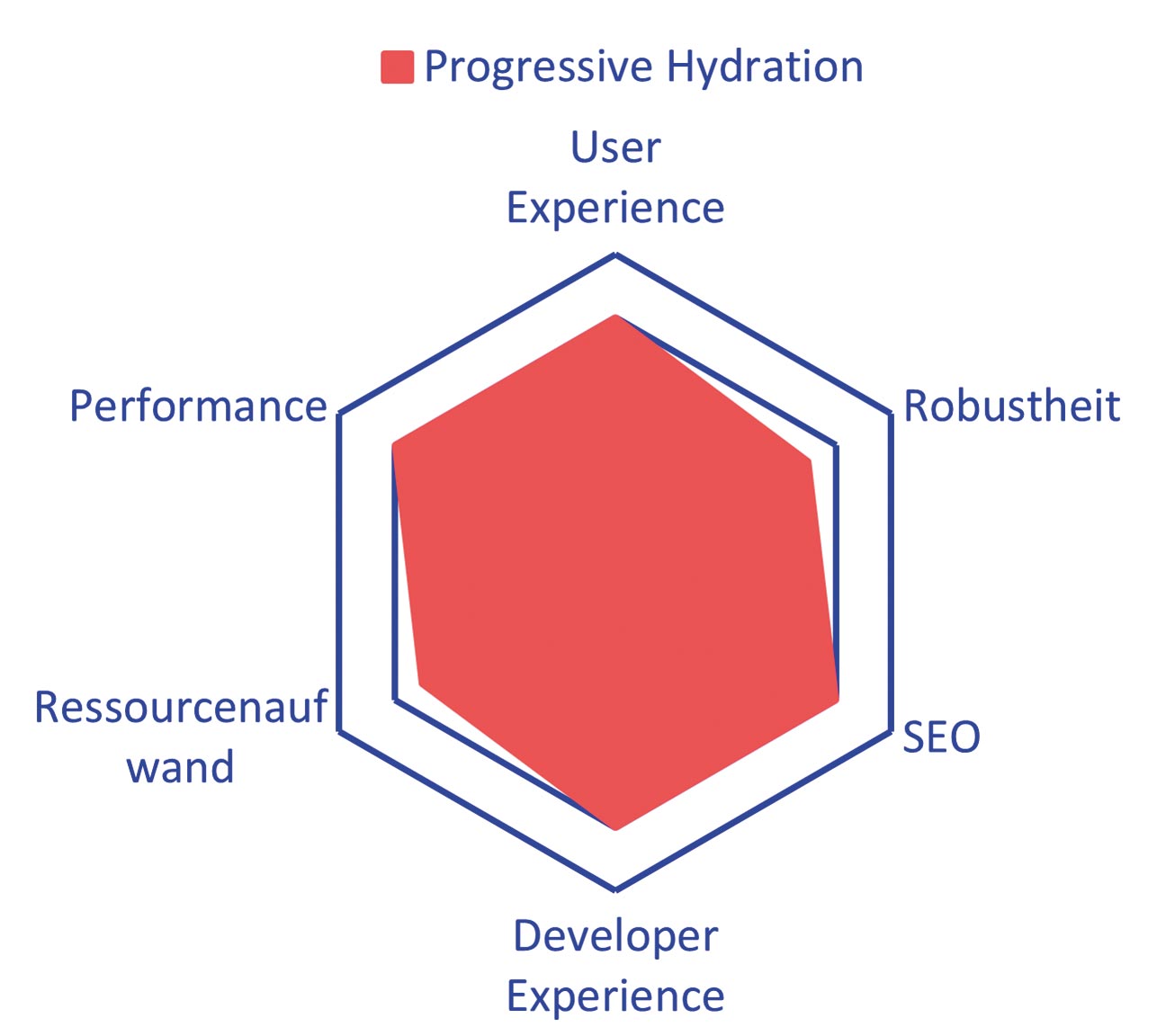 Abb. 9: Progressive Hydration reduziert den initialen Ressourcenaufwand
Abb. 9: Progressive Hydration reduziert den initialen Ressourcenaufwand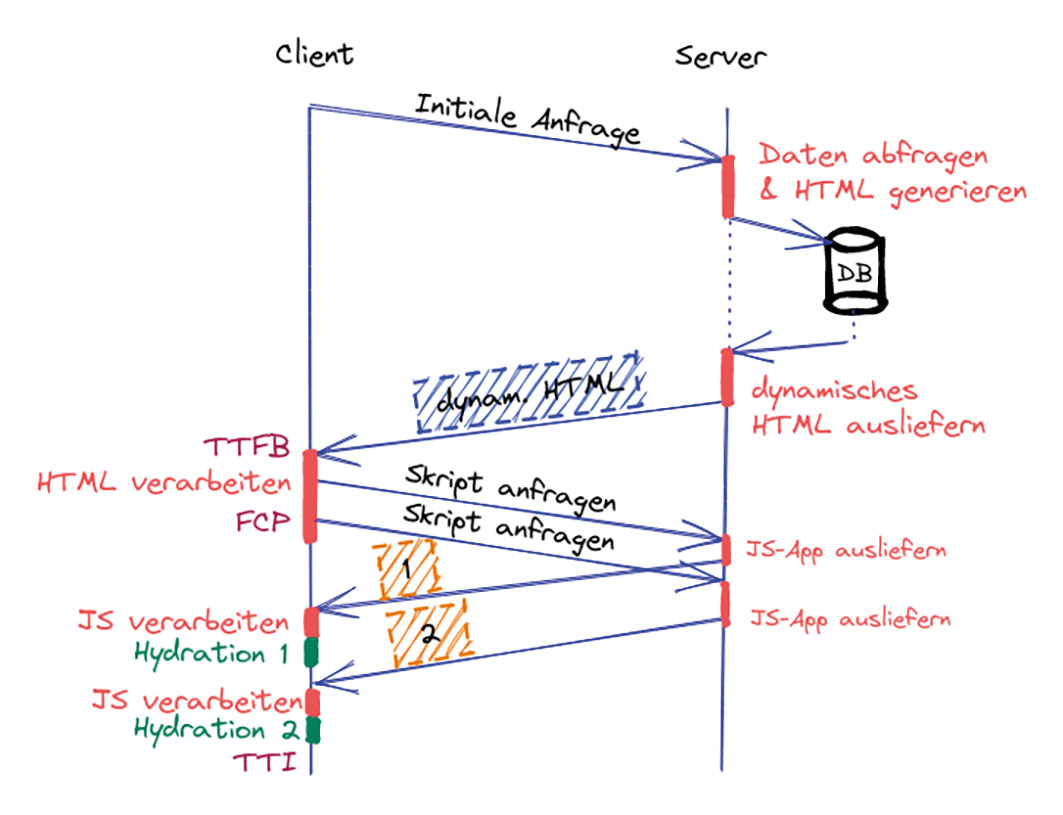 Abb. 10: Die Inseln werden unabhängig angefragt und verarbeitet
