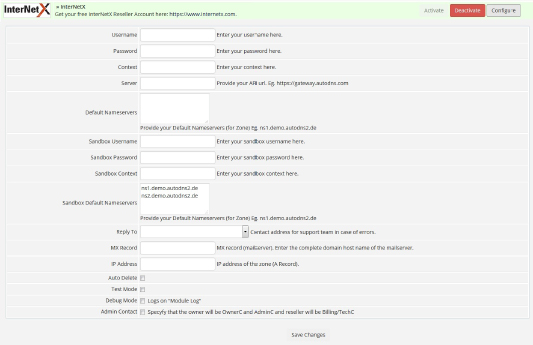
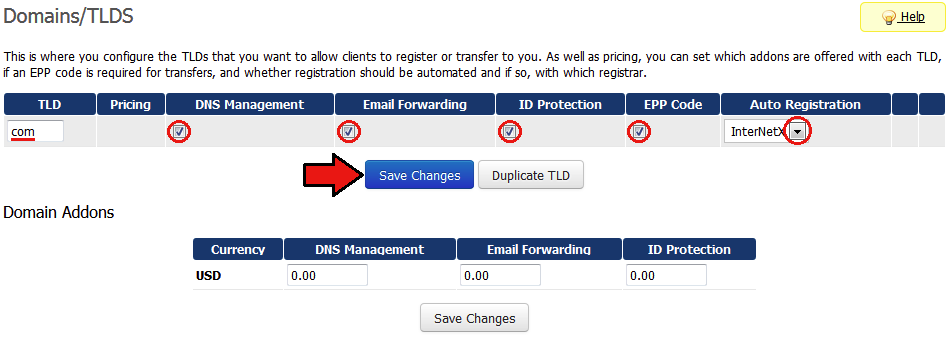
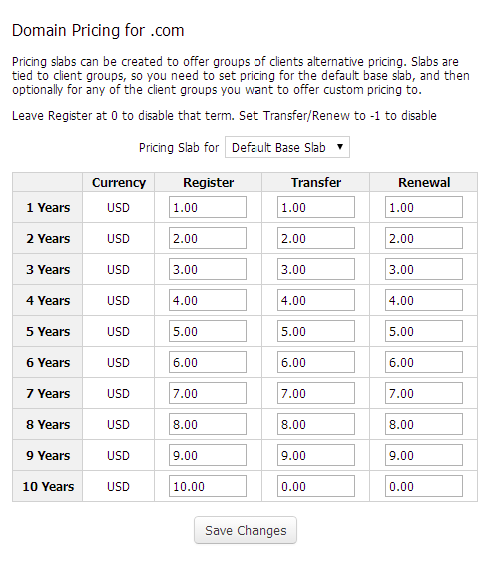
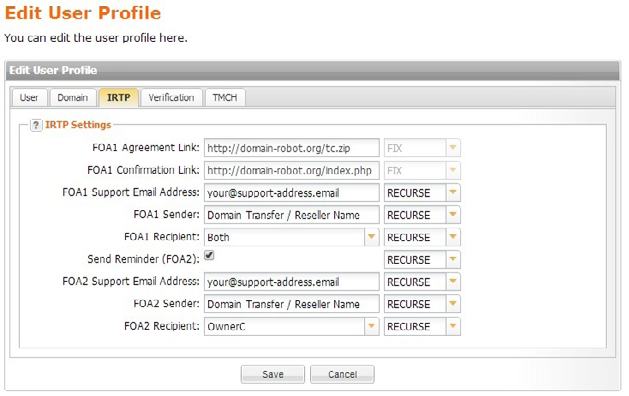
Datenanalysen mit R und der Google Analytics API – websiteboosting.com
Das Programm bzw. die Programmiersprache R erfährt in den letzten Jahren eine steigende Nachfrage. Neben dem erfreulichen Aspekt, dass es Open Source und damit komplett kostenfrei ist, kann R durch Pakete flexibel erweitert werden. Neben klassischen Datamining-Paketen und fortgeschrittenen…
Das Programm bzw. die Programmiersprache R erfährt in den letzten Jahren eine steigende Nachfrage. Neben dem erfreulichen Aspekt, dass es Open Source und damit komplett kostenfrei ist, kann R durch Pakete flexibel erweitert werden. Neben klassischen Datamining-Paketen und fortgeschrittenen Analysemethoden wie neuronalen Netzen existieren diverse Möglichkeiten, den Google-Kosmos mit R anzusprechen. Die Anbindung der API von Google Analytics, Search Console bzw. der komplette Zugriff auf Sheets/Docs sind exemplarische Beispiele hierfür. Daten können in beliebiger Kombination abgefragt, aufbereitet, analysiert und visualisiert/exportiert werden.
Analysen mit R – „flexibel wie ein Schweizer Taschenmesser“
R wird seit vielen Jahren durch eine große Community kontinuierlich weiterentwickelt. Vergleichbar mit Add-ins bei Excel können in R weitere Funktionen und Schnittstellen zum Standardsystem hinzugefügt werden. So schön diese Flexibilität und Leistungsstärke klingt (und tatsächlich ist), so unspektakulär ist die Nutzerfreundlichkeit des Systems: Eingabe von Programmcode anstelle klickbarer Icons und Mausklicks à la Excel. Was jetzt als Nachteil klingt, ist gleichzeitig ein Riesenvorteil: Sofern der Programmcode erstellt ist, kann dieser jederzeit „abgespielt“ werden, die entsprechenden Analysen/Visualisierungen dauern wenige Sekunden/Minuten und können unternehmensweit geteilt werden. Jeder Schritt ist transparent und durch den Einsatz von Variablen voll flexibel – einmalig die ID des Google Analytics-Kontos ausgeschaut und alle Analysen können automatisch von Neuem starten. R ist quasi ein „großes Excel-Makro“, das die Daten auf Befehl Schritt für Schritt verarbeitet.
Die Software R kann unter www.r-project.org/ kostenfrei heruntergeladen werden und ist nach der Installation sofort einsatzbereit. Es empfiehlt sich, zusätzlich RStudio zu installieren (www.rstudio.com/products/rstudio/download/), welches einen deutlichen Mehrwert in der Bedienung des Systems bietet (Abb. 1).
Abb. 1: RStudio „bettet“ die Software R benutzerfreundlich ein und macht die Bedienung komfortabler
Prinzipiell funktioniert R mittels Eingabe und sequenzieller Verarbeitung von Programmcode. Eingaben können sowohl in Form klassischer Rechenoperationen erfolgen (bspw. 3+3) als auch als Definition von Formeln, Funktionen, Variablen, Vektoren und Dataframes. Der Vorteil der Nutzung von Variablen ist, dass diese nach Definition zur gesamten Laufzeit zur Verfügung stehen und im weiteren Verlauf darauf zurückgegriffen werden kann. Füllt man bspw. die Variable „ga_id“ (Variablennamen sind frei wählbar) mit der Datenansichts-ID von Google Analytics und verweist im weiteren Verlauf der Berechnungen auf die Variable anstelle einer fix definierten Nummer, kann die identische Analyse durch Neudefinition der Variable flexibilisiert werden. Variablen werden in R mittels der Syntax „Variablenname <- Variableninhalt“ definiert.
googleAnalyticsR – das flexible R-Paket
Damit R auf die API von Google Analytics zugreifen kann, muss ein Paket installiert werden (genereller Befehl: install.packages(„Paketname“). Die Installation des Pakets erfolgt nach Befehlseingabe binnen Sekunden, da die Pakete automatisch aus dem Internet geladen werden. Die Erweiterung „dependencies = TRUE“ bewirkt, dass passende Pakete zusätzlich installiert werden, insb. googleAuthR zur OAuth-Authentifizierung des Google-Nutzerkontos mit R (siehe Abb. 2).
Abb. 2: Einfache Installation von googleAnalyticsR nebst weiteren Paketen direkt in R
Nachdem die gewünschten Pakete installiert wurden, stehen diese prinzipiell zur Verfügung. Damit sie tatsächlich auch genutzt werden können, müssen sie mit dem Befehl library(„Paketname“) geladen werden. Das heißt, nach Absetzen des Befehls „library(“googleAnalyticsR“)“ besteht eine Verbindung von R zur Google Analytics API. Der Befehl „ga_auth()“ bzw. „gar_auth()“ aus dem Paket googleAuthR ermöglicht die Authentifizierung von R mit dem jeweiligen Google-Konto über das OAuth-Verfahren. Ein erstmaliger Aufruf leitet zum Google-Konto-Log-in nebst Angabe der übergebenen Berechtigungen (siehe Abb. 3).
Abb. 3: Zugriff des R-Pakets auf Google-Konto
Sofern das Google-Konto bei Google Analytics mindestens das Recht „Bearbeiten“ auf eine Property hat, kann im weiteren Verlauf direkt die Google API genutzt werden. Wie angesprochen ist es sinnvoll, mit Variablen zu arbeiten und die gewünschte Auswahl an Metriken und Dimensionen in Vektoren zu speichern. Der Befehl „ga_account_list()“ erzeugt eine Übersicht aller Analytics Propertys nebst Datenansichten (Views) im jeweiligen Google-Konto. Als Beispiel kann eine Variable „account_list“ mit genau dieser Übersicht befüllt (Befehl account_list <- ga_account_list()) und anschließend aufgerufen werden (siehe Abb. 4). Auf Basis dieser Liste kann bspw. eine Variable „ga_id“ dynamisch mit der zweiten Datenansicht befüllt werden. Hierzu wird das Feld viewId mit dem Dollarzeichen ($) aus account_list angesprochen und die zweite Position adressiert. Alternativ könnte die Variable ga_id selbstverständlich direkt mit der jeweiligen View-Nummer befüllt werden.
Abb. 4: R-Befehle zum Abruf von R
Mit dem Befehl „google_analytics“ wird die API angesprochen und die entsprechenden Werte werden in R ausgegeben. Sofern bspw. der Datumbereich sowie die gewünschten Metriken und Dimensionen nebst der View-ID im Befehl google_analytics übergeben werden, werden die Daten unmittelbar abgerufen. Aufgrund des Abrufs der Daten über die API kann ggf. das Sampling von Daten umgangen werden. Hierzu bedarf es beim Aufruf des Befehls google_analytics der Ergänzung um den Parameter anti_sample = TRUE. Die Funktion teilt dabei den API-Aufruf in mehrere Teilaufrufe auf, damit möglichst ungefilterte Daten über die API abgerufen werden. Weiterhin kann mit dem Parameter max = „Zahl“ die maximale Anzahl von abzurufenden Daten limitiert werden (siehe Abb. 5).
Tipp: Es besteht für Google Analytics ein sog. „Dimensionen- und Metriken-Explorer“, der anzeigt, welche Dimensionen und Metriken generell kombiniert werden dürfen und wie die entsprechenden Felder in der API heißen (bspw. ga:bounceRate für die Absprungrate in %): einfach.st/gareferenzen.
Das Paket googleAnalyticsR nutzt ein allgemeines Kontingent an API-Aufrufen von Google Analytics. Bei intensiver Nutzung und zur Sicherstellung der Verfügbarkeit sollte ein eigenes API-Kontingent über Google Developers beantragt werden (https://console.developers.google.com). Nach Registrierung bei Developers stehen diverse Google APIs zur Verfügung. Als Anpassung in R müssen vor der Authentifizierung die Client-ID sowie der geheime Clientschlüssel als Option angegeben werden (options(googleAuthR.client_id = „xx.apps.googleusercontent.com“) sowie options(googleAuthR.client_secret = „xx“). Beide Informationen sind nach der Registrierung und Aktivierung der Analytics API abrufbar. Bei Google Analytics bietet die API 50.000 Abfragen pro Tag/User bzw. alle 100 Sekunden 100 Abfragen.
Flexibler Export und Datenvisualisierungen mit ggplot2
Sofern das Ergebnis des Abrufs mittels „google_analytics“ in eine Variable/Dataframe gespeichert wird, können neben der Durchführung statistischer Auswertungen (bspw. summary(„Variable“) die Daten in ein spezifisches Dateiformat gespeichert und dann mit anderen Programmen weiterverarbeitet werden. Eine CSV-Datei wird über den Befehl „write.csv“ erzeugt (siehe Abb. 5).
Tipp: Perfekt harmoniert R auch mit Google Sheets, was damit mittelbar eine nachgelagerte Datenvisualisierung mit Google Data Studio ermöglicht. Das Szenario wäre folgendes: Daten werden aus Google Analytics und anderen Quellen in R analysiert und verarbeitet, automatisch über das R-Paket „googlesheets“ in ein Google Spreadsheet übertragen und anschließend über Data Studio visualisiert und ggf. mit weiteren Datenquellen ergänzt.
Abb. 5: Daten aus der API in R analysieren und als .csv speichern
R hat herausragende Möglichkeiten der Datenvisualisierung. Es existiert eine Vielzahl an Paketen, welche die Daten mit weiteren Analysen grafisch anreichern. Pakete wie „RColorBrewer“ erzeugen u. a. Heatmaps als Datenvisualisierung. Das Paket „ggplot2“ (install.packages(“ggplot2“) sowie Aktivierung über library(“ggplot2“)) bietet Schaubilder, die in Excel nicht existent sind. Mittels des Befehls geom_boxplot wird bspw. ein Boxplot erstellt, geom_line / geom_smooth erzeugt ein Liniendiagramm nebst nicht linearer Trendlinie (siehe Abb. 6).
Abb. 6: Datenvisualisierungen mit dem Paket ggplot2
Tipp: Die Visualisierung bzw. Berichterstellung ist in R sehr umfassend durch sogenanntes R Markdown nutzbar. Es wird einmalig der Programmcode erstellt bzw. ein Bericht konzipiert, welcher anschließend als HTML-Seite, PDF oder Word-Dokument ausgegeben wird. Damit sind aufwendiges „Exceln“ und formatieren obsolet, die Corporate Identity ist in hohem Maße in den Berichten standardisierbar.
Richtig interessant werden Analysen und Visualisierungen, wenn diese auf Rohdaten beruhen. Mittels der Analytics API können viele Informationen verarbeitet werden, die es später zu clustern gilt. Eine sinnvolle Ergänzung ist deshalb, die Google-Analytics-Daten durch benutzerdefinierte Dimensionen zu erweitern. Wird jedem Datensatz ein exakter Zeitstempel mitgegeben, jede Session mit einer Session-ID in den Daten ergänzt sowie die Cookie-ID als Klammer für den Besucher verstanden, so könnte eine Customer-Journey-Analyse mit Rohdaten erfolgen. Simo Ahava hat in seinem Blog eine detaillierte Anleitung für diese benutzerdefinierten Dimensionen erstellt (http://einfach.st/simohava). Es ist sehr ratsam, vor der Integration den jeweiligen Datenschutzverantwortlichen zu konsultieren!
In diesem Sinne: Geben Sie R eine Chance! Im ersten Schritt hat es eine „Old-School“-Anmutung, da Befehle über eine Console eingegeben werden müssen. Mit Neugier und Training werden die Abläufe Tag für Tag vereinfacht und Webanalyse bzw. Datenvisualisierung kann wirklich auf „Knopfdruck“ erfolgen – so besteht viel mehr Freiraum und Zeit, über die Ergebnisse nachzudenken bzw. diese zu interpretieren, anstatt Zeit für die Datenaufbereitung ineffizient zu vergeuden. Und zuallerletzt: Das System wird permanent (kostenlos) weiterentwickelt– für jede Anforderung existiert bestimmt ein Paket.
Noch ein Literaturhinweis: Das kostenlose englischsprachige E-Book „Using Google Analytics with R“ von Michal Brys ist unter http://michalbrys.com/book/ in diversen Formaten abrufbar und bietet einen hervorragenden Einstieg in die Nutzung der Analytics API!
Das Powertool R – hands-on!
Das Powertool R – hands-on! – websiteboosting.com
Da der Beitrag von Tobias Aubele in der letzten Ausgabe (Datenabzug von Google Analytics über das Tool R) auf große Resonanz gestoßen ist, möchten wir all denjenigen hier, die noch keinen Kontakt zu dem kostenlosen Tool R hatten bzw. ihn bisher gemieden haben, eine kurze und leicht verständliche…
Da der Beitrag von Tobias Aubele in der letzten Ausgabe (Datenabzug von Google Analytics über das Tool R) auf große Resonanz gestoßen ist, möchten wir all denjenigen hier, die noch keinen Kontakt zu dem kostenlosen Tool R hatten bzw. ihn bisher gemieden haben, eine kurze und leicht verständliche Einführung geben. Keine Sorge, es wird in diesem Beitrag nicht zu technisch. Und die Beispiele sind so gehalten, dass Sie einen schnellen und effizienten Einblick in das Tool bekommen, sofern Sie nicht nur lesen, sondern sich einfach selbst mal an die Tasten setzen. Wie bei vielen mächtigen Tools ist es oft die Anfangshürde der Bedienung, an der man scheitert. Gelingt es, diese zu überwinden, eröffnet sich wie so oft ein wahres Eldorado an Vereinfachungen für die eigene Arbeit und/oder zusätzliche Möglichkeiten für nötige Analysen oder die Gewinnung wichtiger Erkenntnisse. Eigentlich ist R als Statistiktool konzipiert und bekannt. Aber im Lauf der Jahre ist durch eine schier unendliche Anzahl an Funktionsbibliotheken die Anwendungsbreite förmlich explodiert. So kann man z. B. Ergebnisse automatisch in HTML-Webseiten übertragen oder Textmining betreiben. Zwei zentrale Stärken von R sind wohl zum einen die Anzahl der Daten, die man damit sehr schnell verarbeiten kann. Zum anderen kann man aber alles, was man für ein Projekt oder eine Analyse experimentell durchgeführt hat, auf Knopfdruck ganz oder teilweise mit anderen Daten wiederholen. Richtig eingesetzt, kann das gerade im Online-Marketing sehr viel Zeit und damit Kosten sparen. Natürlich sind Sie nach der Lektüre des Beitrags kein R-Spezialist – aber dann können Sie für sich entscheiden, ob Sie dem Tool eine Chance geben und sich etwas tiefer darin eingraben. Im Web gibt es viele Tutorials, bei Udemy einen deutschen Kurs dazu und am Ende dieses Beitrags finden Sie Literatur für den Einstieg und für Fortgeschrittene zum Thema Data Science. Erwarten Sie persönlich, dass die Menge der Daten künftig an Ihrem Arbeitsplatz eher zunehmen wird? Wird die Zahl der Datenquellen eher größer und haben diese wahrscheinlich unterschiedliche Strukturen? Schreitet die Digitalisierung bei Ihnen gut voran? Dann, ja dann kann es sich wirklich lohnen, sich frühzeitig mit so einem Tool auseinanderzusetzen, das Sie bei der Bewältigung gut unterstützt. Und wie immer gilt: Wer früher dran ist, kann den anderen die lange Nase zeigen, während die sich wundern, wie man das Kaninchen mal wieder aus dem (neuen) Hut gezaubert hat …
Was ist R überhaupt?