Abb. 10: Die Inseln werden unabhängig angefragt und verarbeitet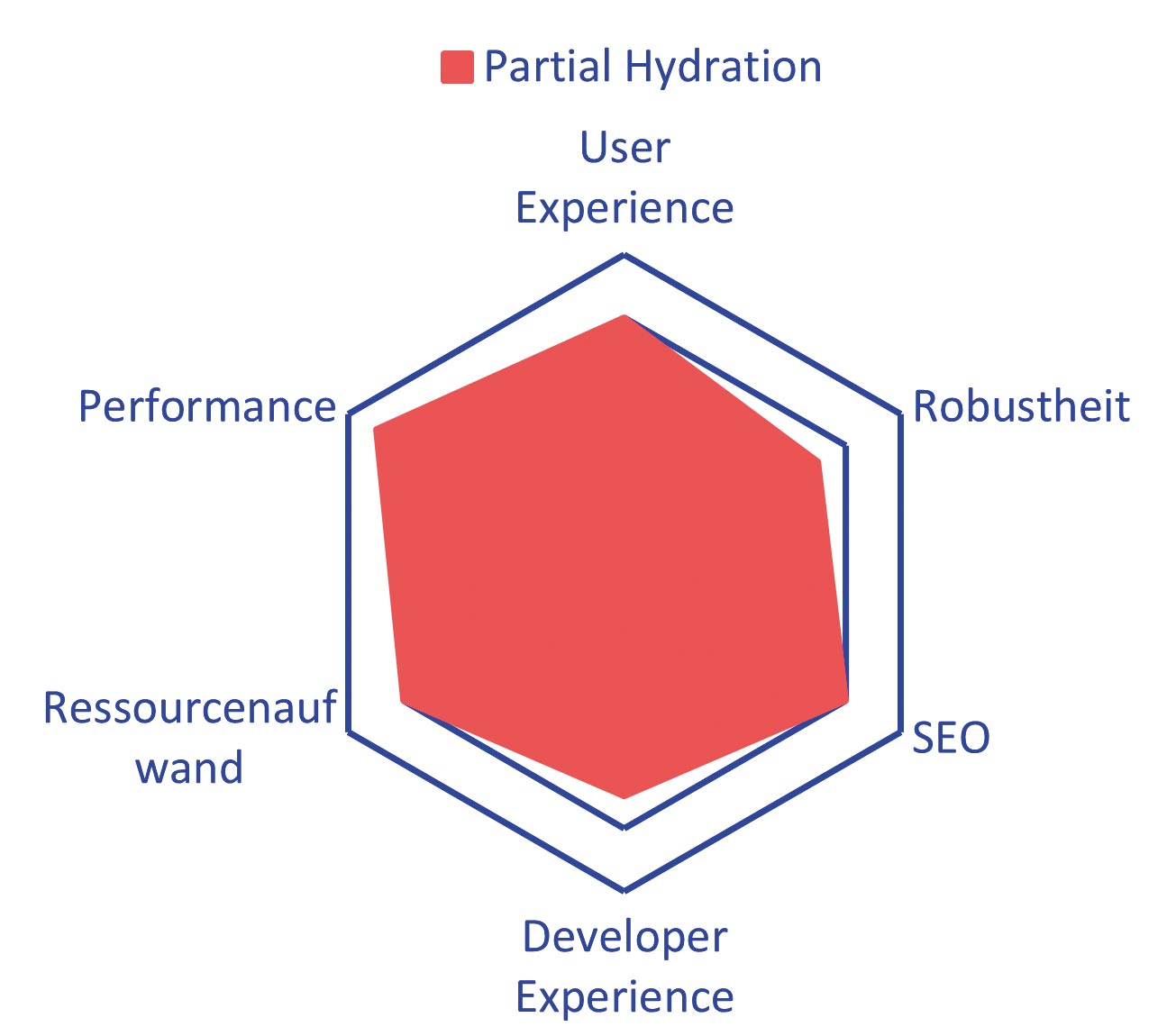 Abb. 11: Partielle Hydration steigert die Performance und reduziert unnötige Daten
Abb. 11: Partielle Hydration steigert die Performance und reduziert unnötige Daten Julian Schäfer arbeitet als Full-Stack-Softwareentwickler bei der synyx GmbH & Co. KG in Karlsruhe. Daneben beschäftigt er sich mit Webtechnologien und versucht, dieses Wissen auch während seines Projektalltags weiterzugeben.
Julian Schäfer arbeitet als Full-Stack-Softwareentwickler bei der synyx GmbH & Co. KG in Karlsruhe. Daneben beschäftigt er sich mit Webtechnologien und versucht, dieses Wissen auch während seines Projektalltags weiterzugeben.