R selbst ist eigentlich eher eine Programmiersprache als ein Tool und ähnelt Python. Über das ebenfalls kostenlose RStudio erhält R eine komfortable und übersichtliche Benutzeroberfläche, die Einsteigern etwas den Schrecken nimmt. Ursprünglich für statistische Anwendungen gedacht, ist R mittlerweile sehr viel mehr und hat große Stärken, wenn man Daten auswerten, umwandeln oder visualisieren muss. Sie möchten wissen, wie oft das Wort „Westernstiefel“ auf einer bestimmten Webseite vorkommt? Kein Problem – mit den entsprechenden kostenlosen Erweiterungspaketen (Librarys) ist das mit einer Befehlszeile erledigt. Sie brauchen einen Überblick über die Struktur der Shop-Umsatzdaten des letzten Jahres? Dazu laden Sie die Umsatzdatei ein und der Befehl „sum“ gibt Ihnen im Bruchteil einer Sekunde statistisch relevante Informationen. Vorausgesetzt, Sie wissen, was ein Median oder eine Standardabweichung ist. Mit anderen Worten sehen Sie mit einer Zeile Code, ob z. B. der häufig falsch verwendete Mittelwert als Kennzahl bei Ihren Daten überhaupt aussagekräftig ist.
„Windows, Mac oder Linux? Geht alles!“
Wer tiefer einsteigt, kann mit R auch Anwendungen für Machine Learning fahren oder Data Mining betreiben, indem man im einfachsten Fall über die Daten Regressionsanalysen laufen lässt. Bereits mit zwei bis drei Befehlszeilen kann man sich durch Umwandlung von Daten einen visuellen Überblick über mögliche Abhängigkeiten verschaffen. Ist der Umsatz tatsächlich vom Wetter abhängig und wenn ja, wie stark? Wie wirken sich Preisveränderungen von Mitbewerbern auf den eigenen Absatz aus und wie eine Erhöhung des Ads-Budgets? Gibt es Abhängigkeiten, die man bisher noch gar nicht auf dem Schirm hatte und wo es sich lohnt, tiefer zu graben?
R und RStudio sind für Windows, Mac OS und Linux verfügbar.
Was ist das Besondere an R?
Wie schon erwähnt, machen die vielen Funktionsbibliotheken (Librarys) R erst richtig nützlich und breit anwendbar. Diese lassen sich sehr simpel bei Bedarf einbinden und stehen fortan im Tool zur Verfügung. Damit kann man dann z. B. bestimmte Dateiformate lesen und erzeugen, Daten direkt in HTML-Vorlagen ausgeben, Anbindungen an verschiedene Datenbanken managen, linguistische Analysen durchführen oder auch Marktforschung betreiben. Und das Ganze völlig kostenlos, sehr stabil und performant.
Eine Besonderheit gegenüber anderen Programmiersprachen liegt darin, dass man in R mit sog. Vektoren arbeitet. Das erleichtert den Umgang mit Daten und es sind nicht wie sonst gesondert programmierte Schleifen nötig. Einen Vektor kann man sich als komplette Zeile (oder Spalte) in Excel vorstellen, der sich direkt verarbeiten lässt. Im Prinzip lässt sich so z. B. der komplette Quellcode einer Webseite in einen Vektor einlesen und über den Namen des Vektors ansprechen.
„R ist kostenlos, stabil und performant.“
Wie Sie später noch sehen werden, ist es recht einfach, alle Befehle, die man in die Console eingegeben hat, später wieder aufzurufen und ggf. bei Bedarf in Summe in einen individuellen Programmcode zu überführen. Das erleichtert das Verständnis, die Erstellung eines kleinen Programms und auch die Fehlersuche. Hier greift das gleiche Grundprinzip wie beim Arbeiten mit Excel, wenn man kein ausgebildeter bzw. fachkundiger Programmierer ist. Man bearbeitet Daten Schritt für Schritt und sieht jeweils sofort das Ergebnis und ob alles wie gewünscht passt. Nach Eingabe einer fehlerhaften Formel erscheint sofort eine Fehlermeldung – nicht erst, wenn später ein Programm läuft. Erst wenn alles passt, speichert man sich die einzelnen Befehlszeilen ab und lässt später direkt alle auf einmal ablaufen.
R und RStudio enthalten eine umfassende Hilfe: Durch Eingabe eines Fragezeichens, gefolgt von einem Funktionsbefehl wird die Hilfe aufgerufen, die die Verwendung genau erklärt. Auch im Reiter „Help“ (Abbildung 2; Ziffer 8) ist ein kleines Suchfeld integriert, das die Suche erleichtert. Empfehlenswert für einen strukturierten Einstieg ist es allerdings, in ein entsprechendes Fachbuch zu investieren. Eine kleine Auswahl finden Sie am Ende dieses Beitrags.
„R ist sehr flexibel bei der Datenausgabe.“
R hat sehr flexible Ausgabeformate. So können Ergebnisse, Tabellen, Grafiken und anderes über Erweiterungspakete z. B. als CSV, TXT, XLS, Word, PowerPoint oder auch direkt in HTML ausgegeben werden (Abbildung 1). Ebenso ist es natürlich möglich, die Daten in angebundene Datenbanken zu schreiben. Damit entfällt der sonst übliche Anwendungsbruch, weil man z. B. in Excel arbeitet, Diagramme erzeugt und diese dann für eine Präsentation in PowerPoint kopiert. Wer seine Berichte modern lieber gleich per HTML ins Intranet oder ins Web schießen möchte, kann das ebenfalls tun. Analyse, Aufbereitung und Dokumentation können also ein einem einzigen Tool erledigt und alle nötigen Schritte dazu reversibel zentral mit abgespeichert werden.
Abbildung 1: Auszug für gängige Ausgabe- bzw. Exportformate in R
„Nichts geht mehr verloren – kein einziger Arbeitsschritt.“
Vielleicht ist einer der größten Vorteile von R, dass Sie alles zusammen in einer Umgebung halten. Wie laufen üblicherweise Analysen im weitesten Sinne in Unternehmen ab? Man hat ein Set von Daten in verschiedenen Formaten und nicht selten strukturell unterschiedlich. Man kopiert bzw. liest diese dann oft in Excel ein, wandelt bestimmte Daten um, verdichtet, sortiert, filtert und modifiziert sie, führt weitere Konsolidierungen und Berechnungen durch und erzeugt diverse Diagramme oder Übersichtstabellen. Werden diese in einen Bericht gegossen oder präsentiert, kopiert man sie in Word oder PowerPoint. So weit, so gut. Im nächsten Monat/Quartal/Jahr oder beim nächsten Projekt steht dann eine Wiederholung des Ganzen an. Dabei entsteht oft das Problem, dass man nicht nur all diese Arbeiten erneut durchführen muss. Noch öfter steht man vor den fertig modifizieren Tabellen und weiß nicht mehr, wie man von den Ursprungsdaten dort hingelangt ist, da nicht mehr alle Formeln vorhanden sind bzw. neu erdacht und ausprobiert werden müssen. Alles in allem eine gigantische und auch ärgerliche Verschwendung von Zeit und Ressourcen.
Wenn Sie sich darauf einlassen, R etwas näherzukommen, gehört dies künftig der Vergangenheit an. Denn in R speichern Sie bei Bedarf jeden einzelnen Schritt – das Öffnen der Datei(en), jede Bearbeitung und schließlich auch die Erzeugung von Ergebnissen, Kennzahlen, Diagrammen und visuellen Auswertungen. Alles wird in einer Umgebung abgelegt und kann jederzeit nachvollzogen und reproduziert werden. Wenn Sie tiefer in R eintauchen, werden Sie sogar in der Lage sein, jedwede Auswertung automatisch per HTML oder PowerPoint neu zu erzeugen. Im einfachsten Fall kopieren Sie eine immer gleich benannte Datei mit den aktuellen Monatszahlen in das Arbeitsverzeichnis von R und starten Ihre aufgezeichnete Programmierung. Das war es dann auch schon. Ein kompletter und durchaus auch optisch anspruchsvoller Bericht steht Sekunden später vollautomatisch im Intranet.
Wo finde ich R und RStudio?
Die Installation von R ist recht einfach. Es lässt sich kostenlos auf der Website von
cran.r-project.org
herunterladen, und zwar als Windows-, Mac-OS- und Linuxversion. R selbst ist wie erwähnt nicht so komfortabel zu bedienen und daher empfiehlt es sich für die meisten Nutzer, gleich noch RStudio dazu zu installieren. RStudio muss nach R installiert werden, sucht dann aber automatisch nach der R-Installation und integriert das Tool in eine übersichtlichere Benutzeroberfläche mit vielen nützlichen zusätzlichen Funktionen. Die Basisversion ist ebenfalls frei und unter rstudio.com erhältlich:
einfach.st/rstudio.
Wer den entsprechenden Rechner hat, sollte sich gleich die 64-Bit-Version installieren bzw. verwenden, da gerade rechenintensive Analysen deutlich schneller sind und auch die üblichen Restriktionen beim Datenvolumen unter 32 Bit entfallen.
Für normale Anwendungen ist RStudio kostenlos. Es gibt allerdings auch kommerzielle Lizenzen mit Support und weiteren Features sowie eine Serverversion.
Beim ersten Start prüft RStudio bzw. R noch, ob auf den Rechner eine aktuelle Java-Version installiert ist, was aus Sicherheitsgründen sowieso auf jedem Rechner Pflicht sein sollte. Anschließend präsentiert sich R integriert in RStudio aufnahmebereit für die ersten Befehle bzw. Gehversuche.
Abbildung 2: Der Startbildschirm von RStudio
Legen Sie jetzt einfach los
Nach der erfolgreichen Installation kann man sofort mit R bzw. RStudio arbeiten (Abbildung 2). Im linken Teil befindet sich die Console (Ziffer 1), in der die Befehle eingetippt werden. Geben Sie nach dem Promt (der blinkende Cursor nach dem „>“ Zeichen) einfach
2+5
ein und drücken Sie Return (Ziffer 2). Als Antwort erhalten Sie das Ergebnis dieser einfachen Rechenoperation. Gibt man einen Befehl falsch ein, z. B. „Print“ mit einem Großbuchstaben, erscheint eine Fehlermeldung, die hier zur Demonstration erzwungen wurde. Normalerweise erscheint nämlich bereits beim Tippen ein Vorschlagfenster mit den gültigen Befehlen für Funktionen (Ziffer 4). Das bedeutet, man kann sich den Rest einer Anweisung wie z. B. „print.data.frame“ sparen und den gewünschten Befehl einfach übernehmen.
Tipp
Wenn der Cursor im Consolenfenster blinkt, können Sie mit den Cursortasten hoch und runter die letzten eingetippten Befehle holen bzw. in diesen blättern. Das hilft insbesondere bei Tippfehlern, damit nicht alles erneut eingegeben werden muss. Einfach mit der Cursortaste-oben den letzten (falschen) Befehl holen, an der entsprechenden Stelle ausbessern und mit Return erneut auslösen. Zudem zeichnet R jeden Befehl in einer Historie auf, sodass er jederzeit auch später einfach noch mal verwendet werden kann.
Variablen weist man mit „<-“ ganz einfach einen Wert zu. Das machen wir hier nur einmal beispielhaft, um die Vorzüge des RStudios zu zeigen. Ziffer 5 zeigt eine solche Zuweisung:
wsb <- 100
weist der Variable „wsb“ damit den Wert 100 zu. Also erst der gewünschte Name, dann die Zuweisungszeichen und anschließend der Wert. Im rechten oberen Teil von RStudio findet man dann unter dem Reiter „Environment“ (Ziffer 6 und das angezeigte Fenster mit Ziffer 6) genau diese und natürlich alle anderen Variablen wieder, die man im Lauf einer Sitzung definiert hat. Das dient der Kontrolle, welchen Wert eine Variable gerade hat. Wenn Sie jetzt als Befehlszeile
wsb + 5
gefolgt von Return eingeben, sehen Sie unter Environment rechts oben den neuen Wert 105 für diese Variable. Prinzipiell kann man ganzen Datenpools (Vektoren, Matrizen, Data Frames) Variablennamen zuweisen, was das Handling und die Lesbarkeit durch einfache Namensvergabe enorm vereinfacht. Dies aber nur als Hinweis.
Unter dem Reiter „History“ (Ziffer 3) werden alle Befehle aufgezeichnet, die man in die Console eingegeben hat. Mit einem Mausklick lassen sie sich einfach wiederholen bzw. in die Console übernehmen. Später lassen sich diese Befehle dann ganz einfach in einem kleinen Programmcode überführen, der nacheinander abläuft.
Das charmante Prinzip ist also für den Einsteiger, dass er zunächst Schritt für Schritt nach jeder Eingabe explorativ prüfen kann, ob alles so richtig ist, und erst danach fasst man quasi die einzelnen Befehle zu einem ablauffähigen Programm zusammen und kann dieses dann mit einem einzigen Befehl starten.
Einfach mal machen!
Alle hier gezeigten Beispiele sind so gehalten, dass Sie möglichst einfach selbst erste Schritte zum Ausprobieren unternehmen können. Wir haben daher oft auf branchenübliche Zahlenbeispiele verzichtet, weil R einige Datenquellen zum Experimentieren bereits mitliefert. Sie müssen sich also nicht erst mit dem Erstellen und Einlesen von Datensätzen herumschlagen, nur um überhaupt eine Grundlage zum Testen zu haben. Ob Sie nun die Kelchlänge von Lilienarten oder den Benzinverbrauch von Autos visualisieren oder Marketingausgaben oder Backlinks, ist von der Methode her ja austauschbar. Hier liegt der Fokus tatsächlich darin, Sie sofort in die Lage zu versetzen, einfach einmal mit dem Tool herumzuspielen.
Ein Anwendungsbeispiel: Sie nutzen regelmäßig einen oder mehrere Datensätze, z. B. aus einem SEO-Tool, mit denen Sie arbeiten müssen. Diese enthalten aber unerwünschte (Sonder-)Zeichen, wie Umlaute als ß“ statt einem „ß“ oder schlicht den typischen Punkt statt des deutschen Kommas als Kommastelle. Das kann man natürlich auch in Excel erledigen, aber man muss alle Schritte einzeln und jedes Mal durchführen. Über R lädt man sich so einen Datensatz, verändert ihn mit den entsprechenden Anweisungen einmalig und prüft, ob alles korrekt ist. Anschließend speichert man sich die Befehle einfach ab und kann sie später direkt aufrufen. Der Datensatz muss dann nur noch geladen werden, das entsprechend passende erstellte Programm wird gestartet und der Datensatz entweder manuell oder sogar schon vom eigenen Programm abgespeichert – fertig. Prinzipiell lassen sich damit alle Daten auf einfache Weise verändern, bereinigen, auf Konsistenz prüfen oder einfach nur einzelne Zeichen tauschen.
Im rechten unteren Bereich von RStudio (Ziffer 8) hat man Zugriff auf Datenfiles, Grafiken (Plots), Packages (Erweiterungen) sowie auf eine Hilfe und einen Viewer.
Abbildung 3: In RStudio findet man unter dem Menüpunkt „Help“ nützliche CheatsheetsAbbildung 4: In R selbst (nicht in RStudio) sind umfangreiche PDF-Handbücher hinterlegt (englisch)
Mitgelieferte Testdateien
Praktischerweise beinhaltet die Installation von R bereits einige Dateien mit Daten, sodass man die ersten Gehversuche unternehmen kann, ohne erst einmal selbst Daten einlesen zu müssen. Eine dieser Beispieldatensätze ist „state.x77“. Er lässt sich mit dem Befehl
View(state.x77)
anzeigen. Links oben im Fenster werden jetzt alle 50 US-Staaten mit einigen Spalten wie „Einwohnerzahl“, „Durchschnittseinkommen“ etc. angezeigt (Abbildung 5).
Abbildung 5: R liefert einige Beispieldaten automatisch mit
Ein einfacher Befehl zeigt Ihnen direkt statistisch relevante Daten dieses Datensatzes an (Abbildung 6):
summary(state.x77)
R zeigt für jede Spalte gesondert die statistisch wichtigsten Strukturinformationen an. Für eine spätere Datenanalyse oder die Bildung von Kennzahlen ist dies sehr nützlich, weil man sofort u. a. die Streuung ablesen kann. Ein extremes Beispiel zur Verdeutlichung: Hatten 200 Verkäufe den Wert 1 € und weitere 200 den Wert 100 €, dann macht die Verwendung eines Mittelwerts (50 €) nicht wirklich Sinn.
Abbildung 6: Statistisch relevante Strukturdaten der Datei „state.x77″
Der Befehl
state.x77[11,2]
greift z. B. direkt im Datensatz „state.x77“ auf die elfte Zeile und die zweite Spalte zu und liefert 4963 als das Durchschnittseinkommen in Hawaii zurück (in Abbildung 5 zu sehen). Genauso können über Spalten oder Zeilen natürlich entsprechende weitere einfache Berechnungen oder Analysen durchgeführt werden.
Die ebenfalls in R mitgelieferte Datei „state.name“ beinhaltet nur die Namen der 50 US-Staaten. Welche dieser Namen besteht aus mehreren Wörtern wie z. B. New Jersey? Hier hilft die Funktion „grep“, mit der man in diesen Daten ganz einfach nach einem Leerzeichen sucht. Beachten Sie bitte, dass sich der Name der verwendeten Datendatei jetzt ändert bzw. eine andere Datei (state.name) zugrunde liegt (Testen Sie doch mal View(state.name) um zu sehen, was der Datensatz beinhaltet.)
state.name[grep(“ „, state.name)]
Als Ergebnis erhält man in der Ausgabe die zehn Staaten mit einem „Doppelnamen“. Tauschen Sie das Leerzeichen z. B. gegen den Wortbestandteil „New“ aus, erhalten Sie die vier Bundesstaaten, die eben diese Zeichenfolge enthalten, der Befehl lautet dann:
state.name[grep(„New“, state.name)]
Diese einfachen Beispiele sollen nur verdeutlichen, wie leicht die Extraktion und Filterung in Datenbeständen ist und welches Prinzip dahintersteckt. Natürlich kann man solche Aufgaben bei so kleinen Datensätzen auch gut und einfach z. B. in Excel erledigen. Werden die Daten jedoch umfangreicher, macht das schon deutlich mehr Arbeit, die zudem prinzipiell jedes Mal neu durchgeführt werden muss. Die Befehle bzw. Befehlssequenzen hier in R können jedoch abgespeichert und zu jedem späteren Zeitpunkt einzeln oder in Summe aufeinanderfolgend gestartet werden.
Tipp: Geben Sie den Befehl
datasets::
ein und Sie erhalten in einem Pop-up-Fenster die in R integrierten Versuchsdatensätze angezeigt, die Sie per Mausklick einfach übernehmen können (Abbildung 7). Geben Sie den Befehl
data()
ein, erscheinen im linken oberen Fenster alle Namen und eine jeweils kurze Beschreibung aller Datensets, die bereits installiert sind.
Abbildung 7: Automatisch mitgelieferte Datensätze zum Ausprobieren mit Inhaltsbeschreibung
Noch ein weiteres kleines Beispiel zeigt Abbildung 8. Für die Variable „Zeichenkette“ wird zunächst hilfsweise ein Text „Die Website Boosting …“ eingelesen. Der Befehl „strsplit“ zerlegt dann den Text in einzelne Wörter bzw. trennt nach einem Leerzeichen. Stellen Sie sich vor, Sie hätten eine Exceltabelle mit mehreren Tausend Zellen, die jeweils den Text einer Webseite enthalten, und für semantische Analysen müsste jedes Wort extrahiert werden. In R liest man dazu vereinfacht erklärt über ein Erweiterungspaket ein Set von URLs mit einer einzigen Funktion in Vektoren ein und ein weiterer Befehl extrahiert aus jedem Vektor jedes einzelne Wort. Bereits mit einigen Grundkenntnissen in R lässt sich so durchaus enorm Zeit sparen.
Unter einfach.st/rdatasets finden Sie übrigens eine recht gut kommentierte Übersicht (englisch) mit Beispielen und Beispielcode für die mitgelieferten Data Sets.
Abbildung 8: Mit einem einzigen Befehl Texte in Wörter zerlegen
Erweiterungspakete installieren
Wie erwähnt werden für R sehr viele Erweiterungspakete im Web angeboten, die sich recht einfach integrieren lassen. Diese muss man nur einmal zu R hinzuladen und kann sie später dann nach dem jeweiligen Programmstart bei Bedarf aktiveren und die dort hinterlegten Funktionen nutzen. Eine erste gute Quelle finden Sie auf cran.r-project.org. Die dort ladbaren Pakete kann man direkt über R laden. Dafür muss bzw. sollte man natürlich den Namen der Erweiterung kennen. Diese werden meist in Anleitungen, Beispielen oder in der Literatur erwähnt. Die Installation kann dann per Befehlszeile über die Funktion „install.packages“ erfolgen (hier die Erweiterung „htmltidy“ zum Umgang mit HTML-Dokumenten):
install.packages(„htmltidy“)
oder über das Menü oben in RStudio unter Tools/Install Packages, wie in Abbildung 9 zu sehen ist. Auch hier erscheint beim Tippen bereits ein kleines Pop-up mit einer entsprechenden Auswahl. Lässt man den Haken „Install depencies“ (in der Abb. verdeckt unter dem Pop-up) drin, werden sog. abhängige Packages gleich mit installiert. Die Erweiterung „htmltidy“ greift z. B. unter anderem auf die Erweiterung „xml“ und „htmlwidgets“ zu und löst damit auch gleich deren automatische Integration aus. In der Console erscheint dann eine entsprechende Meldung.
Tipp
Manchmal zickt R bei der Eingabe von Erweiterungspaketen über die Kommandozeile mit einer Fehlermeldung zurück, weil die Groß-/Kleinschreibung nicht passt. Daher empfiehlt es sich tatsächlich, das (einmalige) Laden von Packages – aus Sicht eines Programmierers sicher unehrenhaft, aber eben einfacher – über das Menü von RStudio wie in Abbildung 9 gezeigt zu erledigen.
Die meisten Packages sind recht gut dokumentiert. So findet man für das eben erwähnte Package weitere Infos unter cran.r-project.org/web/packages/htmltidy/index.html und dort unter „Downloads“ auch ein PDF mit einer genauen Funktionsbeschreibung.
Möchte man die Funktionen eines einmal installierten Packages in R verwenden, aktiviert man es ganz einfach mit der Anweisung:
library(packagename) – im Beispiel also: library(htmltidy)
Abbildung 9: Erweiterungen lassen sich sehr einfach installieren
Einen Überblick über installierte Erweiterungen findet man in RStudio im rechten unteren Fenster unter dem Reiter „Packages“ (siehe Abbildung 2, Ziffer 8).
Eine CSV-Datei einlesen, modifizieren und wieder ausgeben
Zum Einlesen von Dateien ist es nützlich, gleich zwei Erweiterungen zu installieren: „readr“ und „readxl“ (für das Excelformat). Dazu geben Sie einfach die beiden Befehlszeilen ein
install.packages(„readr“)
install.packages(„readxl“)
und aktivieren anschließend zumindest die Erweiterung „readr“:
library(readr)
Erstellen Sie zum Ausprobieren eine einfache CSV-Datei z. B. über Excel oder einen Texteditor mit mehreren Zeilen und Spalten. In die erste Zeile schreiben Sie durch Kommata getrennt die Spaltenüberschriften und darunter ebenfalls durch Kommata getrennt die Datensätze, wie z. B.
Der Punkt bei den Inlinks-Zahlenwerten ist absichtlich gewählt, er soll durch ein Komma getauscht werden, um das Prinzip der Datenmodifikation zu zeigen. Erzeugen Sie in RStudio über „File“ – „New Projekt“ ein neues Projekt und speichern Sie dieses auf dem Rechner unter einem beliebigen Ort ab. Der angegebene Projektname ist dann automatisch der Verzeichnisname und Ihr „Working Directory“. In dieses Verzeichnis speichern Sie dann die CSV-Datei ab, damit Sie diese durch einen einfachen Befehl öffnen und später speichern können. Alternativ kann man mit R natürlich auch auf alle anderen Verzeichnisse/Dateiorte zugreifen, aber die Dateien zu Anfang in einem eigenen Working Directory zu speichern, erleichtert die Arbeit etwas. In dem Beispiel hier wurde als Working Directory „WSB Einführungsartikel“ gesetzt und rechts unten unter „Files“ taucht die Datei beispiel.csv nach der Erzeugung bzw. dem Abspeichern dann auch entsprechend auf (Abbildung 10).
Der Befehl
getwd()
gibt übrigens das aktuelle Verzeichnis aus.
Abbildung 10: Legen Sie über ein neues Projekt einen Speicherort zum Testen an
Über den Befehl
beispiel <- read.csv(„beispiel.csv“)
weisen Sie jetzt ganz einfach der Variable „beispiel“ (oder auch einem beliebigen anderen Namen) über die Funktion „read.csv“ die Datei beispiel.csv zu. Da die Datei im Working Directory liegt, brauchen Sie keine gesonderten Pfadangaben. Den Inhalt dieser Datei kann man anschließend einfach über den Variablennamen ansprechen. Tippen Sie z. B.
print(beispiel)
ein, wird der Inhalt der eingelesenen Datei ausgegeben (Abbildung 11). Probieren Sie auch den Befehl view(beispiel) und statt der Ausgabe in der Console geht links oben ein Datenfenster auf, das die Daten sauber in Tabellenform anzeigt.
Abbildung 11: Dateien einlesen und anzeigen lassen
Geht es nicht nur um Datenanalysen, sondern werden Daten auch modifiziert oder neue Daten erzeugt, die man speichern möchte, geht auch das recht einfach mit dem Befehl write.table:
write.table(datensatz, „dateispeichername.csv“)
Möchten Sie z. B. die Daten des integrierten Beispiels „state.x77“ in eine CSV-Datei namens „test.csv“ in das aktive Arbeits-/Projektverzeichnis speichern, lautet der Befehl also:
write.table(state.x77, „test.csv“)
Abbildungen erzeugen
Natürlich lassen sich Grafiken in Excel recht einfach erzeugen. R hält jedoch deutlich mehr Möglichkeiten und nach Meinung vieler auch bessere Grafiken vor. Wer z. B. schon einmal versucht hat, aus einem Datensatz ein vernünftiges Histogramm zu erzeugen, wird sich über die fehlende Möglichkeit geärgert haben, die automatische Clusterung von Excel zu umgehen. Hat man stark abweichende Werte, sind Histogramme dort praktisch wegen der Spreizung nicht zu verwenden. In R stellt das Definieren von Clustern für die Histogrammsäulen kein Problem dar. Ebenso wenig wie die (befehlsorientierte) Formatierung einer Abbildung. Einmal definiert, lässt sie sich für Folgeabbildungen mit einer Zeile Code in immer demselben eigenen Design erzeugen.
Abbildung 12: Anriss des mitgelieferten Datensatzes „mtcars“
Ein Histogramm erzeugt man in R mit dem einfachen Befehl „hist“ gefolgt von dem gewünschten Datensatznamen in Klammer dahinter. Eine der mitgelieferten Datenbeispiele ist die Datei mtcars. Mit dem nun schon bekannten Befehl
print(mtcars)
können Sie einen schnellen Blick darauf werfen. Möchte man nun den Benzinverbrauch aller dort gelisteten Modelle (erste Spalte, mpg, also miles per gallon) in einem Histogramm darstellen, benötigt man nur eine Befehlszeile:
hist(mtcars$mpg, col = „blue“)
Das Prinzip ist recht leicht ersichtlich. Aus den Daten „mtcars“ soll aus der Datenspalte „mpg“ ein Histogramm erzeugt werden (Befehl „hist()“), dessen Balken blau sind („blue“). Das Ergebnis zeigt Abbildung 13 auf der rechten Seite – und im Vergleich links das Histogramm, das Excel mit den gleichen Daten erzeugt. R teilt die Datencluster statistisch vernünftiger auf und erstellt ein durchaus differenziertes Bild. Wenn Sie die Clusterbildung selbst beeinflussen möchten, weil Sie z. B. feinere Abstufungen brauchen oder einfach nur auch zeigen wollen, dass unter zehn Gallonen pro Meile eben kein Wert und damit keine Säule vorhanden ist, geht das über eine einfache Erweiterung des Befehls mit Angabe der gewünschten Intervalle „breaks“ (der Übersichtlichkeit halber wurde auf die Farbangabe hier verzichtet). Probieren Sie es einfach aus:
hist(mtcars$mpg, breaks = c(5,10,15,20,25,30,35))
Selbstverständlich könnte man die Intervalle auch mit einer eigenen Formel statt mit manuell eingegebenen Intervallen wie hier im Beispiel berechnen lassen.
Abbildung 13: Vergleich eines unbearbeiteten Histogramms mit identischen Daten in Excel und R
Aber auch ein schneller optischer Blick auf strukturelle Eigenheiten von Datenreihen ist möglich. Dazu lässt man sich eine oder mehrere Datenreihen als Boxplot ausgeben. Zur Demonstration kann man ganz einfach erneut auf das bereits genutzte Datenset „mtcars“ zugreifen. Möchte man mehr über den Einfluss der Anzahl der Zylinder eines Motors auf den Verbrauch bzw. auf die Streuung der Daten wissen, setzt man beides einfach in Beziehung. Der Befehl dazu ist
boxplot(mpg ~ cyl, data=mtcars)
In Abbildung 12 ist ersichtlich, dass es zwei Spalten im Datenset gibt, die mit „mpg“ (Miles per Gallon) und „cyl“ (Zylinder) überschrieben sind. Der Befehl „boxplot“ bezieht sich auf die angegeben Datenquelle, setzt die beiden Datenreihen dann ganz einfach in Beziehung und gibt Abbildung 14 aus.
Dort erkennt man auf den ersten Blick, wie stark die Verbrauchsdaten des nach Zylinder geclusterten Verbrauchs streuen. Würde man statt mtcars auf einen eigenen eingelesenen Datensatz verweisen und zwei Spaltenüberschriften auswählen, müsste man den boxplot-Befehl einfach nur entsprechend anpassen und mehr nicht. Dazu wären in R nur zwei Befehlszeilen nötig – der zum Einlesen und der Befehl zur entsprechenden Ausgabe. Eine Sache von wenigen Sekunden.
„Vor der Verwendung von Daten ist es immer hilfreich, einen statistisch motivierten Blick auf die Struktur dieser Daten zu werfen.“
Wer es eine Spur härter, aber keinesfalls komplexer haben möchte, kann auch problemlos mehrere Datenreihen miteinander korrelieren lassen bzw. optisch über Streudiagramme prüfen, ob es einzelne Abhängigkeiten bzw. Korrelationen gibt. Dies lässt sich gut bzw. schnell und einfach am Beispiel des Datensets „iris“ zeigen. Dort sind für drei Schwertlilienarten in Summe 150 Datensätze mit jeweils Länge und Breite der Kelchblätter (Sepal) und der Kronenblätter (Petal) hinterlegt. Mit
View(iris)
wird das Datenset angezeigt (Abbildung 15).
Geben Sie jetzt doch einfach den Befehl
plot(iris[-5])
ein. Sie erhalten zwölf Streudiagramme aller möglichen Kombinationen zwischen Kelchblättern und Kronenblättern nach Länge und Breite (Abbildung 16). In den beiden rot markierten Diagrammen lässt sich unmittelbar ein fast linearer Zusammenhang bezüglich Länge und Breite bei den Kelchblättern erkennen, während bei den Kronenblättern und zwischen Kronen- und Kelchblättern kein solcher offensichtlich ist.
Tauschen Sie jetzt einfach geistig oder auch real in der Praxis die letzten Beispiele wie z. B. das florale Datenset mit echten Daten aus Ihrem Arbeitsumfeld aus – dann erkennen Sie zumindest in Ansätzen den Wert und die Transparenz, die R in wenigen Minuten bringen kann. Und das ganz ohne wirklich tiefergehende Programmierkenntnisse und nur mit dem Wissen über einige einzelne Befehlszeilen. Natürlich bleibt der Nutzen tatsächlich überschaubar, wenn Sie bei der Lektüre nur dieses Beitrags stehen bleiben. Aber stellen Sie sich doch mal vor, Sie steigen jetzt motiviert und in Erahnung der Kenntnis des Potenzials von R Stück für Stück tiefer ein. Sie haben noch nicht einmal ein halbes Prozent von dem ausprobiert, was R leisten kann, wenn Sie es richtig bespielen. Was nun am Ende mehr nützt – die Rationalisierungseffekte für einfacheres und schnelleres Arbeiten oder neue Erkenntnisse und bessere, wirklich datengestützte Entscheidungen –, bleibt Ihren Überlegungen und Ihrer Motivation überlassen.
Vitamin D: Datenanbindung über R an Google Schnittstellen
Vitamin D:Datenanbindung über R an Google Schnittstellen – websiteboosting.com
R ist nicht nur Open Source (damit kostenlos) und anpassungsfähig durch vielfältige Pakete, sondern auch offen für andere (technische) Verbindungen. Diese Verbindungen, vulgo API, ermöglichen, flexibel Daten an der Ursprungsquelle abzufragen, entsprechend weiterzuverarbeiten und ggf. modifiziert…
R ist nicht nur Open Source (damit kostenlos) und anpassungsfähig durch vielfältige Pakete, sondern auch offen für andere (technische) Verbindungen. Diese Verbindungen, vulgo API, ermöglichen, flexibel Daten an der Ursprungsquelle abzufragen, entsprechend weiterzuverarbeiten und ggf. modifiziert wieder zurückzuliefern. Google bietet eine Vielzahl von API, die in R eingebunden eine enorme Individualisierung und Automatisierung von analytischen Prozessen und Visualisierungen ermöglichen. Die Excel-Alternative Google Sheets in Kombination mit Google Data Studio ist bereits eine unkomplizierte Lösung für vielfältige Visualisierungen. Gepaart mit der statistischen Leistung von R eröffnet sich durch die weitere Kombination mit API nochmals ein deutlicher Zugewinn an Flexibilität! Tobias Aubele zeigt, wie Sie diese Schnittstellen nutzen können.
R wird kontinuierlich von einer großen Community weltweit weiterentwickelt, Gleiches gilt für die Dienste von Google wie Maps & Co. Unglaubliche Mengen an Daten liegen in diversen Datensilos und „sehnen“ sich danach, verarbeitet bzw. interpretiert zu werden und einen Nutzen zu stiften. Durch die Vielzahl an Silos und steigenden Datenmengen bedarf es einer effektiven und effizienten Verarbeitung, damit letztlich genügend Zeit für die Interpretation der Daten und das Ableiten von Maßnahmen übrig bleibt. Obwohl ggf. sehr zeitaufwendig, wird in Fachbereichen gerne Microsoft Excel eingesetzt, da dort Daten mittels Formeln und Funktion aus diversen Quellen flexibel zusammengeführt und verarbeitet werden können. Leider sind Daten teilweise veraltet, ehe sie letztlich über manuelle Zusammenfassungen und Verdichtungen für den eigentlichen Nutzungszweck zur Verfügung stehen. Sofern direkt API (Programmierschnittstellen) genutzt werden, können aktuelle Daten unmittelbar am Ursprung abgeholt und zurückgeliefert werden und bieten langfristig ggf. ein hohes Potenzial für automatisierte Abläufe.
Programmcode online verfügbar!
Damit Sie Codezeilen nicht einzeln abtippen müssen, sind zwei der Skripte aus diesem Beitrag direkt online für Sie zum Download hinterlegt: Das Skript zum Knowlede Graph unter www.websiteboosting.com/code/r-knowledge Das Skript für Google Sheets unter www.websiteboosting.com/code/r-sheets
Die API – aktuelle Daten direkt vom Ursprung
Über die Google API können diverse Google-Dienste direkt über R angesprochen werden. Nach einer Registrierung unter console.cloud.google.com kann die gewünschten API, wie bspw. die des Google Knowledge Graph, einzeln aktiviert und unmittelbar getestet bzw. genutzt werden (siehe Abb. 1).
Abb. 1: Aktivierung einer Google API
Weiterhin können anschließend die notwendigen Anmeldedaten wie ein API-Schlüssel oder eine OAuth-Client-ID erstellt werden (siehe Abb. 2). Damit wird sichergestellt, dass der Datenzugriff nur von autorisierten Nutzern ermöglicht wird.
Abb. 2: Erstellung von gesicherten Anmeldemechanismen
Mittels der API werden die Daten direkt aus der Datenbank von Google abgerufen. Es stehen damit nicht nur aktuelle, sondern auch ggf. erweiterte Daten zur Verfügung. Das heißt, Informationen über Albert Einstein, welche im Graphen am rechten Bildschirmrand angezeigt werden (siehe Abb. 3), stehen direkt zur weiteren Verarbeitung zur Verfügung. Die API ermöglicht die Extraktion weiterer Daten, sollten mit dem Suchbegriff mehrere Entitäten (Personen, Objekte) in Verbindung gebracht werden wie bspw. die Person Hans Albert Einstein.
Abb. 3: Google Knowledge Graph von Albert Einstein
Das zur Datenextraktion notwendige R-Paket lautet GoogleKnowledgeGraphR, entwickelt von Daniel Schmeh (zur Dokumentation siehe das PDF unter: einfach.st/r4kgraph). Mittels des individuellen API-Keys (Generierung siehe Abb. 2) werden mit dem Befehl
gkg_raw
die gewünschten Informationen in diversen Sprachen abgerufen. Das heißt, es stehen neben der Beschreibung unmittelbar die URL des Bildes, die URL des Eintrages sowie Informationen zu den Nutzungsrechten (dennoch prüfen!) zur Verfügung (siehe Abb. 4). Ohne die jeweilige Suchabfrage bei Google starten zu müssen, können die Ergebnisse direkt in R abgerufen und weiterverarbeitet werden. Dies kann zu einer weiteren Vereinfachung und damit zur Zeitersparnis führen.
Abb. 4: Aufruf der Knowledge Graph API über R
Ähnlich diesem Prozess erfolgt die generelle Nutzung von Google API (mit R). Es bedarf eines API-Schlüssels bzw. einer Autorisierung sowie eines korrespondierenden Programms (hier R-Paket). In der Praxis können nahezu alle Google API, wie bspw. die Google Translator API oder die Google Maps/Places API, abgefragt werden. Vereinzelt sind die Services kostenpflichtig mit einem flexiblen Abrechnungsmodell wie bspw. auf Basis der Anzahl an API-Abfragen. Damit könnten Textübersetzungen bzw. Abfragen zu Distanzen, Öffnungszeiten, Adressen etc. von Restaurants und anderen Google-Places-Einträgen vollzogen werden. Die entsprechenden R Packages heißen googleway und googleLanguageR.
Kollaboration mit Google Sheets
Das Besondere an Google Sheets ist der weltweite Zugriff, die große Rechenleistung sowie die gleichzeitige Zusammenarbeit mit mehreren Personen. Weiterhin können Daten aus diversen Quellen zusammengeführt (vergleichbare Excel-Funktionen SVERWEIS bzw. INDEX/VERGLEICH) und letztlich ein Bericht sehr flexibel gestaltet, individualisiert und geteilt werden. Daher erscheint es sinnvoll, die Möglichkeiten von Google Sheets sowie ggf. der nachgelagerten Visualisierung mit Google Data Studio zu nutzen.
Daten in R können an Google Sheets bzw. von Google Sheets übermittelt werden. Hierzu sind die Pakete googlesheets (PDF zur Dokumentation siehe: einfach.st/r4sheets) bzw. googleAuthR notwendig bzw. hilfreich. Nach der Installation des Paketes über den Befehl
install.packages(“googlesheets“)(siehe Abb. 6)
erfolgt die Freigabe bzw. Authentifizierung des R-Pakets mit Google Drive über
gs_auth() (siehe Abb. 5).
Abb. 5. Autorisierung des R-Pakets
Nach erfolgreicher Authentifizierung kann mit dem Befehl
gd_user()
der aktuelle Nutzer sowie der Berechtigungsstatus abgefragt werden. Der Befehl
gs_new
ermöglicht, ein neues Sheet anzulegen sowie den Namen bzw. Arbeitsblattnamen zu vergeben. Ab diesem Zeitpunkt können Daten eingegeben bzw. das Sheet genutzt werden. Der Befehl
gs_delete
löscht das Sheet entsprechend. Das jeweilige Sheet muss vor einer Aktion immer exakt adressiert werden, wozu diverse Möglichkeiten zur Verfügung stehen (siehe Dokumentation). Die exakte Art ist über die URL via
gs_url (siehe Abb. 6),
sofern Namen einzigartig sind, auch hilfsweise über den Titel (Befehl: gs_title). Soll das Sheet im Browser aufgerufen werden, muss der Befehl
gs_browse
mit dem Namen des Sheets (im Beispiel in der Variable gs gespeichert) und dem Blattnamen (relative Nummer bzw. absoluter Name) ausgeführt werden.
Abb. 6: Erstellung eines Google Sheets innerhalb von R
Google Sheets mit Daten füllen
Prinzipiell können auch Daten aus Google Analytics in R abgerufen und analysiert werden (siehe den ersten Teil dieses Beitrags in der letzten Ausgabe #53). Dem Google Sheet „Analytics“ kann über den Befehl
gs_ws_new
ein neues Arbeitsblatt mit dem Namen Oktober hinzugefügt werden (siehe Abb. 7) und anschließend mit den Google-Analytics-Daten befüllt werden (Abruf der Daten über den Befehl google_analytics aus dem R-Paket googleAnalyticsR). Die neuen Informationen sollen ab der Position (anchor) A1 zeilenweise (byrow = FALSE) eingefügt werden. Sollten dann im späteren Verlauf weitere Zeilen hinzugefügt werden (und dabei die alten Daten nicht überschrieben werden), kann ein Arbeitsblatt ausgelesen (Befehl gs_read), die aktuelle Anzahl an benutzten Zeilen festgestellt (nrow) und anschließend über die R-Funktion paste0 ein neuer Start ermittelt (im Beispiel Zelle A38) und an die Variable gs_position übermittelt werden. Ein weiterer Aufruf der Funktion gs_edit_cells fügt die Daten demnach nicht wieder an der Position A1 ein, sondern nutzt als initiale Startposition den Inhalt der Variable gs_position.
Abb. 7: Daten an Google Sheets aus R übertragen
Highlight: spezifische Google-Sheets-Funktionen
Mittels Austausches von Information an Google Sheets (lesen und schreiben) kann ein flexibler Datenaustausch mit R erfolgen. Ein weiterer Vorteil von Sheets ist die Mannigfaltigkeit spezieller Funktionen. Über die Funktion
kann eine XPath-Abfrage generiert werden, welche Elemente aus beliebigen Webseiten direkt ausliest (hier der H1-Text; siehe Abb. 8). Mittels einer weiteren Funktion
=GOOGLETRANSLATE(D2;"de";"en")
wird der Inhalt einer Zelle in die englische Sprache übersetzt. Die Funktion Verketten ermöglicht in diesem Zusammenhang, URL-Fragmente aus Google Analytics zu einer kompletten URL zusammenzuführen. Die Daten in Google Sheets können im weiteren Verlauf (manuell) beliebig verändert und anschließend wieder in R eingelesen/ weiterverarbeitet oder mit einer Visualisierung in Google Data Studio verbunden werden.
Abb. 8: Nutzung von Google-Sheets-spezifischen Funktionen
Google Data Studio hat diverse Verbindungen zu Datenquellen, was für die Analyse und Aufbereitung eine hohe Flexibilität bietet. Weiterhin können beliebige Google-Tabellen als Datenquelle initiiert und anschließend in die Berichte integriert werden – bspw. jeweils als eigene Seiten. Die Anbindung geschieht über zwei Schritte. Erstens muss über den Google Tabellen-Connector das jeweilige Tabellenblatt gewählt und somit als Datenquelle definiert werden (siehe Abb. 9). Zweitens müssten anschließend die damit geschaffenen Datenverbindungen mit einem spezifischen Bericht verbunden und die jeweiligen Datenfelder ausgewählt werden. Zur Visualisierung stehen diverse Möglichkeiten zur Verfügung (siehe Abb. 10).
Abb. 9: Auswahl von Google-Tabellen als Data-Studio-Connector
Innerhalb des Berichtes besteht die Möglichkeit, mit mehreren Seiten zu arbeiten und damit bspw. die Sheets-Integration als Detailbericht einer großen Analyse zu nutzen. Weiterhin können einzelne Informationen/Spalten aus Sheets ausgewählt und in diversen Visualisierungsmöglichkeiten auf dem Bericht verortet werden.
Abb. 10: Berichtsaufbau mit Sheets-Integration
Fazit
Zusammenfassend lässt sich sagen, dass R, Google Sheets, Google Data Studio etc. für sich hervorragende Möglichkeiten bieten. Die wahre Stärke zeigt sich, wie fast immer, in der Kombination verschiedener Faktoren/Quellen. Daten aus diversen Quellen (schnell) zusammenzufassen, aus unterschiedlichen Blickwinkeln zu betrachten und unkompliziert einem definierten Empfängerkreis zur Verfügung zu stellen, sind nur punktuelle Vorteile.
In diesem Sinne: Verbinden Sie Ihre Informationen, kombinieren Sie Daten – ggf. trügt ja der erste Anschein.
R4SEO: Automatisierte Reports mit R generieren (Teil 1)
R-Leuchtungen! Teil 9
R-Leuchtungen! Teil 9: Title-Geddon – war da was bei Ihnen? – websiteboosting.com
In den Ausgaben bis 54 bis 58 der Website Boosting konnten Sie in der Serie „R4SEO“ von Patrick Lürwer nachvollziehen, wie man die kostenlose Software R verwendet, was sie leistet und wie man sie nutzbringend für die eigene Arbeit für SEO bzw. die Aufklärung im Online-Marketing einsetzen kann. R…
In der letzten Ausgabe der Website Boosting gab Tobias Aubele einen sehr guten Einblick in die Potenziale von R, um auf einfache und reproduzierbare Weise Daten über die Google-Analytics-API abzufragen. Diese neue Artikelserie von Patrick Lürwer baut darauf auf und zeigt, wie mittels R Reports erstellt werden können, die sich zu einem bestimmten Zeitpunkt automatisch aktualisieren und per Mail verschicken. Im ersten Teil geht es nun zunächst um das Abfragen verschiedener APIs für die Datenbeschaffung. In den folgenden Teilen werden die Daten aggregiert, visualisiert und in einem Report zusammengefasst.
Tipp
Um Ihnen das Abtippen des Codes zu ersparen, können Sie sich das Skript zu diesem Artikel unter folgendem Link auf GitHub herunterladen. Dennoch empfehle ich Ihnen, den Code selbst zu schreiben, um ein Gefühl für die Syntax zu bekommen. einfach.st/r4seocode
Das Google Data Studio (GDS) bietet eine einfache Möglichkeit, Daten aus dem Google-Kosmos – bspw. aus Google Analytics (GA) und der Google Search Console (GSC) – abzufragen, zu visualisieren und als Reports aufzubereiten. Problematisch wird es allerdings, wenn andere Datenquellen angebunden werden sollen. Denkbar sind hier APIs anderer Anbieter wie Sistrix. In solchen Fällen muss der „Umweg“ über Google Spreadsheets und Google Apps Scripts gegangen werden, um die Abfragen selbst zu programmieren. Dies ist durchaus ein valides Vorgehen, das jedoch schnell an seine Grenzen stoßen kann. Denn meist sind Reports nur der erste Schritt. Sobald in diesen Auffälligkeiten erkennbar werden, schließt eine Analyse an, die eine umfassende Beschäftigung mit den zugrunde liegenden Daten erfordert. Derartige Analysen verlangen zumeist komplexe Datentransformationen und -aggregationen, für die Dashboard-Softwares, wie das GSA, mit ihren begrenzten Filtern- und Manipulationsoptionen naturgemäß nicht ausgelegt sind. Ganz abgesehen davon, dass der direkte Zugriff auf die Daten zur Weiterverarbeitung häufig gar nicht gegeben ist. Von großem Vorteil ist es daher, wenn Report- und Analysesoftware in einer Anwendung vereint sind. Diese Anforderungen kann R insofern erfüllen, als die Programmiersprache durch Packages so erweitert werden kann, dass mit ihr sowohl sehr individualisierte Reports erstellt als auch umfangreiche Analysen durchgeführt werden können.
Da Datenanalysen eine sehr komplexe Thematik sind, soll in diesem Artikel jedoch zunächst das Potenzial von R zur Report-Generierung vorgestellt werden. Denn im Grunde sind beide Aufgaben bis zu einem gewissen Grade sehr ähnlich. Zunächst werden Daten von verschiedenen Quellen abgefragt, dann aufbereitet und schließlich visualisiert. Bei Analysen ist dieser Prozess jedoch iterativ, ohne dass im Vorhinein klar ist, wie das Ergebnis resp. die Erkenntnis genau aussieht. Bei der Generierung von Reports hingegen ist der Ablauf des Datenprozesses vorgegeben. Sie sind daher kleine, standardisierte Analysen, die an einem bestimmten Punkt der Visualisierung aufhören. Das Ergebnisdokument ist somit immer gleich und jederzeit reproduzierbar. Daher eignen sie sich sehr gut, um exemplarisch die Möglichkeiten von R aufzuzeigen, und sind dabei aber gleichzeitig so vereinheitlicht, um durch den Leser selbst nachgebaut zu werden. Ich möchte Sie daher gerne dazu auffordern, das folgende Skript selbst in RStudio umzusetzen.
Hinweis
Der Autor ist sich bewusst, dass gerade für Einsteiger der Anfang etwas holprig sein kann. Aber auch bei erfahreneren Lesern können durchaus Fragen aufkommen. Um hier Hilfestellung zu bieten, die Antworten der Community zugänglich zu machen und den Austausch anzuregen, möchte er Sie ermutigen, in der extra hierfür gegründeten Facebook-Gruppe nachzufragen. Es gibt dabei keine „dummen“ Fragen. Vielmehr hätte der Autor sich in seiner Anfangszeit selbst ein solches Forum mit dem Fokus auf analytische Programmierung und Online-Marketing sehr gewünscht. www.facebook.com/groups/ompyr/
Aber genug der langen Vorrede! In diesem Teil der Serie ist das Ziel, die Sessions aus GA sowie die Performance-Daten aus der GSC abzufragen, um die Packages für diese APIs besser kennenzulernen. Darüber hinaus werden Sie am Beispiel von Sistrix eine eigene API-Abfrage schreiben, um den Sichtbarkeitsindex für eine Domain zu ermitteln. Als Beispiel-Domain dient hier die Website dein-trueffel.de, ein Studentenprojekt an der Hochschule Darmstadt im Modul „Fortgeschrittene Suchmaschinenoptimierung“, das durch Jens Fauldrath und Stefan Keil betreut wird. Voraussetzung zum Nachvollziehen des Skripts sind eine aktuelle R-Installation (www.r-project.org) und RStudio (www.rstudio.com).
Anlegen eines neuen Projekts in RStudio
Zunächst wird ein neues Projekt angelegt (File → New Project … → New Directory → New Project; Abb. 1). Benennung und Speicherort können Sie frei wählen. Der Einfachheit halber wird für diesen Beitrag das Projekt „report“ (Directory name) unter C:\Users\{USER}\Documents\ (im Eingabedialog durch ~ automatisch abgekürzt; Abb. 2) erzeugt.
Abbildung 1: Anlegen eines neuen ProjektsAbbildung 2: Speicherort und Benennung des Projekts
Das Projekt ist zunächst leer, im File-Explorer finden Sie nur eine RStudio-Projektdatei (report.Rproj), die ignoriert werden kann. Daher wird als erstes über File → New File → R Script (oder den darunter befindlichen Button) eine neue Datei erzeugt und unter der Benennung api_calls.R gespeichert.
Abbildung 3: (1) Neues Skript erstellen, (2) Projekt-Datei und Skript im File-Explorer, (3) Skript-Editor zeigt die erstellte Datei an
Installation und Laden der benötigten Packages
In der soeben erstellen api_calls.R-Datei werden nun die benötigten Packages installiert bzw. – falls bereits vorhanden – aktualisiert und geladen (Abb. 4; 1). Die Google-Packages kennen Sie bereits aus dem Beitrag von Tobias Aubele. Das Package lubridate erweitert den Funktionsumfang von R für die komfortable Arbeit mit Datums- und Zeitwerten, jsonlite dient zum Abfragen und Verarbeiten von JSON-Dateien. Sobald Funktionen aus diesen Packages verwendet werden, wird explizit darauf hingewiesen. Die vorangestellten Rauten kommentieren den Code aus. Beim ersten Ausführen müssen Sie diese also entfernen. Markieren Sie dann den gesamten Code mit der Maus und führen Sie ihn durch Drücken der STRG- und ENTER-Tasten aus.
Abbildung 4: Installieren bzw. Aktualisieren und Laden der benötigten Packages
In der anschließenden options()-Funktion definieren Sie Ihre Google-Client-ID sowie Ihr -Secret (2). Diese können Sie sich unter console.developers.google.com generieren. Das Argument scopes definiert die Berechtigungen für die GA- bzw. GSC-API. gar_auth() dient schließlich der Authentifizierung (3). Führen Sie den Code das erste Mal aus, öffnet sich Ihr Browser, in dem Sie den Zugriff des Skripts bestätigen müssen. Ist dies erfolgt, finden Sie in Ihrem File-Explorer eine Authentifizierungsdatei (sc.oauth). Bei einem erneuten Ausführen des Skripts verwendet gar_auth() diese Datei, sodass Sie nicht erneut eine manuelle Authentifizierung durchführen müssen – praktisch, denn zukünftig soll das Skript ja automatisch laufen.
Konfiguration wichtiger Variablen
Nun folgt ein Code-Abschnitt, in dem einige Variablen definiert werden (Abb. 5), die an verschiedenen Stellen des Skripts zum Einsatz kommen. Dass die Variablen hier großgeschrieben werden, ist eine Konvention des Autors, die anzeigt, dass die Variablen erst zu einem späteren Zeitpunkt genutzt werden – grundsätzlich könnten Sie die Variablen auch kleinschreiben. Dies ist somit die Stelle im Skript, an der Sie Ihre eigenen Daten eintragen müssen.
Abbildung 5: Definition globaler Variablen, für die die Daten von den APIs abgefragt werden sollen
Im Detail:
(1) Um die passende View-ID Ihrer GA-Datensicht zu ermitteln, können Sie die auskommentierte Funktion ga_account_list() %>% View() verwenden. Der Pipe-Operator %>% übergibt den von der API zurückgegebenen DataFrame mit den Account-Details an die Funktion View(), welche die Tabelle in einem Explorer statt auf der Console öffnet (Abb. 6). Falls der letzte Satz nur ein böhmisches Dorf für Sie war, seien Sie beruhigt, eine ausführlichere Erklärung folgt im nächsten Artikel. Wichtig ist erst einmal nur, dass Sie Ihre View-ID definieren. Entnehmen Sie dazu die gewünschte View-ID aus der Spalte viewId und tragen Sie sie bei der Variable GA_VIEW_ID ein.
(2) Analog dazu verfahren Sie mit der siteUrl für die Variable GSC_PROP.
(3) Die Sistrix-Daten sollen später auf Domain-Ebene abgefragt werden, entsprechend tragen Sie bei SISTRIX_DOMAIN diese ein. Ihren Sistrix-API-Key für die Variable SISTRIX_APY_KEY finden Sie unter app.sistrix.com/account/api.
(4) START_DATE und END_DATE definieren den abzufragenden Berichtszeitraum. In der aktuellen Konfiguration umfasst dieser sechs Monate rückwirkend vom Beginn des aktuellen Monats bis zum heutigen Datum. floor_date(today(), „month“) %m-% months(6) bedient sich dreier Funktionen aus dem Package lubridate. today() gibt das heutige Datum zurück („2018-01-11“). floor_date(„2018-01-11“), „month“) rundet dann zum Beginn des aktuellen Monats („2018-01-01“). %m-% months(6) subtrahiert von diesem Datum sechs Monate („2018-07-01“). %m-% ist ein besonderer Operator aus dem Package, der das Subtrahieren von Monaten unter Berücksichtigung unterschiedlicher Tageszahlen im Monat und Schaltjahren unterstützt. Sie landen mit dieser Funktion also immer am ersten eines Monats.
Die definierten Variablen können Sie nun im Environment sehen (Abb. 7).
Abbildung 6: Data-Explorer mit den GA-AccountsAbbildung 7: Environment oder Variable-Explorer listet alle zugewiesenen Variablen
GA-Sessions abfragen
Wenn die Konfiguration abgeschlossen ist, kann mit der ersten API-Abfrage begonnen werden. Als Erstes sollen die Sessions, die aus den Channels Organic Search resp. Direct resultieren, aus GA abgerufen werden (Abb. 8). Um die Abfrage auf diese Dimensionen einzuschränken, werden mittels dim_filter() zwei Filter-Komponenten konfiguriert und in der Variablen channel_filter_organic bzw. channel_filter_direct gespeichert (1). Diese werden an eine weitere Funktion filter_clause_ga4() gegeben, welche intern die Filter in eine für die API verständliche Syntax übersetzt (2). Die Funktion google_analytics() führt schließlich die eigentliche Abfrage aus (3). Hier sehen Sie auch die Variablen für die GA-Datensicht sowie das Start- und Enddatum, die Sie zuvor konfiguriert haben. Führen Sie den Code aus, erscheint in Ihrem Environment die Variable ga_sessions (Abb. 9; 1), die Sie mit der Maus anklicken können und die einen DataFrame mit der API-Antwort enthält (2).
Abbildung 8: API-Abfrage der GA-SessionsAbbildung 9: DataFrame mit den GA-Sessions
GSC-Performance-Daten abfragen
Ähnlich funktioniert die anschließende Abfrage der GSC-API (Abb. 10). Von dieser werden verschieden Dimensions-Kombinationen abgefragt. (1) Die erste Abfrage ruft die Clicks, Impressions, CTR und Position für den searchType „web“ auf Tagesbasis ab. Auch hier sehen Sie die Verwendung der anfangs definierten Variablen. (2) Dann erfolgt die Abfrage der Metriken für die Kombination aus Datum und Suchanfrage sowie schließlich (3) für die Kombination aus Datum und URL. Auch hier finden Sie nach dem Ausführen der API-Calls die Antwort-Tabellen in Ihrem Environment.
Abbildung 10: API-Abfrage der GSC-Metriken für verschiedene Dimensionskombinationen
Sistrix-Sichtbarkeitsindex abfragen
Zu guter Letzt müssen Sie noch selbst eine API-Abfrage schreiben, denn es gibt natürlich nicht für alle Datenquellen fertige Packages. Sistrix ist so ein Fall, der aber aufgrund der sehr einfachen Abfrage-Syntax ohne großen Aufwand umgesetzt werden kann. Die Abfrage ist nämlich nur eine URL, deren Query-Parameter die gewünschten Abfragewerte aufnehmen. Wird die URL aufgerufen, erhalten Sie als Antwort eine JSON-Datei. Diese URL bauen Sie mit der Funktion paste0() zusammen (Abb. 11; 1). Konkret verbindet die Funktion die in Klammern angegebenen Argumente. Diese bestehen aus den Bestandteilen der Basis-URL für die Abfrage des historischen Sichtbarkeitsindexes (SI), in die die zuvor definierten Variablen für Ihren API-Key sowie die abzufragende Domain eingefügt werden.
Anschließen fragen Sie die zusammengebauten URLs gegen die API an (2). Dazu verwenden Sie die Funktion fromJSON() aus dem Package jsonlite. Die Funktion führt einen GET-Request aus, nimmt die JSON-Antwort der API entgegen und überführt sie automatisch in eine Liste – ein R-Datentyp zum Speichern hierarchischer Daten. Die Antwort wird zunächst in die jeweiligen Variablen geschrieben. Klicken Sie eine der beiden Variablen im Environment an, sehen Sie, dass das JSON in eine Listen-Struktur überführt wurde (Abb. 12). Hier sehen Sie auch schon den „Weg“, den Sie innerhalb der Liste gehen müssen, um an die SI-Daten heranzukommen. Denn neben diesen erhalten Sie noch weitere Meta-Informationen, wie bspw. die verbrauchten Credits, zurück. Um die Tabelle mit den SI-Daten zu extrahieren, müssen Sie sich an den übergeordneten Listenpunkten entlanghangeln. Dies macht der Ausdruck api_response_desktop$answer$sichtbarkeitsindex[[1]] für den Desktop-SI und überführt den DataFrame in die Variable si_desktop (Abb. 11; 3).
Abbildung 11: Konstruktion der Sistrix-API-AbfrageAbbildung 12: Liste mit der Antwort der Sistrix-API
Fazit und Ausblick
Damit haben Sie das Ziel dieses Beitrags erreicht. Sie haben ein reproduzierbares Skript geschrieben, dass Sie jederzeit erneut ausführen können. Der Berichtszeitraum der abzufragenden Daten passt sich bei jeder erneuten Ausführung automatisch an. Als Resultat liegen Ihnen die GA- , GSC- und Sistrix-Daten in tabellarischer Form vor. Im nächsten Artikel dieser Reihe wird es dann um die Aufbereitung dieser Daten gehen. Aktuell liegen die Daten auf Tagesbasis vor. Für den Report sollen bspw. die GSC-Daten auf Query- resp. URL-Basis aggregiert werden, um somit Tabellen der Top-10-Suchphrasen bzw. URLs der Vorwoche zu erstellen.
R4SEO: Automatisierte Reports mit R generieren (Teil 2)
R4SEO: Automatisierte Reports mit R generieren (Teil 2) – websiteboosting.com
Im ersten Teil dieser Artikelserie in der letzten Ausgabe hat Ihnen Patrick Lürwer gezeigt, wie Sie mit R die Google-Analytics- und Search-Console- sowie SISTRIX-API abfragen können. Im vorliegenden Teil werden Sie lernen, die Daten so aufzubereiten, dass sie zur Darstellung im Report geeignet…
Im ersten Teil dieser Artikelserie in der letzten Ausgabe hat Ihnen Patrick Lürwer gezeigt, wie Sie mit R die Google-Analytics- und Search-Console- sowie SISTRIX-API abfragen können. Im vorliegenden Teil werden Sie lernen, die Daten so aufzubereiten, dass sie zur Darstellung im Report geeignet sind. Dazu werden Sie fehlende Datumspunkte in den DataFrames ergänzen. Sie werden den gleitenden Mittelwert für verschieden Metriken berechnen, um starke Schwankungen der Tagesdaten zu glätten. Außerdem erfahren Sie, wie Sie DataFrames transponieren, um sie von einem weiten in ein langes Format zu bringen.
Im letzten Artikel haben Sie Daten aus drei unterschiedlichen Quellen abgefragt, sodass Ihnen diese nun in tabellarischer Form (DataFrames) in R vorliegen. Aber wie das so häufig ist, haben die APIs die Daten nicht so geliefert, wie sie für die Report-Erstellung benötigt werden. Beispielsweise liefert die Google-Search-Console-API (GSC) nur Datumspunkte zurück, an denen auch tatsächlich Impressions bzw. Clicks stattgefunden haben. Es fehlen folglich die Tage ohne Impressions. Außerdem liegen die Daten auf Tagesbasis vor und sind demzufolge unter Umständen sehr volatil. Sie wollen sie daher glätten, um Trends besser erkennen zu können. Es ist somit unabdingbar, dass Sie die Daten „aufräumen“ und in eine entsprechende Form bringen, um sie für die Visualisierung verwenden zu können. Im Englischen spricht man in dem Fall von tidying – daher auch die Benennung des Packages tidyverse, das Sie verwenden werden. Viele der darin enthaltenen Funktionen dienen allein dazu, Daten zunächst in die richtige Form zu bringen, um mit ihnen arbeiten zu können.
Neues Skript erstellen sowie Daten und Packages laden
Bevor Sie mit dem Aufräumen beginnen, generieren Sie in Ihrem Projekt, das Sie im Zuge des letzten Artikels angelegt haben, ein neues R-Skript mit der Benennung data_tidying.R und kopieren Sie den gesamten Inhalt des Skripts api_calls.R hinein. Führen Sie das Skript aus, damit die aktuellen Daten von den APIs abgefragt werden und zur Weiterverarbeitung in DataFrames in Ihrem Environment vorliegen (Abb. 1).
Abbildung 1: Environment mit geladenen API-Daten
Im Anschluss installieren und laden Sie wieder einige Packages, die für die nachfolgenden Datentransformationen benötigt werden (Abb. 2). tidyverse (https://www.tidyverse.org/) ist eine sehr mächtige Sammlung von Packages für die Datenmanipulation. In diesem Package ist auch ggplot enthalten, welches Sie schon aus dem Artikel von Tobias Aubele kennen und das zum Plotten von Daten dient. Darüber hinaus erweitert es die R-Syntax um den Pipe-Operator (%>%), den Sie im vorherigen Artikel kurz verwendet haben. zoo und padr dienen dem Arbeiten mit Zeitreihen.
Tipp
Eine sehr anschauliche Einleitung in die Syntax und gängige Funktionen des tidyverse finden Sie unter folgendem Link. Das dort beschriebene Package dplyr ist ein Bestandteil des tidyverse und dient der Datenmanipulation, wie Sie sie im Folgenden selbst durchführen werden: speakerdeck.com/omaymas/data-manipulation-with-dplyr-first-steps
Abbildung 2: Installieren bzw. Aktualisieren und Laden der benötigten Packages
Google-Search-Console-Daten vervollständigen
Wie bereits angesprochen, gibt die GSC-API nur Datumspunkte zurück, an denen auch tatsächlich mindestens eine Impression stattgefunden hat. Werden die Daten nur mit der Dimension date abgefragt, wie Sie es für die Variable gsa_dim_date getan haben, liegen meistens für alle Tage Daten vor, denn hier wird die gesamte Website betrachtet. Wird die Dimension date jedoch um die query erweitert, ist dies nicht mehr der Fall, denn nicht jedes Keyword wird an jedem Datum des Berichtszeitraums eine Impression generiert haben. Dies sehen Sie in Abbildung 3, in der die Anzahl der rankenden Keywords gezählt wurde. Um die Tabelle selbst zu reproduzieren, können Sie den Befehl, den Sie im Screenshot sehen, in der Console ausführen. Dadurch ist er kein Bestandteil des Skripts, sondern dient nur dazu, die Daten on-the-fly anzuzeigen. 2018-07-02 hat nur ein Keyword Impressions generiert, 2018-07-05 zwei. An den Tagen dazwischen gab es keine Rankings, sodass keine Datumspunkte von der API zurückgegeben wurden.
Abbildung 3: Zählen der Queries je Tag; fehlende Datumswerte an Tagen ohne Impressions
Wie geschrieben werden fehlende Datumspunkte bei Abfragen, die allein aus der Dimension date bestehen, recht selten vorkommen, da dies bedeuten würde, dass keine einzige Seite an diesem Tag eine Impression generiert hat. Sie müssen sich aber stets bewusst darüber sein, dass dieses Verhalten auftreten kann. Und dann möchten Sie dies auch bestimmt in Ihren Diagrammen sehen. Denn wenn an einem Tag keine Seite ein Ranking aufweisen kann, liegt definitiv etwas im Argen. Solche fehlenden Werte müssen Sie also explizit machen, denn standardmäßig werden beim Plotting Werte für fehlende Datumspunkte interpoliert. In Abbildung 4 sehen Sie einen exemplarischen Verlauf von Impressions je Tag im Monat, wobei die Anzahl der Impressions der Einfachheit halber konstant ist. Für die Datumspunkte 5, 8, 12 / 13, 24 und 30 liegen keine Werte vor. Die blaue Linie (1) wurde ohne ergänzte Datumspunkte geplottet. Hier sehen Sie, dass die Linie zwischen den bestehenden Datumspunkten einfach weitergezogen wurde. Der fehlende Datumspunkt 5 wird durch Interpolation (vereinfacht: dem Mittelwert der beiden bekannten umliegenden Werte) berechnet. Bei der roten Linie (2) wurden die fehlenden Datumspunkte ergänzt, allerdings keine Ersatzwerte eingetragen. Dadurch bricht die Linie an diesen Punkten ab. Die fehlenden Werte liegen nun explizit in den Daten vor. Das Zielbild ist aber die grüne Linie (3). Bei dieser wurden die Datumspunkte ergänzt und die fehlenden Werte durch 0 aufgefüllt. Hier fällt somit bei der Betrachtung des Graphen sofort ins Auge, dass die Impressions auf 0 abgestürzt sind.
Das Auffüllen ist im Übrigen nicht nur beim Plotting wichtig, sondern auch bei der Aggregation der Daten auf einer höheren Zeitebene. Soll beispielsweise der Durchschnitt der Impressions auf Monatsbasis berechnet werden, verfälschen fehlende Werte das Ergebnis. Angenommen, jeder Datumspunkt im Diagramm zeigt 10 Impressions an, wäre der Mittelwert für die blaue Line 10 (10 Impressions * 25 Tage / 25 Tage), für die grüne Linie hingegen 8,06 ( (10 Impressions * 15 Tage + 0 Impressions * 6 Tage) / 31 Tage). Dies müssen Sie daher immer berücksichtigen, wenn Sie mit den Rohdaten aus der GSC arbeiten.
Abbildung 4: Fehlende Datumspunkte und Werte auffüllen, um Verfälschungen des Graphen zu vermeiden
Zurück zum Skript: Nachdem Sie die Packages geladen haben, fügen Sie den Code-Abschnitt, wie in Abbildung 5 zu sehen, ein. Der DataFrame gsa_dim_date, der die Performance-Daten auf Tagesbasis enthält, wird an die Funktion pad() aus dem Package padr gegeben. Die Funktion erkennt automatisch die Datumsspalte und füllt die fehlenden Datumspunkte auf. Über die Argumente start_val und end_val definieren Sie die untere und obere Grenze des aufzufüllenden Berichtszeitraums. Die hierfür verwendeten Variablen START_DATE und END_DATE sind erneut jene, die Sie bereits bei den API-Abfragen genutzt haben. Nach diesem Schritt liegen alle Datumspunkte vor, allerdings enthalten die Spalten clicks und impressions noch keine Werte für diese Punkte. Diese geben Sie durch die anschließende Funktion replace_na() aus dem Package tidyverse an. Der bearbeitete DataFrame wird wieder in die Variable gsa_dim_date zurückgeschrieben.
Abbildung 5: Fehlende Datumspunkte ergänzen und Metriken mit 0 auffüllen
In Abbildung 6 sehen Sie die einzelnen Schritte noch einmal im Detail anhand eines exemplarischen DataFrames mit Daten für eine Woche. (1) sind die Rohdaten, bei denen drei Tage fehlen. Bei (2) wurden mittels pad() die fehlenden Datumspunkte ergänzt, die Werte für die Metriken fehlen aber noch (NA; not available). In (3) wurden diese Metriken via replace_na() mit dem Wert 0 aufgefüllt.
Abbildung 6: Exemplarischer DataFrame mit aufgefüllten Werten
Gleitenden Mittelwert der Impressions und Clicks berechnen
Für die Performance-Daten liegt Ihnen nun der gesamte Berichtszeitraum im DataFrame gsa_dim_date auf Tagesbasis vor. Bei der Visualisierung sorgt dies jedoch dafür, dass der Graph stark „zappeln“ wird, wenn bspw. die Werte für die Impressions starken Schwankungen unterliegen. In Abbildung 7 (1) sehen Sie dies für exemplarische Daten eines Jahres. Hier einen Trend zu erkennen, ist somit sehr schwer, da er im Rauschen des Graphen untergehen kann. Ein gängiges Mittel, um den Graphen zu glätten, ist daher, den gleitenden Mittelwert für ein Zeitfenster von sieben Tagen zu berechnen (2).
Hinweis
Wie Sie die Daten visualisieren, erfahren Sie in einem späteren Teil. Hier dienen die Plots zunächst nur der Veranschaulichung, warum die Daten wie beschrieben transformiert werden.
Abbildung 7: Plotting der Rohdaten versus gleitenden Mittelwert
Sie müssen sich dazu vorstellen, dass von einer gegebenen Zeitreihe fortschreitend sieben Tage betrachtet werden und für diese der Mittelwert gebildet wird. In Abbildung 8 sehen Sie dies beispielhaft für ein Zeitfenster von drei Tagen. Zunächst wird der Mittelwert für die Tage 1 bis 3 berechnet, dann für die Tage 2 bis 4 usw.
Abbildung 8: Exemplarische Berechnung des gleitenden Mittelwerts für ein Zeitfenster von drei Tagen
Den gleitenden Mittelwert berechnen Sie mit dem Code-Abschnitt, den Sie in Abbildung 9 sehen. Der DataFrame gsa_dim_date wird an die Funktion mutate() gegeben, die eine bestehende Spalte bearbeiten oder eine neue Spalte hinzufügen kann. In diesem Fall werden die Spalten rollmean_clicks und rollmean_impressions hinzugefügt. Die Werte der beiden Spalten werden mit der Funktion rollmean() aus dem Package zoo berechnet. Das erste Argument x nimmt die Spalte auf, auf deren Basis der gleitende Mittelwert berechnet werden soll. Das Argument k definiert das Zeitfenster – hier sieben Tage. Mit fill kann der Wert angegeben werden, der in die Zellen geschrieben werden soll, für die aufgrund der Reduktion der Daten keine Werte mehr vorliegen. Das sehen Sie ebenfalls in Abbildung 8. Für die Datumspunkte 1 und 2 kann kein Mittelwert berechnet werden, da das Zeitfenster ansonsten links über den Rand des Datumsbereichs hinauslaufen würde. Entsprechend werden diese beiden Datumspunkte mit NAs aufgefüllt. Das Argument align steuert dieses Verhalten. Es zeigt an, ob der berechnete Mittelwert am rechten Rand des Berichtszeitraums endet und demnach links mit NAs aufgefüllt werden soll oder ob am Datumspunkt 1 mit dem Mittelwert begonnen wird und somit die NAs am rechten Rand eingetragen werden.
Für die exemplarischen Daten der Abbildung 8 sähe die finale Tabelle wie in Abbildung 10 dargestellt aus.
Abbildung 9: Berechnung des gleitenden Mittelwerts für Clicks und ImpressionsAbbildung 10: Beispieltabelle mit berechnetem gleitendem Mittelwert
Umwandlung des DataFrames von einem weiten in ein langes Format
Damit folgt der letzte Schritt zum Aufräumen der Performance-Daten. Ihr DataFrame sieht zum jetzigen Zeitpunkt wie in Abbildung 11 aus. Man spricht in diesem Fall von einer weiten Tabelle, denn je Datumspunkt liegen die einzelnen Metriken (clicks, impressions, ctr etc.) als Spalten vor. Für die Visualisierung mit ggplot müssen die Daten jedoch in einem langen Format vorliegen. Konkret bedeutet dies, dass die Benennungen der bisherigen Spalten die Werte einer neuen Spalte bilden. Die Tabelle wird quasi gedreht, wobei die Datumsspalte als Ankerpunkt dient. Das umgekehrte Verfahren, die Überführung einer langen in eine weite Tabelle, kennen Sie wahrscheinlich aus Excel, wenn Sie dort eine Pivot-Tabelle erstellen.
Das war jetzt sehr abstrakt: Eine schematische Darstellung mit nur vier Metrik-Spalten sehen Sie daher in Abbildung 12.
Abbildung 11: DataFrame gsc_dim_date mit den ergänzten Spalten für die gleitenden MittelwerteAbbildung 12: Umwandlung einer weiten in eine lange Tabelle mittels gather()
Ihren gsa_dim_date DataFrame überführen Sie mit dem Code aus Abbildung 13. select() dient dazu, nur die Spalten date, rollmean_clicks und rollmean_impressions beizubehalten. Die restlichen Spalten clicks, impressions, ctr und position löschen Sie somit aus dem DataFrame, da sie in der späteren Visualisierung nicht genutzt werden. Die Funktion gather() transponiert dann den DataFrame. Mit dem Argument key geben Sie den Namen der neuen Spalte an, in die die bisherigen Spaltenbenennungen als Werte überführt werden. Das Gleiche machen Sie mit dem Argument value für die neue Spalte, die die Werte der jeweiligen Metrik-Spalten aufnimmt. Damit haben Sie das Aufräumen der GSC-Daten erledigt. Ihr DataFrame sieht nun wie in Abbildung 14 aus. Die DataFrames mit den Queries (gsa_dim_date_query) resp. den URLs (gsa_dim_date_page) werden Sie im nächsten Teil dieser Reihe aufbereiten.
Abbildung 13: Überführen des weiten DataFrames gsa_dim_date in ein langes FormatAbbildung 14: Die ersten Zeilen des langen DataFrames gsa_dim_date
Google-Analytics-Daten vervollständigen
Analog zu den Performance-Daten aus der GSC müssen Sie noch die Google-Analytics-Daten (GA) aufräumen. Auch bei diesen beginnen Sie damit, fehlende Datumswerte zu ergänzen. Insbesondere bei den GA-Daten ist dies eine reine Vorsichtsmaßnahme, da Sie diese für die Channels Organic Search und Direct abgefragt haben. Dass an einem Tag keine organischen oder direkten Sessions auf Ihrer Website erfolgen, ist höchst unwahrscheinlich – kann aber nichtsdestotrotz bei sehr kleinen bzw. neuen Websites vorkommen. Um sich auf den später generierten Report verlassen zu können, empfiehlt es sich daher, immer für eine „saubere“ Datenbasis zu sorgen.
Fügen Sie den Code aus Abbildung 15 in Ihr Skript ein. Der Unterschied zum Code für die GCS-Daten aus Abbildung 5 besteht hier in dem zusätzlichen Argument group der Funktion pad(). Sie erinnern sich: Diese ergänzt fehlende Datumspunkte. Die Besonderheit des GA-DataFrames besteht darin, dass dieser bereits im langen Format von der API zurückkommt (Abb. 16). Er besteht nur aus den drei Spalten date, channelGrouping und sessions. Die Spalte channelGrouping ist vergleichbar mit Spalte metric im DataFrame gsa_dim_date. Sie qualifiziert die nebenstehenden Werte in der Spalte sessions (vergleichbar mit value im GSC-DataFrame) nach den Groups Direct und Organic Search. Das Argument group ist daher nötig, um die fehlenden Datumspunkte individuell für die beiden Ausprägungen Direct und Organic Search zu ermitteln. In der Abbildung 16 sehen Sie bspw., dass am 2018-07-01 zwar eine Direct-Session erfolgt ist, für Organic Search jedoch kein Wert vorliegt. Für 2018-07-02 verhält es sich genau andersherum. Für Ersteres muss somit der Organic-Search-, für Letzteres der Direct-Wert ergänzt werden (Abb. 17).
Abbildung 15: Fehlende Datumspunkte ergänzen und Sessions mit 0 auffüllenAbbildung 16: Langer DataFrame ga_sessions mit teilweise fehlenden Kombinationen aus date und channelGroupingAbbildung 17: DataFrame ga_sessions mit ergänzten Kombinationen aus date und channelGrouping
Gleitenden Mittelwert der GA-Sessions berechnen
Im Anschluss errechnen Sie den gleitenden Mittelwert für die Sessions (Abb. 18). Auch hier müssen Sie dies separat für die beiden Channels machen. Daher erfolgt in der zweiten Zeile ein group_by() der Spalte channelGrouping, sodass die nachfolgenden Funktion rollmean() separat auf diese beiden Gruppen angewendet wird.
Abbildung 18: Berechnung des gleitenden Mittelwerts der Sessions je channelGrouping
Fazit
Gratulation! Wenn Sie es bis hierher geschafft haben, sind Sie schon ein gutes Stück in die Gefilde der Datentransformation vorgedrungen. Sie haben das Wehklagen eines jeden Daten-Analysten nachvollziehen gelernt, dass Analysen zu 80 % aus Datenbereinigung und nur zu 20 % aus der eigentlich spannenden Analysetätigkeit bestehen.
Darüber hinaus haben Sie erfahren, wie Sie fehlende Datumswerte in Zeitreihen vervollständigen, um Verfälschungen bei Datenaggregationen zu vermeiden. Außerdem haben Sie den gleitenden Mittelwert verschiedener Metriken berechnet, um Graphen zu glätten und somit Trends besser erkennbar zu machen. Last but not least haben Sie ein mächtiges Werkzeug an die Hand bekommen, um Tabellen zu transponieren und sie so in ein handhabbares langes Format zu bringen.
Lesen Sie im dritten Teil in der nächsten Ausgabe, wie Sie Ihr SEO-Reporting mit R automatisieren können. So lassen sich z. B. mit wenig Aufwand die Top-SEO-Seiten nach Klicks und die Top-Suchanfragen aus der Google Search Console ermitteln und für Berichte in speziellen DataFrames zusammenfassen.
Title-Geddon – war da was bei Ihnen?
R-Leuchtungen! Teil 9
R-Leuchtungen! Teil 9: Title-Geddon – war da was bei Ihnen? – websiteboosting.com
In den Ausgaben bis 54 bis 58 der Website Boosting konnten Sie in der Serie „R4SEO“ von Patrick Lürwer nachvollziehen, wie man die kostenlose Software R verwendet, was sie leistet und wie man sie nutzbringend für die eigene Arbeit für SEO bzw. die Aufklärung im Online-Marketing einsetzen kann. R…
In den Ausgaben bis 54 bis 58 der Website Boosting konnten Sie in der Serie „R4SEO“ von Patrick Lürwer nachvollziehen, wie man die kostenlose Software R verwendet, was sie leistet und wie man sie nutzbringend für die eigene Arbeit für SEO bzw. die Aufklärung im Online-Marketing einsetzen kann. R wurde ja ursprünglich für Statistik entwickelt. Wer das bisher als Entschuldigung verwendet hat, es deswegen links liegen zu lassen, dem sei versichert, dass er damit komplett falschliegt. R kann für den Einsatz im Unternehmen, allen Bereichen voran „Online“, sehr viel mehr leisten, als statistische Berechnungen durchzuführen. Genau genommen ist es ein wirklich nützliches Helferlein bei allen Aufgaben im Umgang mit größeren Datenmengen, mit Daten, die man erst in eine gewisse Struktur bringen muss, und bei der automatischen oder halb automatischen Datenbeschaffung aus praktisch fast allen Quellen aus dem Web! Für die interessierten Einsteiger, aber auch für alle, die nach der Serie von Patrick Lürwer „R-Blut“ geleckt haben, startete in der Ausgabe 62 die neue anwendungsorientierte Serie „R-Leuchtungen“. Sie werden in jeder Ausgabe erfahren, wie Sie ohne Programmierkenntnisse jeweils ein definiertes und in der Online-Praxis häufiger auftretendes Problem rund um das Thema Daten und Auswertungen lösen können. Und keine Sorge, die kleinen Hilfe-Tutorials nehmen Sie Schritt für Schritt an der Hand, sodass Sie auch als Neuling von der Power von R profitieren können. Was hält Sie also ab, das einfach mal auszuprobieren? Die einzelnen Schritte müssen Sie übrigens nicht im Detail verstanden haben. Um an die hilfreichen Daten für ein besseres Ranking zu kommen, müssen Sie im Prinzip nur nachmachen, was Sie hier beschrieben finden. Für dieses Beispiel brauchen Sie übrigens keinerlei kostenpflichtige Tools.
Worum geht es diesmal?
Um den 21.08.2021 herum hat Google das sogenannte Title-Update ausgerollt. Dabei wurde in den Suchergebnissen bei nicht wenigen Seiten der im jeweiligen Quellcode hinterlegte Title durch einen von Google generierten Title ersetzt. Das führte zu einigem Aufruhr bei den aufmerksamen Sitebetreibern, weil zum Teil wohl weniger passende Title erzeugt wurden und man zum anderen einen gewissen Kontrollverlust verspürte.
Einige Tools, so z. B. die SISTRIX-Toolbox, zeigen bereits für einzelne Domains an, ob und welche Title getauscht wurden. Ebenso gibt es bereits Browser-Plug-ins, die Veränderungen direkt in den Suchergebnissen sichtbar machen. Das alles sind aber nur punktuelle Hinweise und bisher bekommt man kaum weiter verarbeitbare Daten geliefert bzw. kann die Ergebnisse nicht downloaden für Checklisten und Handlungsanweisungen.
Die Kernfrage ist, ob sich bei (nahezu) gleichbleibender Position eines Keywords die CTR, also die Klickrate, signifikant derart verändert hat, dass sich der Grund beim Title-Tausch durch Google vermuten lässt. Bleibt z. B. vor und nach dem Update die Position 3 stabil stehen, aber die Klickrate sinkt von 15 % auf 5 %, dann könnte mit hoher Wahrscheinlichkeit das veränderte Ergebnissnippet dafür verantwortlich sein, da sich sonst ja nichts verändert hat. Würde die Position steigen oder fallen, würde sich in jedem Fall bekanntlich auch immer die CTR ändern. Insofern gilt es, Rankings zu filtern, deren Position sich nicht stark verändert hat, jedenfalls nicht über eine normale Schwankungsbreite hinaus. Natürlich tritt auch bei der CTR eine gewisse Schwankung auf.
Die Aufgabe lautet also: Finde alle Rankings, deren Position gleich geblieben ist UND deren CTR sich deutlich verändert hat. Dabei sollten alle Suchphrasen, die als Besonderheit den Domainnamen (Brandbegriffe) enthalten, ignoriert werden.
Das Skript in der vorliegenden Ausgabe nimmt sich dieses Problems an und ist wie folgt strukturiert:
Abholen aller Rankingdaten für zwei definierbare Zeitfenster (vor und nach dem Update)
Definieren gewisser Schwankungstoleranzen für die CTR
Definieren gewisser Schwankungstoleranzen für die Position
Angabe der Brand-Suchbegriffe (Domainname)
Filtern aller ausgeschlossenen Fälle von Punkt 2 bis 4.
Ausgabe der übrig gebliebenen Daten in ein CSV-File zur weiteren Verwendung
Um tatsächlich umfassend mit den Rohdaten direkt von Google arbeiten zu können, muss ein sog. (kostenloses) Entwicklertoken von Google vorliegen (siehe den Infokasten am Rand).
Ihr API-Account bei Google
Um automatisiert bzw. computergesteuert Daten von Google-Tools holen zu können, brauchen Sie dort einen „Developer-Account“. Für diesen bekommen Sie eine von Google erzeugte Mailadresse und ein File mit der Endung .json für die Authentifizierung Ihres Computers bzw. für R, um Daten zu holen. Die Mailadresse dient dazu, einen Nutzer für die Search Console anlegen zu können, und mit dem File kann sich eine Maschine gegenüber Google als berechtigt ausweisen. Wie Sie einen solchen Account anlegen können, haben wir in der Ausgabe 65 ausführlich beschrieben. Falls Sie den Account da angelegt haben, können Sie jetzt erneut darauf zugreifen und müssen nichts weiter tun.
Haben Sie das übersprungen, müssen und sollten Sie das (Schritt 1 und 2 im oben genannten Beitrag) unbedingt nachholen. Bereits in den vergangenen Ausgaben hatten wir Ihnen immer wieder Skripts an die Hand gegeben, mit denen Sie wirklich sehr nützliche Auswertungen mit echten Google-Daten ganz einfach mit wenigen Klicks erzeugen können. Ohne diesen Account bekommen Sie leider keine ausführlichen Daten. Und ohne diese Daten können Sie natürlich auch keine eigenen und detaillierten Hinweise auf Optimierungsmöglichkeiten für Ihr Ranking erzeugen.
Abbildung 1: An einigen Stellen im Code („# TODO“) müssen einfache Anpassungen vorgenommen werden
Schritt 1: Das R-Skript downloaden und die Parameter eingeben
Holen Sie sich unter einfach.st/rcode6 das Skript für diese Ausgabe 70 bzw. kopieren Sie von dort ganz einfach den Code in Ihre Zwischenablage. Starten Sie R-Studio als „Benutzerhülle“ für R. Mit File/New File erhalten Sie links oben ein neues, noch leeres Fenster für den R-Code. Kopieren Sie ihn von der Webseite direkt in dieses Fenster.
Stellen Sie sicher, dass R mit dem richtigen Arbeitsverzeichnis (Working Directory, kurz WD) arbeitet bzw. legen Sie das Verzeichnis auf Ihrem Computer fest, das für diese Session verwendet werden soll. Dazu klicken Sie sich einfach rechts unten in dem Fenster wie in Abbildung 2 unter den beiden Ziffern 1 gezeigt zu dem gewünschten Verzeichnis durch. Achtung: In diesem Verzeichnis muss dann auch die Datei (oder eine Kopie davon) von Google liegen, die man zu Authentifizierung des Computers braucht. Sie endet auf .json und enthält vorne die bei Google angegebene Mailadresse, gefolgt von einer Zahlen-/Buchstabenreihenfolge. Sie sieht in etwa so aus:
mein-accountname-cr4436ad9828.json
Stimmt das angezeigte Verzeichnis, klickt man einfach unter dem Zahnradsymbol „More“ auf „Set As Working Directory“. Im Fenster links daneben wird dies nun bestätigt mit:
> setwd("~/was/sie/ausgewaehlt/haben")
Wie immer müssen für R dann noch bestimmte Funktionsbibliotheken (Librarys) installiert bzw. aufgerufen werden. Nach dem erstmaligen Installieren mit dem Befehl
install.packages("libraryname")
behält R diese Bibliothek in ihrem Dateispeicherbereich. Sie muss dann nicht mehr installiert werden. Der Aufruf einer Bibliothek, um damit arbeiten zu können, bzw. das Laden in den aktiven Arbeitsspeicher muss hingegen nach jedem Start von R vollzogen werden. Der Befehl dazu lautet:
library(libraryname)
Es gilt zu beachten, dass hier keine Anführungszeichen wie beim Installieren verwendet werden. Um den Aufruf einer Bibliothek in den Arbeitsspeicher muss man sich nicht aktiv kümmern, weil er in der Regel immer am Anfang im Skript steht und daher sowieso immer mit ausgeführt wird. Wer die R-Leuchtungen der letzten Ausgaben aktiv angewendet hat, hat bereits alle nötigen Bibliotheken installiert und kann den Code daher später einfach durchlaufen lassen. Bibliotheken kann man übrigens auch leicht über den Menüpunkt „Tools“ und dort „Install Packages“ einzeln installieren. R sucht sich die Speicherorte im Web von alleine.
Abbildung 2: So ist R-Studio strukturell aufgeteilt
Die Anpassungen im Skript sind dort nochmals dokumentiert (alle Zeilen mit einem führenden „#“ stellen Kommentarzeilen dar und sind kein Code).
Sie müssen an sechs Stellen Eingaben/Änderungen vornehmen. Diese sind alle mit „#TODO“ gekennzeichnet.
Zunächst müssen Sie den genauen Namen Ihrer Authentifizierungsdatei (die mit .json am Ende) angeben. Überschreiben Sie einfach die Vorgabe entsprechend:
Optional: Möchten Sie Suchanfragen nach Ihrem Domainnamen/Brand ignorieren? Dann überschreiben Sie einfach ebenfalls die Vorbelegungen. Brauchen Sie mehr Zeilen, kopieren Sie einfach z. B. die Zeile 2 und fügen Sie diese mit einem überschriebenen Suchwort wieder ein. Diese müssen nur jeweils durch Anführungszeichen und ein abschließendes Komma getrennt werden:
PRE steht für „vor dem Update“ und POST entsprechend für einen Zeitraum danach. Das Startdatum ist im Beispiel hier so gewählt, dass sicherheitshalber ein Zeitraum einige Tage vor dem Title-Update fixiert wurde. Bei Bedarf können Sie beide Zeiträume entsprechend anpassen, sollten z. B. neue Updates das nötig erscheinen lassen.
Nicht nur für Title-Updates!
Mit dem vorliegenden Skript können Sie übrigens jede Art von Klickveränderungen Ihrer Suchphrasen „überwachen“ bzw. prüfen. Da Sie den Start- und Endzeitraum des Vergleichs frei wählen können, lässt sich damit prinzipiell auch jeder Zeitraum mit jedem anderen vergleichen! Damit haben Sie für jede Art von Sonderanalyse ein recht machtvolles kleines Skript an der Hand, das Ihnen in wenigen Sekunden datengestützte Antworten liefern kann.
Optional: Legen Sie einen Wert fest, um den die Position schwanken darf, ohne gleich als echte Positionsveränderung zu gelten. Da Google Kommawerte bzw. die durchschnittliche Position angibt, schwankt diese eigentlich fast immer um einige Prozentpunkte hinter dem Komma (das in R mit einem Punkt gesetzt wird). Würde man diese Schwankung nicht berücksichtigen, gäbe es für jedes Keyword eine Positionsveränderung, weil bereits ein Ansteigen von Position 2,3 auf 2,4 als Änderung gelten würde. Vorbelegt ist der Wert 0,9, aber Sie können diesen Ihren Bedürfnissen entsprechend verändern. Das macht dann Sinn, wenn Sie zu viele oder zu wenige Daten in der Auswertung haben. Da dies von Domain zu Domain schwankt, kann man keine generellen, verbindlichen Werte angeben. Hier müssen Sie ggf. etwas experimentieren.
POSITION_FLUCTUATION <- 0.9
Optional: Ebenso macht es Sinn, einen natürlichen Korridor für Schwankungen im CTR-Wert zu berücksichtigen. Hier wurde 5 % vorbelegt. Das bedeutet, dass eine Schwankung unter oder über 5 % noch nicht als nennenswerte Veränderung gesehen wird und die Daten weggefiltert werden, die sich innerhalb dieser Breite befinden. Sollten Sie zu viele oder zu wenig Daten bekommen, versuchen Sie einfach, das Skript mit veränderten Werten noch mal laufen zu lassen.
CTR_FLUCTUATION <- 5
Das war auch schon alles, was Sie hinterlegen bzw. anpassen müssen. Klicken Sie nun einfach auf „Source“ rechts oben im linken oberen Fenster (Abbildung 3). Dies löst das Abarbeiten des gesamten Skripts auf einen Rutsch aus.
Abbildung 3: Ein Mausklick auf „Source“ startet das komplette Skript
Das Durchlaufen kann je nach Datenumfang etwas dauern, da die Daten von der Search Console im Batchbetrieb für jeden angeforderten Tag (über das Zeitintervall oben definiert) abgeholt werden (Abbildung 4). Anschließend werden alle empfangenen Daten automatisch ohne weiteres Zutun vom Skript verarbeitet.
Abbildung 4: So bzw. so ähnlich sieht das laufende Skript im Consolenfenster aus
Am Ende des Skripts sorgt noch die letzte Codezeile dafür, dass die fertigen Daten in einer CSV namens „ctr_vergleich.csv“ im Arbeitsverzeichnis gespeichert werden:
write_csv2(gsc_data, "ctr_vergleich.csv")
Selbstverständlich können Sie hier auch einen eigenen Dateinamen vergeben, indem Sie die Vorgabe „ctr_vergleich.csv“ im Skript einfach nach Ihren Wünschen verändern.
Schritt 2: Sehen Sie sich die Auswertungen an und arbeiten Sie damit
Wenn Sie die erzeugte Datei öffnen, finden Sie alle URLs, die in dem von Ihnen definierten Zeitraum bei gleichbleibender Position (innerhalb der definierten Schwankungsbreite) eine CTR-Veränderung über der Prozentzahl haben, die Sie definiert haben. Das ist der Startpunkt für weitere Analysen. Durch die Verwendung der SEO-Tools für Excel kann man die Tabelle problemlos mit weiteren Metriken anreichern, wie z. B. den aktuellen Title und den Inhalt der H1 dazu holen. Dem Vernehmen nach wird beim Austausch der Title von Google häufig auf den Inhalt der H1 zurückgegriffen, sofern er nicht identisch mit dem Title oder wenig aussagekräftig ist.
Beachten Sie bitte, dass Sie von der Google Search Console deutlich mehr Daten bekommen als mit vielen anderen Tools. Es ist daher nicht unwahrscheinlich, dass Sie auch für nur wenige Impressions oder Klicks Datensätze im Ergebnis bekommen. Hier sind die Änderungen der CTR natürlich statistisch nicht aussagekräftig bzw. belastbar. Sie sollten Sie daher in Excel am besten wegfiltern (Zahlenfilter/größer als).
Abbildung 5: Formatiert, nach CTR-Differenz sortiert und nach Klicks gefiltertAbbildung 6: Einige Tools wie z. B. SISTRIX zeigen veränderte Titles in den Suchsnippets für zwei Datumsangaben an
Bei den meisten Analysen, die wir testhalber vorgenommen haben, hat sich das „Title-Geddon“, wie das Update im Netz zum Teil genannt wurde, übrigens nicht besonders stark ausgewirkt. Es gab zwar möglicherweise viele Title, die tatsächlich getauscht wurden, in eine stark messbare CTR-Veränderung mündete dies allerdings nicht. Die Fälle, die wir extrahieren konnten, zeigten bei einer manuellen Einzelfallprüfung, dass man sicherlich mit der getauschten Zeile gut leben kann.
Trotzdem gibt es im Web zum Teil heftige Beschwerden von Webmaster, dass die Algorithmen alles deutlich verschlimmert hätten. Es ist noch zu früh, stabile Aussagen dazu zu machen, vor allem weil Google angekündigt hat, nochmals nachbessern zu wollen. Trotzdem kann es natürlich nichts schaden, sich einmal in Ruhe anzusehen, ob die Performance Ihrer Suchergebnisse möglicherweise gelitten hat. Hier hilft Ihnen das vorliegende Skript!
Python im Web
Python im Web
Dynamisches HTML im Browser mit PyScript statt JavaScript
Browser führen nur JavaScript aus? Nicht mehr! PyScript tritt als Alternative zu JavaScript auf. Wir erklären, wie das möglich ist, und programmieren als Beispiel ein Spiel mit der neuen Technik.
Von Pina Merkert
kompakt
PyScript nutzt die maschinennahe Sprache WebAssembly, um Python mit der JavaScript-Engine eines Browsers auszuführen.
Über PyScript-Funktionen kann der Python-Code auf das DOM zugreifen, was dynamisches HTML ermöglicht.
PyScript kann JavaScript ersetzen, es lädt aber wesentlich langsamer.
Beim Versuch, auf eine Objekteigenschaft zuzugreifen, wird die Eigenschaft nicht nur in dem Objekt selbst, sondern auch in seinem Prototyp und dem Prototyp des Prototyps gesucht. Wenn Ihnen Sätze wie dieser auch rätselhaft vorkommen, ist JavaScript wohl auch nicht Ihre Muttersprache. Python ist da oft zugänglicher, der Code hat weniger Zeilen und das Sprachdesign ist auf Lesbarkeit optimiert. Nur leider muss Python immer lokal installiert sein, die allgegenwärtigen Webbrowser verarbeiten nur JavaScript. Oder etwa nicht?
Dass Python nicht im Browser läuft, stimmt nicht mehr: Mit einer trickreichen Software namens „Pyodide“ interpretieren Webseiten auch Python-Code. Python-Entwickler können auf diesem Weg JavaScript durch Python ersetzen. Sie programmieren dann in Python mit PyScript-Funktionen statt in JavaScript. Wir zeigen, wie Sie mit PyScript loslegen.
Als Beispiel haben wir uns von dem Worträtsel „Wordle“ inspirieren lassen und ein Rätsel für Nerds mit dem Namen „Nerdle“ programmiert. Die Spielregeln sind einfach: PyScript wählt aus einer langen Liste mit Begriffen aus der Technikwelt mit fünf Zeichen (Nerdle ist schwieriger als Wordle, weil unser Rätsel Wörter mit Ziffern und Sonderzeichen enthält) einen zufälligen aus, den Sie erraten müssen. Dafür tippen Sie über die Bildschirmtastatur zunächst einen Begriff. Jeder geratene Begriff muss in der Liste stehen, damit das Spiel die Eingabe akzeptiert. Wenn ein Zeichen des geratenen Begriffs an der gleichen Stelle steht wie im gesuchten Begriff, wird es grün. Kommt ein Zeichen irgendwo im gesuchten Begriff vor, wird es gelb. Zeichen, die gar nicht vorkommen, werden grau. Die Tasten der Bildschirmtastatur verfärben sich genauso. Diese Farben geben Hinweise für den nächsten Begriff, sodass Sie mit zusätzlichen Versuchen immer mehr über den gesuchten Begriff erfahren. Wenn Sie spätestens beim sechsten Versuch richtig raten, gewinnen Sie das Spiel. Wenn Sie zu oft falsch raten, sollten Sie mehr c’t lesen *zwinkersmiley*. Ohne selbst zu programmieren, können Sie das Spiel sofort unter nerdle.pinae.net ausprobieren; den Code finden Sie als Open Source (GPLv3) über ct.de/ynk9.
WebAssembly
Browser integrieren weiterhin keinen Python-Interpreter. Sie führen aber in ihrer virtuellen Maschine schon länger WebAssembly aus. WebAssembly ist eine maschinennahe Sprache, die der Browser innerhalb von Millisekunden in Maschinencode übersetzt. Das funktioniert so gut, dass WebAssembly meist nur wenige Prozent langsamer läuft als gleicher Code, den ein Compiler direkt in Maschinencode übersetzt hat. Da der Code aber in der Browser-Sandbox läuft, ist nicht jedes Programm WebAssembly-tauglich. Beispielsweise verbieten Browser direkten Zugriff aufs Dateisystem oder Hardware wie Netzwerkkarten.
Das Pyodide-Projekt hat die Python-Referenzimplementierung CPython so modifiziert, dass sie nach WebAssembly kompiliert. Damit läuft Python zwar im Browser, man sieht davon aber noch nichts. An dieser Stelle kommt PyScript ins Spiel: PyScript bringt Funktionen mit, um vom Browser-Python auf den DOM-Tree zuzugreifen, also auf die HTML-Struktur der Webseite. Außerdem stellt es eigene HTML-Tags bereit, die den Code aufnehmen, Module nachladen und Eingabefelder bereitstellen. Das Projekt steht noch am Anfang: Release-Nummern sind im Datumsformat, die Versionen auf GitHub als „Pre-release“ getaggt. Manchen Funktionen sieht man den frühen Entwicklungsstand noch an. Beispielsweise muss man per Hand Funktionen einkapseln, um sie ins Ereignissystem von JavaScript einzuklinken. Trotzdem funktioniert der Code bereits gut genug für ein Browserspiel.
Einbinden
PyScript bindet man wie ein JavaScript-Framework ein, indem man zwei Tags im <head> der Webseite ergänzt:
Den Code lädt der Browser dann aus dem Content Delivery Network (CDN) der PyScript-Entwickler, man bekommt also immer die aktuellste Version. Um Probleme bei Updates zu umgehen, könnte man PyScript auch selbst übersetzen und hosten. Momentan raten wir aber noch davon ab, PyScript produktiv einzusetzen, weil sich in den kommenden Monaten sicherlich noch einiges an den Funktionssignaturen ändern kann.
Danach kann man einfach irgendwo im HTML der Seite den <py-script>-Tag einfügen und in dem Python-Code platzieren. Für ein Hallo-Welt-Programm braucht man nur drei Zeilen:
<py-script>
print("Hallo Welt.")
</py-script>
Module
Python funktioniert im Browser wie gewohnt. Das bezieht sich auch auf Module, die man wie üblich mit import ins Programm einbindet:
import random
wordlist = ["CT.DE", "RULEZ"]
word = random.choice(wordlist)
Da dem Browser der Python-Paketmanager pip fehlt, packt man externe Module mit Spiegelstrichen in den <py-env>-Tag und PyScript kümmert sich ums Nachladen:
<py-env>
- numpy
- matplotlib
</py-env>
Es stehen schon einige beliebte Module wie numpy und matplotlib zur Verfügung, solche mit Hardwarezugriff wie requests können aber nicht funktionieren. Gibt man ein Modul im <py-env>-Tag an, muss man es trotzdem im Code mit einem import einbinden.
Wortlisten per Ajax asynchron laden
Damit wir die Begriffe zentral verwalten können, wollten wir sie nicht als ellenlange Liste hardcoden, sondern lieber mit Ajax nachladen. In normalem Python-Code würde man für so etwas eine Bibliothek wie requests nehmen. Die läuft aber im Browser nicht. Der kann jedoch von sich aus Daten laden, was die Funktion pyfetch() aus dem pyodide-Modul anstößt.
Ajax-Anfragen sind von Natur aus asynchron, weshalb pyfetch() nur in asynchronen Funktionen funktioniert. Die erzeugt man mit async def statt def. Da sie dem normalen Code nicht im Weg stehen, kann man in so einer Funktion problemlos mit await auf Antworten warten, ohne das ganze Programm auszubremsen:
from pyodide.http import pyfetch
from pyodide import JsException
from js import console
async def load_wordlist():
try:
response = await pyfetch(
url="https://raw.githubusercontent.com/pinae/Nerdle/main/nerdle-begriffe.txt",
method="GET",
headers={"Content-Type":
"text/plain"})
if response.ok:
data = await response.string()
console.log(data.split())
return data.split()
except JsException:
return None
Die JsException ist die Basisklasse aller JavaScript-Fehler, die PyScript automatisch kapselt. Man könnte hier auch spezifische Exceptions fangen, um aussagekräftige Fehlermeldungen anzuzeigen.
Das Speichern der Liste und das Auswählen des zufälligen Worts übernimmt die Funktion pick_word(). Auch sie ist asynchron, weil sie mit await auf die Rückgabe von load_wordlist() warten muss:
async def pick_word():
global wordlist, word, accept_input
wordlist = await load_wordlist()
word = random.choice(wordlist)
console.log("Wort: ",
" ".join(list(word)))
accept_input = True
Um die asynchronen Funktionen so aufzurufen, dass sie den Code nicht blockieren, kann man einen alten JavaScript-Trick benutzen:
setTimeout(create_proxy(pick_word), 0)
Der Timeout von 0 zwingt den Code nicht zum Warten, bei 0 Millisekunden Verzögerung gibt es aber auch keine Wartezeit. Die Timeout-Funktion sorgt dabei automatisch für eine nebenläufige Ausführung.
Nerdle-HTML
Nerdle benutzt ein Spielbrett aus 30 Quadraten (6 Zeilen mit je 5), die je ein Zeichen aufnehmen. Das geht hervorragend mit einem Grid-Layout. Und da alle Felder gleich aussehen, kann man sie bequem im Quellcode erzeugen. Der fügt alle hintereinander in <div id="board"></div> ein und merkt sich die Divs in einer Liste aus Listen (eine pro Zeile):
tiles=[]
board=document.getElementById("board")
for row in range(6):
tiles.append([])
for col in range(5):
tile=document.createElement("div")
board.appendChild(tile)
tiles[-1].append(tile)
Form und Farbe legt die Datei nerdle-styles.css fest, die Sie zusammen mit dem Rest des Codes im Repository über ct.de/ynk9 finden.
Die Funktionen getElementById() und createElement() funktionieren genau wie in JavaScript, sodass Sie dort die Dokumentation konsultieren können, solange PyScript noch keine eigene dafür hat. Die Funktionen gehören zum document-Objekt, das Sie mit from js import document laden.
Die Tasten der Bildschirmtastatur sind ganz ähnliche <div>, allerdings von Anfang an im HTML. Es gibt einen Unterschied: Das umrahmende <div> hat die ID "keyboard". Der Python-Code kann sich anhand der Beschriftung der Tasten dann selbst ein Dictionary zusammenbauen, das jedem Zeichen das passende DOM-Objekt zuordnet:
key_objects = {}
for row in document.getElementById(
"keyboard").childNodes:
for key in row.childNodes:
key.addEventListener("click",
js_key_clicked)
if len(key.textContent) == 1:
key_objects[
key.textContent] = key
childNodes ist dabei die JavaScript-Datenstruktur NodeList, die aber das Iterator-Interface implementiert, sodass sich damit fast wie mit einer Python-Liste arbeiten lässt. addEventListener() ist die von Python aufrufbare JavaScript-Funktion, die den JavaScript-Function-Pointer js_key_clicked annimmt. Den muss man allerdings etwas umständlich erzeugen.
Verpackte Funktionen
Funktionen definiert man im Python-Code wie üblich mit def. Heraus kommt dabei eine Python-Funktion, die im Python-Code ganz normal funktioniert. Will man aber mit dem DOM interagieren, muss man die von PyScript gekapselten JavaScript-Funktionen benutzen, die man an den Namen in CamelCase erkennt. Diese JavaScript-Funktionen sehen die Python-Funktionen nicht, weshalb man eine Funktionsreferenz beispielsweise nicht einfach an addEventListener() übergeben kann.
Die Sprachbarriere überwindet das pyodide-Modul, das PyScript standardmäßig mitbringt (kein Eintrag in <py-env> nötig).
Mit create_proxy() packt man die Python-Funktion so ein, dass JavaScript sie sehen kann. Die so erzeugte Referenz kann man wie eine JavaScript-Funktion an addEventListener() übergeben.
Dabei funktionieren wiederum alle von JavaScript bekannten Datenstrukturen, sodass die Python-Funktion über den Parameter e das Event-Objekt bekommt. Das verweist unter e.target auf das DOM-Objekt, von dem das Ereignis ausging, und das verrät mit e.target.textContent, was innerhalb des HTML-Tags steht.
Noch ein Hinweis auf eine mögliche Fehlerquelle beim Konvertieren von JavaScript-Code von StackOverflow: Die Python-Funktion muss alle Parameter nennen, die JavaScript übergibt. JavaScript erlaubt es, Parameter still und heimlich wegzulassen, während Python mindestens einen _ verlangt. Man muss die übergebenen Parameter in der Funktion aber nicht benutzen, wenn man sie nicht braucht.
Raten
Nachdem der Code schon ein Wort zum Erraten ausgewählt und das Dictionary mit den Tasten initialisiert ist, muss er nur noch die Eingaben verarbeiten und bei „Enter“ den geratenen Begriff auswerten.
Die aktuelle Eingabe speichert das Programm in der Variable guess. Fürs Verarbeiten der Eingaben macht sich die Funktion key_clicked() den Umstand zunutze, dass alle <div> mit einem Zeichen einen textContent mit Länge 1 haben. Das Backspace-Symbol ist ein SVG, weshalb textContent bei dieser Taste ein leerer String ist. Die Enter-Taste dagegen ist mit „Enter“ beschriftet, also mit fünf Zeichen. Die Fallunterscheidung ist eine gute Gelegenheit, das mit Python 3.10 eingeführte Pattern-Matching einzusetzen:
match len(e.target.textContent):
case 0:
guess = guess[:-1]
case 1:
guess += e.target.textContent
case _:
check_enter()
display_guess()
match…case funktioniert so ähnlich wie switch…case in C, erlaubt aber beispielsweise auch reguläre Ausdrücke hinter case. Statt default: gibt es case _:, der zum Tragen kommt, wenn keiner der anderen Fälle eintrifft. In allen Fällen kümmert sie die Funktion display_guess() darum, den Inhalt von guess auch anzuzeigen. Pattern Matching funktioniert auch mit Objekten, beispielsweise mit re (das Modul für reguläre Ausdrücke) erzeugte Tupel. Ein Beispiel dafür finden Sie im Code auf GitHub.
Die Funktion display_guess() konsultiert die Variable guess_no, die speichert, in welcher Zeile Spieler gerade raten. Zuerst füllt die Funktion überall Leerzeichen ein, um vorherige Eingaben zu löschen:
for i in range(5):
tiles[guess_no][i].textContent = ""
Das Eintragen aller Buchstaben aus guess geht fast genauso einfach, weil Python klaglos mit list() Strings in Listen aus Einzelzeichen verwandelt:
for pos, c in enumerate(list(guess)):
tiles[guess_no][pos].textContent = c
Python kann Tupel automatisch auspacken, wenn man der Anzahl entsprechend viele Variablen mit Komma getrennt hintereinander schreibt. enumerate() gibt für jeden Iterator, also für alles, was sich wie eine Liste behandeln lässt, ein 2-Tupel aus der Nummer und dem Element zurück. Im Beispiel landet in pos also die Nummer des Zeichens und in char das Zeichen. Die Schreibweise, die dabei herauskommt, versteht man ganz intuitiv.
Vergleichen
Bei einem „Enter“ muss das Spiel zunächst prüfen, ob der geratene Begriff fünf Zeichen hat und ob er in der Wortliste steht. Wenn nicht, schreibt die Funktion in das <div> mit der ID "info" eine Fehlermeldung:
pyscript.write("info", f"„{guess}“ " +
"steht nicht in der Wortliste.")
Die Funktion pyscript.write() nimmt einem dabei die Arbeit ab, das DOM-Element mit der ID "info" herauszusuchen und seinen textContent zu ändern. Wir vermuten, dass PyScript in Zukunft noch weitere Funktionen ähnlicher Art bekommt, die DOM-Zugriffe mit weniger Code erlauben.
Außerdem nutzt die Zeile Pythons seit 3.6 verfügbare f-Strings. Die definiert man mit dem Buchstaben f vor den Anführungszeichen und Python ersetzt dann alle in geschweiften Klammern angegebenen Variablen durch deren Werte. Man kann die Ausgabe mit den gleichen Filtern wie in format() beeinflussen.
Steht in guess ein Begriff aus der Wortliste, vergleicht die Funktion evaluate_guess() den geratenen Begriff mit word, dem zu erratenden Begriff. Dafür macht sie den Begriff wieder zu einer Liste, holt sich mit enumerate() die Zeichennummer dazu, die sie dann benutzt, um das Zeichen aus dem zu erratenden Begriff zu ziehen und die Zeichen zu vergleichen:
for p, char in enumerate(list(guess)):
if char == word[p]:
tiles[guess_no][p].classList.add(
"nailedit")
key_objects[char].classList.add(
"nailedit")
correct_counter += 1
Damit Spieler Grün und Gelb sehen, ergänzt die Funktion über classList.add() die passende CSS-Klasse, die die Farbe festlegt. Das passiert sowohl bei den Quadraten im Spielfeld als auch bei der Bildschirmtastatur. Dass die Tasten ihre Farbe verändern, ist eine willkommene Hilfe beim Sinnieren über den nächsten Begriff, den man raten könnte.
Bei richtig geratenen Zeichen zählt die Funktion auch die lokale Variable correct_counter hoch. Steigt die nämlich beim Einfärben aller Zeichen-Quadrate auf 5, ist das Ratespiel gewonnen. Ist die Variable kleiner und zusätzlich guess_no >= 5, ist das Spiel verloren.
Usability
Der vollständige Code, den Sie über das Repository über ct.de/ynk9 finden, enthält noch einige zusätzliche Zeilen. Die dienen der besseren Bedienbarkeit, damit man beispielsweise statt per Bildschirmtastatur auch mit der normalen Tastatur tippen kann. Das geht mit einer key_down()-Funktion, die den onkeydown-Event-Handler von document überschreibt:
Der Code ist mitsamt HTML kaum mehr als 200 Zeilen lang, die bis auf einen regulären Ausdruck leicht zu lesen sind.
Exceptions sind in der Entwicklerkonsole sichtbar, die Browser mit F12 öffnen. Die Darstellung ist leider nicht so übersichtlich, weil PyScript alles in JavaScript-Objekte einpacken muss.
Fürs Debugging lohnt es sich, mit F12 die Entwickler-Konsole zu öffnen. Dort landet auch alles, was Sie mit console.log() ausgeben. Die Fehlermeldungen sind leider nicht gut lesbar, weil es in JavaScript-Exceptions verpackte Python-Exceptions sind. Das müssen die Entwickler noch stark nachbessern.
Eine weitere Baustelle sind die Entwicklungsumgebungen. Beispielsweise erkannte die Entwicklungsumgebung PyCharm den Code in <py-script>-Tags nicht als Python-Quelltext, sodass weder Farben noch Code-Vervollständigung funktionierten.
Spielen
Das selbst programmierte Nerdle starten Sie, indem Sie einfach die Datei index.html im Browser öffnen. Ein Webserver ist dafür nicht notwendig, zum Nachladen des PyScript-Codes und der Wortliste aber eine Internetverbindung. Installieren müssen Sie gar nichts. Falls Sie das Spiel doch mit einem Webserver hosten wollen, muss der nur eine statische Seite ausliefern können.
Unser Worträtsel „Nerdle“ ist wegen der Tech-Begriffe mit Abkürzungen deutlich schwerer als „Wordle“ von der New York Times.
Unsere Liste mit Begriffen finden Sie im Repository in der Datei nerdle-begriffe.txt. Momentan stehen da schon mehr als 1500 Begriffe zum Raten bereit. Mit dem Skript word_list_filter.py können Sie die Liste aber bequem erweitern. Es liest die Datei neue-begriffe.txt, filtert nach den richtigen Zeichen und fragt für alle neuen Begriffe einzeln, ob Sie die hinzufügen wollen. So können Sie mit wenig Arbeit ganze Listen aus Kreuzworträtsel-Datenbanken ergänzen.
Kritik
Wir sind von PyScript begeistert. Python-Code ohne Installation im Browser ausprobieren? Grandios!
Noch ist PyScript aber nicht an dem Punkt angelangt, darauf bestehenden Code zu portieren und über Experimente hinausgehende Projekte damit umsetzen zu wollen. Außerdem muss eine Webseite mit PyScript mehr als 14 Megabyte an Code laden, bevor sie überhaupt starten kann. Danach muss die JavaScript-Engine den WebAssembly-Code zunächst in Bytecode für die Prozessorarchitektur übersetzen, was selbst auf einer schnellen Desktop-CPU fast eine Sekunde dauert. Erst danach läuft der Code der Seite los. Bei normalem JavaScript lädt der Browser nur die winzige Skriptdatei und führt diese sofort aus, weil die JavaScript-Engine längst warm gelaufen ist.
PyScript hat trotz allem sinnvolle Anwendungen: Hat beispielsweise eine Statistikerin ihre Daten schon mit Python ausgewertet und mit Matplotlib ein Diagramm gezeichnet, müsste sie normalerweise alles in JavaScript nachprogrammieren, um das Diagramm in eine Webseite einzubinden. PyScript senkt die Hürde für Pythonisten, mal eben schnell aus einer Idee eine Webanwendung zu basteln – wie unser Beispiel zeigt. (pmk@ct.de)
Code bei GitHub, PyScript-Dokumentation: ct.de/ynk9
iOS: Download die iOS VoIP App aus dem App Store und QR-Code scannen Android: Download die Android VoIP App von Google Play und QR-Code scannen Windows: 3CX Desktop-App Melden Sie sich bei Ihrem Web Client an und klicken Sie auf das Windows-Symbol, um die App zu installieren und bereitzustellen
Schritt 4: Installieren Sie den Live-Chat-Code auf Ihrer Website
Installieren Sie das WordPress-Plugin hier oder generieren Sie Live-Chat zur Verwendung mit jedem CMS. Konfigurieren Sie, welche Agenten Live-Chats und Anrufe annehmen sollen. Konfigurationshandbuch Integrieren Sie Ihre Facebook-Nachrichten mit 3CX. Einrichtungsanleitung
InterNetX Domain Plugin for WHMCS is a registrar module which allows you to offer InterNetX domains to your customers. It also allows complex management of ordered domains from both client area and admin area.Table of contents
automated .CA Registration not working (manual processing via AutoDNS Frontend is possible after the WHMCS order arrived)
automated .HK Registration not working (manual processing via AutoDNS Frontend is possible after the WHMCS order arrived)
Domain OwnerChange for certain TLDs like .EU is not working with WHMCS. (If the OwnerChange is not working with WHMCS the changes can be done manually in the AutoDNS Webinterface.)
Domain Transfer including OwnerChange(TRADE) for certain TLDs like .EU is not working with WHMCS. (If the Domain Transfer including OwnerChange is not working with WHMCS the Trade can be done manually in the AutoDNS Webinterface.)
Installation and Configuration
In this section we will show you how to properly install and configure your InterNetX Domain Plugin for WHMCS.
1. Order the WHMCS Domain Plugin at „Optional Services“ in the AutoDNS customer center. A contract addon is required, after signing you will receive the Plugin by email.
2. Upload files to your server into your root WHMCS directory.
3. Duplicate dist.additionaldomainfields.php file located at the /resources/domains/directory to additionaldomainfields.php and add code below at the end of the file: additionaldomainfields.php
/*** InterNetX REGISTRAR ADDITIONAL PARAMETERS* This file will load proper additional parameters for InterNetX registrar domain module*/$filename = ROOTDIR . DIRECTORY_SEPARATOR . 'resources'. DIRECTORY_SEPARATOR . 'domains'. DIRECTORY_SEPARATOR .'InterNetX_additionaldomainfields.php';if(file_exists($filename)) {include($filename);} else{die('Can not load InterNetX_additionaldomainfields.php File error: resources/domains/dist.additionaldomainfields.php');}
(This will add domain extensions for the domain plugin and will overwrite some of the standard WHMCS extensions that are not required.)
4. Now, you have to set up your contact details. At the Setup > General Settings > Domains. Uncheck „Use Clients Details“ checkbox, fill contact details and press Save Changes.
5. In order to proceed, go to the Setup > Product/Services > Domain Registrars, find InterNetX and press Activate next to it.
6. Now, enter your API access details, API URL and default nameservers.
The default nameservers for AutoDNS are: a/b/c/d.ns14.net
(if you are using virtual nameservers from InterNetX please update /modules/registars/InterNetX/classes/class.InternetX_API.php and change the two „ns14.net“ entries to your own virtual nameserver domain)
Context: The default context for AutoDNS is 4. If you are using Personal AutoDNS please use your exclusive URL and the context number you have received.
Reply To: Defines where the replies of the AutoDNS orders will be sent by email. These emails are required to track orders with errors.
MX Record: Here you can set the default subdomain name for the MX Record. The MX will point to the same IP that is set in „IP Address“. We suggest to use the name webmail .
IP Address: The IP address where the DNS Records that are created during domain registration will point. The IP also defines the MX Record subdomain name supplied above.
Auto Delete: Do not activate this option unless you are instructed to do so! Else the feature will result in double renewals and costs for domains!
Admin Contact: The OwnerC will also be AdminC in the public Whois. Else the Client will only be OwnerC.
→ Afterwards, press Save Changes button.
It is also possible to use the AutoDNS Demo System for testing and implementation, if you need access to the AutoDNS Demo System (Sandbox) please contact sales@internetx.com. The sandbox nameservers are ns1/ns2.demo.autodns.com To use the AutoDNS Demo System please activate „Test Mode“.
Congratulations! You have just finished the initial installation and configuration of the module.
Management
TLD Management
Your clients will be able to order domains as soon as you set up TLDS for your desired extensions.
1. In order to start, go to the Setup > Products/Services > Domain Pricing. 2. Fill TLD, choose additional features like DNS Management and select InterNetX from Auto Registration dropdown menu if you wish a fully automated registration of your client’s orders. Press Save Changes to add this TLD to your system.
Now, it is time to set up pricing. To do so, press Open Pricing in Pricing column. New window will open, please make sure your browser does not block PopUps.
3. Here you can set up pricing for registering, transferring and renewing domains using created TLD. Press Save Changes to finish.
4. Setup of AutoDNS User Profile: In addition you have to set up your AutoDNS User Profile with additional information once.
Go to „User Management“ > „User Configuration“ > „User Profile“ The tabs „IRTP“, „Verification“ and „TMCH“ should show the Reseller’s Company Name and Support email address.
After configuring the TLD and the AutoDNS User Profile you can start ordering the first domain. Go to Client Area and chose Domains > Register a New Domain:
Next to basic actions
Admin area
The InterNetX Domain Plugin for WHMCS allows you to perform various actions on your client’s domains.
In addition to basic actions (Register, Transfer, Renew and Modify Contact Details) you are able to carry out functions such as Get EEP Authinfo Code, Request Delete, Transfer OUT ACK and Transfer Out NACK.
Your client can manage all relevant aspects of their domain. In this section we will show the available features. On the domain’s details page your client can view basic details of his domain and order it’s renewal.
In the Auto Renew tab you are able to enable/disable the Auto Renew functionality.
Important Note:
Disabling Auto Renew will result in an automated deletion of the domain on the expiration date! If you reactivate Auto Renew the delete order will be removed again.
You can also change the domain’s nameservers, this can be done in the Nameservers tab.
At the Addons tab you can manage addons ordered along with a domain.
In the Addons tab you can manage addons ordered along with a domain.
ID Protection allows you to activate and deactivate the Whois Privacy Service.
DNS Host Record Management allows you to manage the DNS Entries for the domain.
Email Forwarding allows you to redirect email addresses to other external email addresses.
The InterNetX Domain Plugin for WHMCS also allows you to modify the whois contact details. The only limitation here is you cannot change the first and last name.
SchlundTech allows you to set up email forwarding if you have.
DNS Management addon enables you to manage the DNS records of your domain.
InterNetX allows to set up email forwarding if you have ordered the InterNetX Redirector service. Please contact sales@internetx.com to get the Redirector service activated.
Important Note:
To activate email forwarding the MX record of the domain must be set to a hostname that points to IP address 62.116.130.8 in the DNS entry!
You can easily receive your domain’s EPP Authinfo Code, simply go to the Management Tool > Get EPP Code.
Additionally, you can easily set up domain forwarding. Go to Management Tools > Manage Domain Forwarding: InterNetX allows to set up domain forwarding if you have ordered the InterNetX Redirector service. Please contact sales@internetx.com to get the Redirector service activated.
Important Note:
The Domain/Subdomain Forwarding requires a change of the A-Record in the DNS entry. Please set the A-Record for the domain/subdomain to the IP Address 62.116.130.8 in order to get Domain Forwarding activated.
You can also change the domain owner.
WhoisProxy
The InterNetX WhoisProxy acts as a singular intermediatery which accesses the various whois servers of the registries, thereby saving users the effort of sending whois queries to every whois server.
A complete list of all available WhoisProxy TLDs can be retrieved using the following command: whois -h whois.autodns3.de tld
Premium Domains
Additional Feature For InterNetX WHMCS Domain Registrar: Premium Domains
The Premium Domains module adds premium domain functionality inside the existing InterNetX WHMCS Domain Registrar module.
Important Note:
The premium domain feature requires using the WhoisProxy!
To use the premium domain function, our WhoisProxy is mandatory.
If the lookup provider is changed, all Whois Queries including non premium Domains, will be executed via the WhoisProxy.
Please contact our Sales Team(sales@internetx.com) to receive access to the WhoisProxy.
Installation instructions
Go to Admin Area of your WHMCS.
Go to Setup > Addon Modules and activate „InterNetX Premium Domains Addon„.
There is no need to configure the addon, just click „Activate“ button.
Go to Setup > Products/Services > Domain Pricing, and change your Lookup Provider to „InterNetX“ by clicking on „Change“ button in „Lookup Provider“ section:
Then select „InterNetX“ from all lookup providers list:
Please make sure that the premium domain button is set to „ON„:
window to allow user enter
Functionalities:
The Premium Domains module allows the user to set his own price for each premium domain class. To do this you have to: Click „Configure“ button in the premium domains section:
The module will change the „Configure Premium Domains Levels“ window to allow the user to enter and save their premium domains classes. Enter premium domain class names inside text fields and save them into database by clicking „Save“ button:
Premium domian classes can also be deleted from the database by clicking on „Delete“ button:
After adding a premium domain class to the database, the user has the possibility to configure it’s pricing by clicking on the „Configure“ button:
In the next window the user can set the Register, Transfer, and Renewal prices for selected price class, and save it into the database by clicking the „Save“ button:
From now on if a premium domain will be detected by the WHMCS Domain Registrar the price will be taken from the database and set in the „Client Area“ during the domain registration process.
Note:
In „Configure Premium Domain Pricing“ the user can only configure pricing for a one year period, because WHMCS does not allow users to register premium domains for longer than one year.
In this same window only one currency is available because WHMCS and the Premium Domains module automatically recalculates prices to other currencies based on the current currency rate.
When a user wants to disable register/renew/transfer prices of domain just type „0“ (zero) in the appropriate premium domain pricing field.
Important note about renew prices:
When you are in the „Client Area“ and go to: Domains > My Domains and click „Renew“ button on the left, the action bar displaying the renew prices of premium domains will not change. WHMCS does not support changing prices in this place.
Additional information about Custom Client Area Forms and Custom Localistation:
Changes to Design and Localisation can be done here, but Localisation should be done by using Language Tags.
Custom Localisation via Language Tags
Your will find language Tags all over WHMCS, we are using separated „internetx“ Language Tags to make it visible who made the localisation
e.g.
$LANG.internetxchangeowner
$LANG.internetxchangeownerdesc
$LANG.clientareasavechanges
$LANG.clientareacancel
Language Tags beginning with „$LANG.internetx“ are located in
/lang/overrides/german.php
/lang/overrides/english.php
These individual Language Tags can be changed as needed.
Other Language Tags like „$LANG.clientareacancel“ without the „internetx“ are WHMCS Language Tags.
They can also be overwritten by inserting $LANG.clientareacancel in /lang/overrides/xxxxx.php
e.g. if you do not like the Button „Cancel“ in your Client Area forms, because the button does not cancel but does undo, you simply can override $LANG.clientareacancel from „Cancel“ to „Undo Changes“ in /lang/overrides/english.php
Localisation of Domain Extensions
Some TLDs require additional data, e.g. a VAT Number or a Passport number.
These Extensions are managed in a separate file and are not translated on purpose:
If you want to translate these extension names you can either create own Language Tags or change it directly in InterNetX_additionaldomainfields.php if you are only offering one single language for your customers.